【Python】笔记第三部分
全系列导航见:Python教程整理
:four_leaf_clover:碎碎念:four_leaf_clover:
Hello米娜桑,这里是英国留学中的杨丝儿。我的博客的关键词集中在算法、机器人、人工智能、数学等等,点个关注吧,持续高质量输出中。
:cherry_blossom:唠嗑QQ群:兔叽的魔术工房 (942848525)
:star:B站账号:杨丝儿今天也在科学修仙(UP主跨站求个关注)
:star2:函数
- 函数用于封装一个特定的功能,表示 一个 功能或者行为。
- 函数是可以重复执行的语句块, 可以重复调用。因此可以提高代码的可重用性和可维护性,使代码层次结构更清晰。
- 函数最本质的思想是将程序的 ‘做’ 和 ‘用’ 拆分。解决了开发过程中 ‘做’ + 多次 ‘用’ 的场景。
- 函数的设计理念:崇尚小而精,拒绝大而全,灵活大于全面。
1 | def 函数名(形参1, 形参2): |
1 | 变量 = 函数名(实参) |
:star:函数注释
1 | def 函数名(形参1: 形参1类型, 形参2: 形参2类型) -> 返回值类型: |
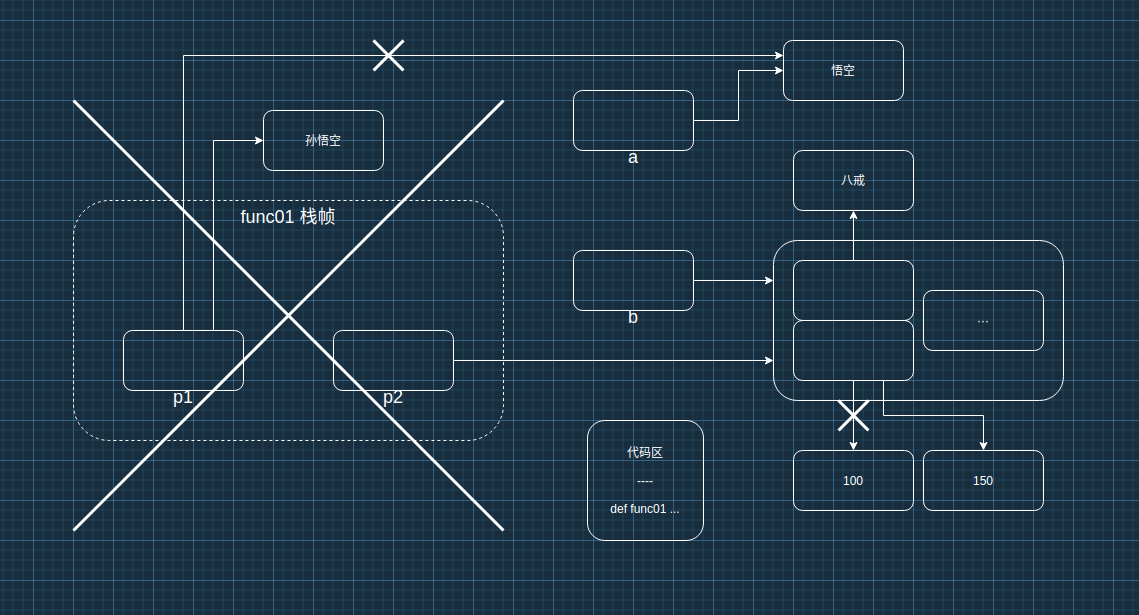
:star:使用内存图理解函数
- 不可变类型的数据传参时,函数内部不会改变原数据的值。
- 可变类型的数据传参时,函数内部可以改变原数据。
:star:补充
除了注释,函数的名字要起的合理,而且要使用动词命名,方便使用时理解函数。
程序的运行是自上而下的,有一个先后顺序,要先定义函数,然后再用。
对于 pycharm 而言,调试时使用快捷键 F8 step over 是不会进入到函数中的,F7 step into 是会进入的。换句话说,F7 会进入到代码的下一层,F8 会跳转到当前层的下一行。
python 的函数是没有重载的必要的,因为 python 并不会对输入的类型和数量进行判断。python 有自己的类似重载的办法。
:star2:函数参数
函数参数有实参和形参两个板块。然后有位置和关键字两种方式。
:star:形参
约束/限制实际参数。
位置形参:实参必填。
2
3
4
5
print(p1, p2, p3)
# func01() # 报错
func01(1, 2, 3) # 1 2 3星号元组形参:自动将多个实参合并为一个元组。只支持位置实参。
2
3
4
5
print(args)
func03() # tuple()
func03(1, 2, 3) # tuple(1,2,3)
默认形参:实参可选,每一个形参有一个默认值。
判定是否为默认形参的依据是是否有默认值。
2
3
4
5
6
print(p1, p2, p3)
func02() # 1 2 3
func02(0) # 0 2 3
func02(p2=0) # 1 0 3双星号元组形参:自动将多个实参合并为一个元组。只支持关键字实参。
2
3
4
5
print(kwargs)
func04() # dict()
func04(p1=1, p2=2) # {'p1': 1, 'p2': 2}
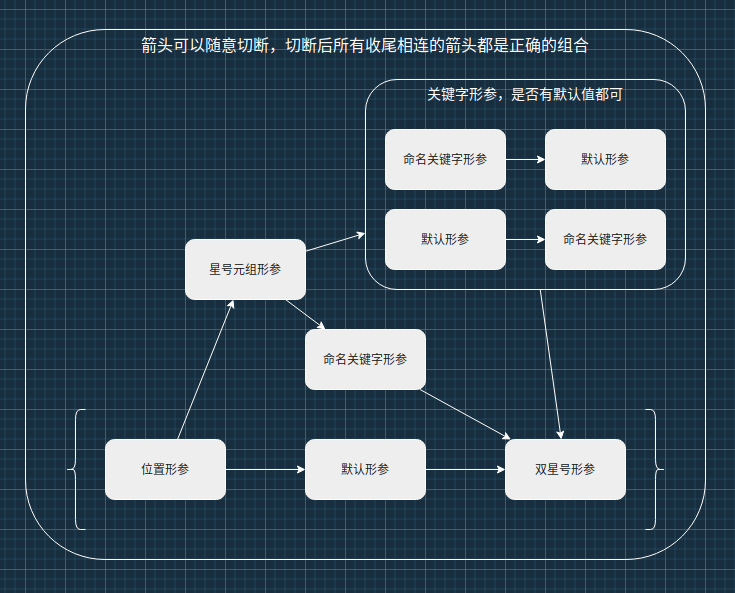
:sparkles:组合在一起
命名关键字形参:输入多个实参后,使用关键字传递参数。
限制函数输入形式,*args 后面的形参必须使用关键字传递参数。
2
3
4
print(args, p3)
func05(1, 2, p3=3) # (1, 2) 0简化上面的代码,可以只保留 * ,仅使用限制函数参数输入形式为关键字的功能。
2
3
4
5
print(p1, p3)
# func06(1,3) # 报错
func06(1, p3=3) # 1 3
参数自左至右的顺序:仅供参考。
2
3
4
print(p1, args, p4, p3, kwargs)
func07(1, 2, 2, p4=4, p5=5) # 1 (2, 2) 4 3 {'p5': 5}
:sparkles:补充
python 的第十种函数参数是 强制位置形参。限制函数输入形式,必须使用位置实参传递参数。
:star:实参
如何与形参对应。
1 | def func01(p1, p2, p3, p4): |
注:接下来的所有例子都会打印 1 2 3 4。
位置实参:实参与形参的位置依次对应。
序列实参:将序列拆分后按顺序与形参进行对应。
2
func01(*itrable_in) # python的解释器在遇到星号时会告诉CPU接下来的变量内的元素是函数参数。
关键字实参:实参根据形参的名字进行对应。
2
func01(p2=2, p1=1, p4=4, p3=3)字典实参:将字典拆分后按名称与形参进行对应。
2
func01(**dict_in)
:sparkles:组合在一起
先位置实参 -> 再关键字实参
先序列实参 -> 再字典实参
2
3
dict_in = {'p3': 3, 'p4': 4}
func01(*itrable_in, **dict_in)先位置 -> 再序列 -> 最后 (关键字 -> 字典) 或 (字典 -> 关键字)
2
3
4
dict_in = {'p4': 4}
func01(1, *itrable_in, **dict_in, p3=3)
func01(1, *itrable_in, p3=3, **dict_in)
:sparkles:补充
注意:内置函数是不兼容关键字实参,一定要用位置实参。
:star2:变量作用域
作用域-LEGB 是变量起作用的范围。
- Local局部作用域:函数内部。
- Enclosing 外部嵌套作用域 :函数嵌套。
- Global全局作用域:模块(.py文件)内部。
- Builtin内置模块作用域:builtins.py文件。
变量名的查找由内到外:L -> E -> G -> B。在访问变量时,先查找本地变量,然后是包裹此函数外部的函数内部的变量,之后是全局变量,最后是内置变量。
:star:Local 局部变量
定义在函数内部的变量(形参也是局部变量)。
局部变量只能在函数内部使用。调用函数时被创建,函数结束后自动销毁。
:star:Global 全局变量
定义在函数外部,模块内部的变量。
在整个模块 py 文件范围内访问,但函数内不能将其直接创建赋值。
:star:global 语句
在函数内部使用 global 创建全局变量,等同于在文件内创建全局变量。
在函数内部修改全局变量。因为在函数内直接为全局变量赋值/修改,视为创建新的局部变量。
当然通过索引定位到了全局变量中的元素再修改是可以的。
1 | global 变量1, 变量2, … |
注意:不能先声明局部的变量,再用global声明为全局变量。
:star:nonlocal 语句
nonlocal 在内层函数修改外层嵌套函数内的变量。
1 | nonlocal 变量名1,变量名2, ... |
相较于 global,nonlocal 是一层一层得使用。
:star2:算法基础
1 | # 变量交换 |
1 | # 循环计数 |
1 | # 计算最值 |
1 | # 冒泡排序 |
1 | # 计数排序 |




