【Python】笔记第二部分
全系列导航见:Python教程整理
:four_leaf_clover:碎碎念:four_leaf_clover:
Hello米娜桑,这里是英国留学中的杨丝儿。我的博客的关键词集中在算法、机器人、人工智能、数学等等,点个关注吧,持续高质量输出中。
:cherry_blossom:唠嗑QQ群:兔叽的魔术工房 (942848525)
:star:B站账号:杨丝儿今天也在科学修仙(UP主跨站求个关注)
在不知道怎么写的时候先不要开始敲代码,可以先把思路写下来。
:star2:容器
| 种类 | 名称 | 存储 | 可变性 | 结构 |
|---|---|---|---|---|
| 字符串 | str | 存储字符编码 | 不可变 | 序列 |
| 列表 | list | 存储变量 | 可变 | 序列 |
| 元组 | tuple | 存储变量 | 不可变 | 序列 |
| 字典 | dict | 存储键*值对 | 可变 | 散列 |
| 集合 | set | 存储键* | 可变 | 散列 |
*注:能充当键的数据必须是不可变数据类型。
:star:容器的操作
:sparkles:数学运算符
+:用于拼接两个容器。
+=:用原容器与右侧容器拼接,并重新绑定变量。
*:重复生成容器元素。
*=:用原容器生成重复元素, 并重新绑定变量。
< <= > >= == !=:依次比较两个容器中元素,一但不同则返回比较结果。
:sparkles:成员运算符
成员运算符:如果在指定的序列中找到值,返回bool类型。
1 | 数据 in 序列 |
:sparkles:索引
索引:定位单个容器元素。
1 | 容器[整数] |
正向索引:从0开始,第二个索引为1,最后一个为len(s)-1。
反向索引:从-1开始,-1代表最后一个,-2代表倒数第二个,以此类推,第一个是-len(s)。
:sparkles:切片
切片:定位多个容器元素。
1 | 容器[开始索引:结束索引:步长] |
前闭后开,结束索引不包含该位置元素。
步长是切片每次获取完当前元素后移动的偏移量。
开始、结束和步长默认值分别为 0,-1,1。
:sparkles:序列拆包
序列拆包:多个变量 = 容器。
1 | a,b,c = tuple03 |
需要变量个数等于容器长度。
:star:str 字符串
由一系列字符组成的不可变序列容器,存储的是字符的编码值。
str 类型的字面值:’ ‘、" “、”“” “”"(三引号,可见即所得)、’‘’ ‘’'。引号冲突的时候可以换着用。
转义字符可以改变字符的原始含义。
1 | \' \" \n \\ \t |
原始字符串:取消转义。
1 | a = r"C:\newfile\test.py" |
:sparkles:%格式化
字符串格式化就是将一个字符串以某种格式显示。占位符/类型码:%s、%f、%d
1 | a = '%s字符串%s' % (str 变量1,str 变量2) # 可以有多个 |
需要注意的是一般来说百分号不需要转义,但如果使用了上面的这个语法,那么百分号是需要转义的,但是格式特殊要用 %%。
:sparkles:f-string格式化
f-string 使用 f 开头,字符串中的表达式用 {} 括起来。表达式是python代码,最后显示的是表达式的返回值。其他的类型码/占位符/格式的描述符放在表达式的冒号:之后。
1 | f'String words and codes {content : format}' |
类型码/占位符/格式的描述符有很多很多,需要查。
:sparkle:f-string格式化 v.s. %格式化
%格式化相较于f-string格式化不够自由。但是%格式化把所有需要填入的信息放到待格式化字符串的后面,在一些时候是更加合适的方式。
1 | # f-string混在一起 |
:star:list 列表
:sparkles:列表的基础知识
由一系列变量组成的可变序列容器。(字符串是不可变的序列容器)
因为存的是变量,变量是一系列相同长度的地址,所以变化地址是允许的。
1 | # 创建 |
只要是容器就有容器的一般操作,也就是索引和定位。因为列表的索引和定位和一般的容器操作相同。
1 | # 查询 |
注意:要做什么操作就用什么方法,不要总是想着另辟蹊径。像是下面这种看上去结果相同的操作,其实是不同的。
1 | list_re = list(range(5)) |
使用for循环遍历列表中的所有元素。
1 | for 变量名 in 容器: |
注意:item 和 i 是不同的,遍历容器的时候使用 item 而在计数循环的时候使用 i / index。
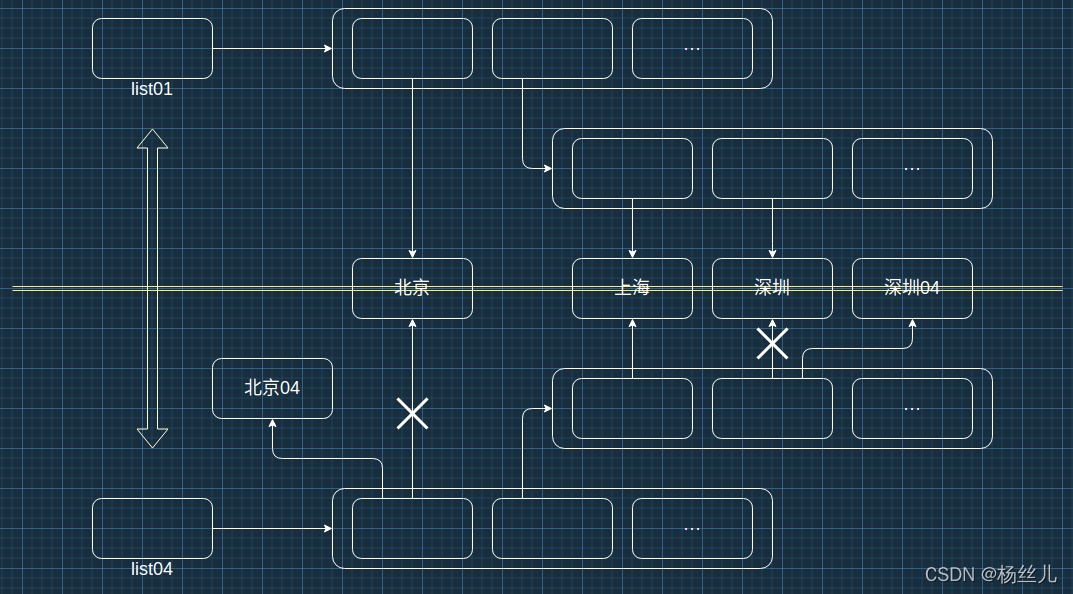
:sparkles:列表的复制操作
拷贝:将一份数据复制、备份为两份,一份意外改变不影响另外一份.
| 浅拷贝 | 深拷贝 |
|---|---|
| 复制第一层数据 | 复制所有层数据 |
| 优点:占用内存较小 | 缺点:占用内存过多 |
| 缺点:深层变化互相影响 | 优点:数据绝对互不影响 |
| 适用性:优先 | 适用性:深层数据会发生改变 |
1 | 新列表名 = 列表名 # 仅仅复制变量的待拷贝列表的地址 |
接下来我们来看几个例子。
1 | list01 = ["北京", "上海", "深圳"] |
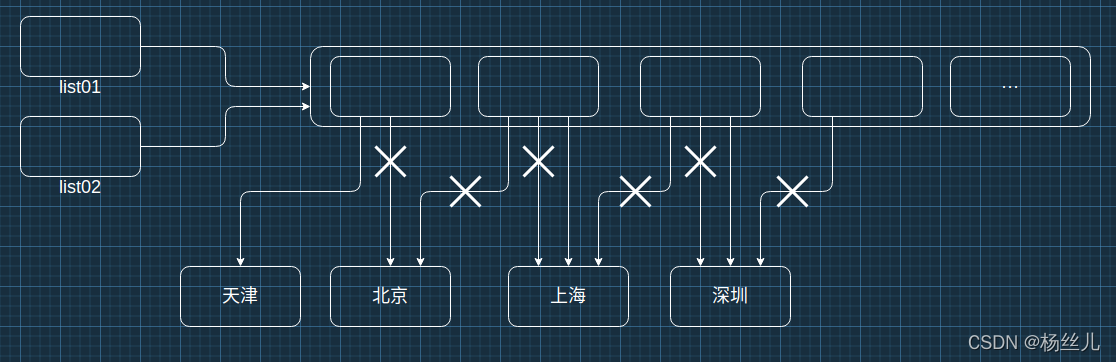
1 | list01 = ["北京", "上海"] |

1 | import copy |
:sparkles:列表推倒式
英文:List Comprehensions
使用简易方法,将可迭代对象转换为列表。
1 | 变量 = [表达式 for 变量 in 可迭代对象] |
如果if真值表达式的布尔值为False,则可迭代对象生成的数据将被丢弃。
:sparkle:补充内容
list -> str: 填充字符串.join(字符串列表)。其他的方法还有很多,但是我们要注意的是内存的使用。
只有把不可变的数据类型构建成可变的数据类型(list),才能解决对不可变数据(str)进行频繁修改会产生大量的垃圾的问题。
str -> list: list_result = "唐僧,孙悟空,八戒".split(",")。使用一个字符串存储多个信息。
:star:元组
由一系列变量组成的 不可变 序列容器。不可变是指一但创建,不可以再添加/删除/修改元素。
1 | # 1. 创建 -- 容器的基本操作 |
:sparkle:可变与不可变讨论
列表和元组最大的区别是内存存储机制的不同,而不是一个可变,一个不可变。
| 列表 | 元组 |
|---|---|
| 预留内存空间 | 空间按需分配 |
| 内存不够时自动扩容 | 每次都要开辟新的空间 |
| 优点:元素可以变化 | 缺点:元素不能变化 |
| 缺点:内存使用过多 | 优点:节省内存空间 |
| 适用性:针对性使用 | 适用性:优先 |
自动扩容:在预留内存空间不够的时候,扩大使用的内存空间。
- 开辟一块更大的内存空间。
- 拷贝原始列表的数据。
- 替换原始列表变量的内存地址。
- 副作用:原来的列表被放弃,成为垃圾。
可变和不可变的分类规则是python中类型的顶层分类。
| 可变 | 不可变 |
|---|---|
| list 就是 可变的 | tuple/int/floar/str/bool 是不可变的 |
| 可变的类型操作灵活,能够方便表达 | 优先使用不可变的,因为占位空间小 |
注意:元组不能像是列表一样直接使用[ ]推倒式,因为 for 的部分会被当做一个生成器,作为元组的一个元素。如果要使用推倒式类似的形式,我们可以用tuple转型,即 tuple( xxx for x in xxx),把生成器对象转型为元组。
:star:字典
由一系列 键值对 组成的 可变 散列 容器。
散列:对键进行哈希运算,确定在内存中的存储位置,每条数据存储无先后顺序。
| 序列 | 散列 |
|---|---|
| 有顺序 | 没有顺序 |
| 占用空间小 | 占用空间大 |
| 支持索引切片 | 定位迅速 |
键必须唯一且不可变(字符串/数字/元组),值没有限制。
1 | # 创建字典 |
注意:字典不能使用索引和切片操作。
因为字典是根据哈希运算的结果进行存储的,是一种用空间换时间的设计理念。所以在索引的时候相较于其他的容器,字典是 最快的。
列表适合储存单一维度的数据,当我们要存储多维度的数据时,我们可以使用字典。
字典推倒式和列表推倒式类似,使用花括号 { } 里面是带冒号的 for 循环。
1 | ks = list_ks |
:star:集合
由一系列不重复的不可变类型变量(元组/数/字符串)组成的可变散列容器。
相当于只有键没有值的字典(键则是集合的数据)。
集合可以去重,而且相较于使用 in 遍历判断,效率极高。哈希计算内存位置,直接判断重复。
1 | # 创建 |
集合的数学运算,交集并集补集:
(1) 交集
&:返回共同元素。
2
3
s2 = {2, 3, 4}
s3 = s1 & s2 # {2, 3}(2) 并集
|:返回不重复元素
2
3
s2 = {2, 3, 4}
s3 = s1 | s2 # {1, 2, 3, 4}(3) 补集
^:返回不同的的元素
2
3
s2 = {2, 3, 4}
s3 = s1 ^ s2 # {1, 4} 等同于(s1-s2 | s2-s1)(3) 差
-:返回只属于其中之一的元素
2
3
s2 = {2, 3, 4}
s1 - s2 # {1} 属于s1但不属于s2
判断两个集合之间的关系:
(1) 子集
<:判断一个集合的所有元素是否完全在另一个集合中(2) 超集
>:判断一个集合是否具有另一个集合的所有元素
2
3
4
s2 = {2, 3}
s2 < s1 # True
s1 > s2 # True(3) 相同或不同
==!=:判断集合中的所有元素是否和另一个集合相同。
2
3
4
s2 = {3, 2, 1}
s1 == s2 # True
s1 != s2 # False
:star2:编码
容器中的数据是不可变的。因为在原有基础上修改,有可能破坏其他数据的内存空间。变量可以变化其中的指向信息,原因是地址是固定长度的,不会干扰相邻的数据。
:star:基础编码
- 字节byte:计算机最小存储单位,等于8 位bit.
- 字符:单个的数字,文字与符号。
- 字符集(码表):存储字符与二进制序列的对应关系。
- 编码
ord(字符):将字符转换为对应的二进制序列的过程。 - 解码
chr(编码):将二进制序列转换为对应的字符的过程。
:star:编码方式
- ASCII编码:包含英文、数字等字符,每个字符1个字节。
- GBK编码:兼容ASCII编码,包含21003个中文;英文1个字节,汉字2个字节。
- Unicode字符集:国际统一编码,旧字符集每个字符2字节,新字符集4字节。
- UTF-8编码:Unicode的存储与传输方式,英文1字节,中文3字节。
:star2:注意
- 代码密度太大会降低代码的复用性,会使功能添加有困难。
- 在商业项目的时候该加判断就要加判断,防止程序出问题。



