结论放前面:
- 现阶段最强的是 YOLOX,代码已开源
- YOLO最开始很简单,v2v3提供了一定的优化,v4猛堆料,v5优化了内存。
YOLO 特点
| yolo | 其他 |
|---|---|
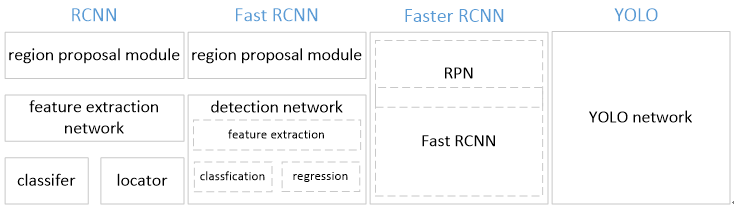
| YOLO训练和检测均是在一个 单独网络中 进行。 | RCNN采用分离模块。包括之后的 Faster RCNN |
| YOLO将物体检测作为一个 回归问题 进行求解,输入图像经过一次inference,便能得到图像中所有 物体的位置 和其 所属类别 及相应的 置信概率 。 | 而rcnn/fast rcnn/faster rcnn将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)。 |
优势
- 速度快。YOLO将物体检测作为回归问题进行求解,速度比其他模型快。
- 背景误检率低。YOLO在训练和推理过程中能‘看到’整张图像的整体信息。
- 通用性强。YOLO对于艺术类作品中的物体检测同样适用。它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。
问题
- 相较于其他方法,YOLO识别物体位置精准性差。
- 召回率较低,会识别不出来物体。
YOLO 模型设计
- YOLO检测网络包括24个卷积层和2个全连接层。
- 借鉴了GoogLeNet分类网络结构,不同的是,YOLO未使用inception module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
- 除此之外还有一个更轻快的检测网络fast YOLO,它只有9个卷积层和2个全连接层。
YOLO 原理
若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。
TODO 怎样检测落物体落入格子?
TODO 怎样计算confidence?

YOLO 模型的缺陷
当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷。
改进:YOLO9000
YOLO9000 使用 YOLOv2 模型,采用联合训练算法训练,拥有9000类的分类信息。
联合训练算法的基本思路就是:同时在检测数据集和分类数据集上训练物体检测器(Object Detectors ),用检测数据集的数据学习物体的准确位置,用分类数据集的数据来增加分类的类别量、提升健壮性。
- 效果:相比YOLO,YOLO9000在识别种类、精度、速度、和定位准确性等方面都有大大提升。
- 设计进步:引入了faster rcnn中 anchor box(使用先验框),在每个grid预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度,这些先验框作为预定义的候选区在神经网络中将检测其中是否存在对象,以及微调边框的位置。
- Dimension clusters(聚类提取先验框的尺度信息)之前Anchor Box的尺寸是手动选择的,所以尺寸还有优化的余地。YOLO2尝试统计出更符合样本中对象尺寸的先验框,这样就可以减少网络微调先验框到实际位置的难度。YOLO2的做法是对训练集中标注的边框进行K-mean聚类分析,以寻找尽可能匹配样本的边框尺寸。
- 采用了新提出的 Batch Normalization(批量归一化)
- High resolution classifier(高分辨率图像分类器)在采用 224*224 图像进行分类模型预训练后,再采用 448*448 的高分辨率样本对分类模型进行微调(10个epoch),使网络特征逐渐适应 448*448 的分辨率。然后再使用 448*448 的检测样本进行训练,缓解了分辨率突然切换造成的影响。
- Fine-Grained Features(passthrough层检测细粒度特征)
- Multi-ScaleTraining(多尺度图像训练)
- hi-res detector(高分辨率图像的对象检测)
- 数据集进步:使用WordTree实现 coco物体检测标注数据(80种物体) 和 imagenet物体分类标注数据(9000种物体) 的融合。
- TODO 模型修改:输出层使用 卷积层 替代YOLO的全连接层。是这样吗?
改进:YOLOv3
- 多尺度预测 (引入FPN)。
- 更好的基础分类网络(darknet-53, 类似于ResNet引入残差结构)。
- 分类器不在使用Softmax,分类损失采用binary cross-entropy loss(二分类交叉损失熵)
YOLOv3不使用Softmax对每个框进行分类,主要考虑因素有两个:
- Softmax使得每个框分配一个类别(score最大的一个),而对于Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类。
- Softmax可被独立的多个logistic分类器替代,且准确率不会下降。
改进:YOLOv4
YOLOv4的特点是集大成者,俗称堆料。但最终达到这么高的性能,一定是不断尝试、不断堆料、不断调参的结果,给作者点赞。
可以参考的学习资料:
改进:YOLOv5
注:命名存争议。内存优化,效果略微强于v4。
公布的结果表明,YOLOv5 的表现要优于谷歌开源的目标检测框架 EfficientDet,尽管 YOLOv5 的开发者没有明确地将其与 YOLOv4 进行比较,但他们却声称 YOLOv5 能在 Tesla P100 上实现 140 FPS 的快速检测;相较而言,YOLOv4 的基准结果是在 50 FPS 速度下得到的,参阅:官方博客
不仅如此,他们还提到「YOLOv5 的大小仅有 27 MB。」对比一下:使用 darknet 架构的 YOLOv4 有 244 MB。这说明 YOLOv5 实在特别小,比 YOLOv4 小近 90%。这也太疯狂了!而在准确度指标上,「YOLOv5 与 YOLOv4 相当」。
YOLOv5的优点
- 使用Pytorch框架,对用户非常友好,能够方便地训练自己的数据集,相对于YOLO V4采用的Darknet框架,Pytorch框架更容易投入生产。
- 代码易读,整合了大量的计算机视觉技术,非常有利于学习和借鉴。
- 不仅易于配置环境,模型训练也非常快速,并且批处理推理产生实时结果。
- 能够直接对单个图像,批处理图像,视频甚至网络摄像头端口输入进行有效推理。
- 能够轻松的将Pytorch权重文件转化为安卓使用的ONXX格式,然后可以转换为OPENCV的使用格式,或者通过CoreML转化为IOS格式,直接部署到手机应用端。
- 最后YOLO V5s高达140FPS的对象识别速度令人印象非常深刻,使用体验非常棒。
最新改进:YOLOX
旷视提出YOLOX:新一代实时目标检测网络
其中YOLOX-L版本以 68.9 FPS 的速度在 COCO 上实现了 50.0% AP,比 YOLOv5-L 高出 1.8% AP!还提供了支持 ONNX、TensorRT、NCNN 和 Openvino 的部署版本。代码刚刚开源!
学习资料:
补充
2020年2月YOLO之父Joseph Redmon宣布退出计算机视觉研究领域,2020 年 4 月 23 日YOLOv4 发布,2020 年 6 月 10 日YOLOv5发布。
参考
- https://zhuanlan.zhihu.com/p/25236464
- https://blog.csdn.net/lemonbit/article/details/109281590
- 封面图片








