@ 作者:达内 Python 教学部,吕泽
@ 编辑:博主,Discover304
:star2:网络并发模型
:star:网络并发模型概述
- 什么是网络并发
在实际工作中,一个服务端程序往往要应对多个客户端同时发起访问的情况。如果让服务端程序能够更好的同时满足更多客户端网络请求的情形,这就是并发网络模型。
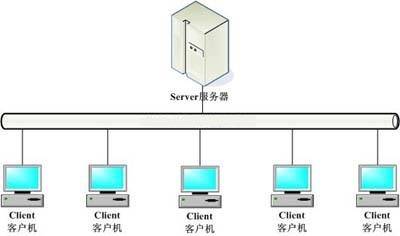
- 循环网络模型问题
循环网络模型只能循环接收客户端请求,处理请求。同一时刻只能处理一个请求,处理完毕后再处理下一个。这样的网络模型虽然简单,资源占用不多,但是无法同时处理多个客户端请求就是其最大的弊端,往往只有在一些低频的小请求任务中才会使用。
:star:多进程/线程并发模型
多进程/线程并发模中每当一个客户端连接服务器,就创建一个新的进程/线程为该客户端服务,客户端退出时再销毁该进程/线程,多任务并发模型也是实际工作中最为常用的服务端处理模型。
-
模型特点
- 优点:能同时满足多个客户端长期占有服务端需求,可以处理各种请求。
- 缺点: 资源消耗较大
- 适用情况:客户端请求较复杂,需要长时间占有服务器。
-
创建流程
- 创建网络套接字
- 等待客户端连接
- 有客户端连接,则创建新的进程/线程具体处理客户端请求
- 主进程/线程继续等待处理其他客户端连接
- 如果客户端退出,则销毁对应的进程/线程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| """
基于多进程的网络并发模型
重点代码 !!
创建tcp套接字
等待客户端连接
有客户端连接,则创建新的进程具体处理客户端请求
父进程继续等待处理其他客户端连接
如果客户端退出,则销毁对应的进程
"""
from socket import *
from multiprocessing import Process
import sys
HOST = "0.0.0.0"
PORT = 8888
ADDR = (HOST, PORT)
def handle(connfd):
while True:
data = connfd.recv(1024)
if not data:
break
print(data.decode())
connfd.close()
def main():
tcp_socket = socket()
tcp_socket.bind(ADDR)
tcp_socket.listen(5)
print("Listen the port %d"%PORT)
while True:
try:
connfd, addr = tcp_socket.accept()
print("Connect from", addr)
except KeyboardInterrupt:
tcp_socket.close()
sys.exit("服务结束")
p = Process(target=handle, args=(connfd,),daemon=True)
p.start()
if __name__ == '__main__':
main()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
"""
基于多线程的网络并发模型
重点代码 !!
思路: 网络构建 线程搭建 / 具体处理请求
"""
from socket import *
from threading import Thread
class Handle:
def request(self, data):
print(data)
class ThreadServer(Thread):
def __init__(self, connfd):
self.connfd = connfd
self.handle = Handle()
super().__init__(daemon=True)
def run(self):
while True:
data = self.connfd.recv(1024).decode()
if not data:
break
self.handle.request(data)
self.connfd.close()
class ConcurrentServer:
"""
提供网络功能
"""
def __init__(self, *, host="", port=0):
self.host = host
self.port = port
self.address = (host, port)
self.sock = self.__create_socket()
def __create_socket(self):
tcp_socket = socket()
tcp_socket.bind(self.address)
return tcp_socket
def serve_forever(self):
self.sock.listen(5)
print("Listen the port %d" % self.port)
while True:
connfd, addr = self.sock.accept()
print("Connect from", addr)
t = ThreadServer(connfd)
t.start()
if __name__ == '__main__':
server = ConcurrentServer(host="0.0.0.0", port=8888)
server.serve_forever()
|
:star:IO并发模型
:sparkles:IO概述
在程序中存在读写数据操作行为的事件均是IO行为,比如终端输入输出 ,文件读写,数据库修改和网络消息收发等。
程序分类
- IO密集型程序:在程序执行中有大量IO操作,而运算操作较少。消耗cpu较少,耗时长。
- 计算密集型程序:程序运行中运算较多,IO操作相对较少。cpu消耗多,执行速度快,几乎没有阻塞。
:sparkles:IO分类
阻塞IO
- 定义:在执行IO操作时如果执行条件不满足则阻塞。阻塞IO是IO的默认形态。
- 效率:阻塞IO效率很低。但是由于逻辑简单所以是默认IO行为。
- 阻塞情况
- 因为某种执行条件没有满足造成的函数阻塞
e.g. accept input recv
- 处理IO的时间较长产生的阻塞状态
e.g. 网络传输,大文件读写
非阻塞IO
- 定义 :通过修改IO属性行为,使原本阻塞的IO变为非阻塞的状态。
设置套接字为非阻塞IO
1
2
3
| sock.setblocking(bool)
功能:设置套接字为非阻塞IO
参数:默认 bool 为 True,表示套接字IO阻塞;设置为False则套接字IO变为非阻塞
|
超时检测 :设置一个最长阻塞时间,超过该时间后则不再阻塞等待。
1
2
3
| >sock.settimeout(sec)
>功能:设置套接字的超时时间
>参数:设置的时间
|
IO多路复用
- 定义
同时监控多个IO事件,当哪个IO事件准备就绪就执行哪个IO事件。以此形成可以同时处理多个IO的行为,避免一个IO阻塞造成其他IO均无法执行,提高了IO执行效率。
- 演示
在同一个线程里面, 通过拨开关的方式,来同时传输多个I/O流
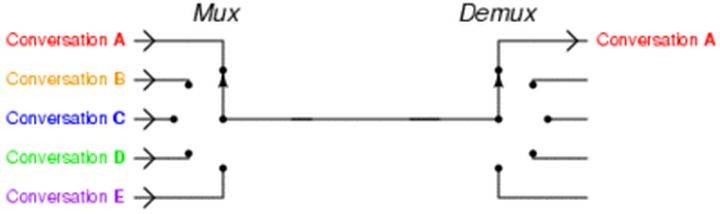
- 具体方案
select 方法:支持 Windows Linux Unix
1
2
3
4
5
6
7
8
9
10
| rs, ws, xs=select(rlist, wlist, xlist[, timeout])
功能: 监控IO事件,阻塞等待任意一IO发生
参数: rlist 列表 读IO列表,添加等待发生的或者可读的IO事件
wlist 列表 写IO列表,存放要可以主动处理的或者可写的IO事件
xlist 列表 异常IO列表,存放出现异常要处理的IO事件
timeout 超时时间
返回值: rs 列表 rlist中准备就绪的IO对象
ws 列表 wlist中准备就绪的IO对象
xs 列表 xlist中准备就绪的IO对象
|
epoll方法:仅支持 Linux
1
2
3
| ep = select.epoll()
功能 : 创建epoll对象
返回值: epoll对象
|
1
2
3
4
5
6
7
8
9
10
11
12
| ep.register(fd,event)
功能: 注册关注的IO事件
参数:fd 要关注的IO
event 要关注的IO事件类型
常用类型EPOLLIN 读IO事件(rlist)
EPOLLOUT 写IO事件 (wlist)
EPOLLERR 异常IO (xlist)
e.g. ep.register(sockfd,EPOLLIN|EPOLLERR)
ep.unregister(fd)
功能:取消对IO的关注
参数:IO对象或者IO对象的fileno()
|
1
2
3
4
5
| events = ep.poll()
功能: 阻塞等待监控的IO事件发生
返回值: 返回发生的IO
events格式 [(fileno,event),()....]
每个元组为一个就绪信息,元组第一项是该IO对象的fileno(),第二项为该IO对象的事件类型
|
select 方法与epoll方法对比
- epoll 效率比select要高
- epoll 同时监控IO数量比select要多
- epoll 支持EPOLLET触发方式
为什么多路复用后的代码最好都是无阻塞的呢?
根本原因是存在虚假的就绪状态,这种虚假的就绪状态可能是由于系统层的错误导致的。如果接下执行虚假就绪状态的任务是阻塞的,那么就会被阻塞。
比方说我们有一个输入值,但因为输入了无效字符,系统层报错,输入被丢弃。但是应用层已经被通知就绪了,开始执行了接下来的任务(主要是监控的IO任务)。在运行到需要输入值的部分时,如果是不是非阻塞的,那么因为输入已经丢失,这一部分代码就会被阻塞了。
:sparkles:IO并发模型
利用IO多路复用等技术,同时处理多个客户端IO请求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
"""
基于select的并发服务模型
使用函数完成
"""
from select import select
from socket import *
HOST = "0.0.0.0"
PORT = 8888
ADDR = (HOST,PORT)
rlist = []
wlist = []
xlist = []
def connect_client(sock):
connfd, addr = sock.accept()
print("Connect from", addr)
connfd.setblocking(False)
rlist.append(connfd)
def handle_client(connfd):
data = connfd.recv(1024)
if not data:
rlist.remove(connfd)
connfd.close()
return
print(data.decode())
connfd.send(b"Thanks")
def main():
sock = socket()
sock.bind(ADDR)
sock.listen(3)
sock.setblocking(False)
rlist.append(sock)
while True:
rs,ws,xs = select(rlist,wlist,xlist)
for r in rs:
if r is sock:
connect_client(r)
else:
handle_client(r)
if __name__ == '__main__':
main()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
"""
基于epoll的并发服务模型
使用类实现
"""
from select import *
from socket import *
class EpollServer:
def __init__(self, host="", port=0):
self.host = host
self.port = port
self.address = (host, port)
self.sock = self._create_socket()
self.ep = epoll()
self.map = {}
def _create_socket(self):
sock = socket()
sock.bind(self.address)
sock.setblocking(False)
return sock
def _connect_client(self, fd):
connfd, addr = self.map[fd].accept()
print("Connect from", addr)
connfd.setblocking(False)
self.ep.register(connfd, EPOLLIN | EPOLLET)
self.map[connfd.fileno()] = connfd
def _handle_client(self, fd):
data = self.map[fd].recv(1024)
if not data:
self.ep.unregister(fd)
self.map[fd].close()
del self.map[fd]
return
print(data.decode())
self.map[fd].send(b"Thanks")
def serve_forever(self):
self.sock.listen(3)
print("Listen the port %d" % self.port)
self.ep.register(self.sock, EPOLLIN)
self.map[self.sock.fileno()] = self.sock
while True:
events = self.ep.poll()
for fd, event in events:
if fd == self.sock.fileno():
self._connect_client(fd)
elif event == EPOLLIN:
self._handle_client(fd)
if __name__ == '__main__':
ep = EpollServer(host="0.0.0.0", port=8888)
ep.serve_forever()
|
:star2:web服务
:star:HTTP协议
:sparkles:协议概述
- 用途 : 网页获取,数据的传输
- 特点
- 应用层协议,使用tcp进行数据传输
- 简单,灵活,很多语言都有HTTP专门接口
- 有丰富的请求类型
- 可以传输的数据类型众多
:sparkles:网页访问流程
- 客户端(浏览器)通过tcp传输,发送http请求给服务端
- 服务端接收到http请求后进行解析
- 服务端处理请求内容,组织响应内容
- 服务端将响应内容以http响应格式发送给浏览器
- 浏览器接收到响应内容,解析展示
:sparkles:HTTP请求

-
请求行 : 具体的请求类别和请求内容
1
2
| GET / HTTP/1.1
请求类别 请求内容 协议版本
|
请求类别说明了请求类别表示要做的事情
1
2
3
4
5
| GET : 获取网络资源
POST :提交一定的信息,得到反馈
HEAD : 只获取网络资源的响应头
PUT : 更新服务器资源
DELETE : 删除服务器资源
|
-
请求头:对请求的进一步解释和描述
-
空行
-
请求体: 请求参数或者提交内容
:sparkles:HTTP响应
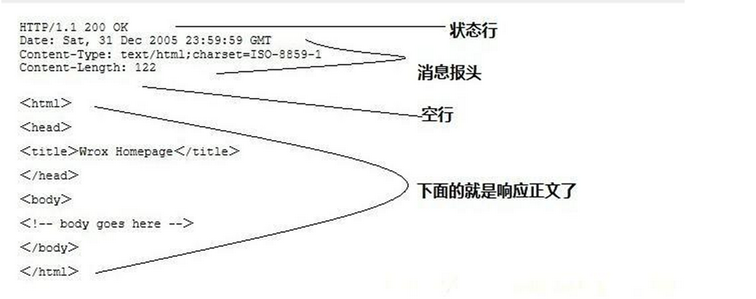
-
响应行 : 反馈基本的响应情况
1
2
| HTTP/1.1 200 OK
版本信息 响应码 附加信息
|
响应码根据开头数字不同有以下几种分类
1
2
3
4
5
| 1xx 提示信息,表示请求被接收
2xx 响应成功
3xx 响应需要进一步操作,重定向
4xx 客户端错误
5xx 服务器错误
|
-
响应头:对响应内容的描述
-
空行
-
响应体:响应的主体内容信息
:star:web 服务程序实现
- 主要功能 :
- 接收客户端(浏览器)请求
- 解析客户端发送的请求
- 根据请求组织数据内容
- 将数据内容形成http响应格式返回给浏览器
- 特点 :
- 采用IO并发,可以满足多个客户端同时发起请求情况
- 通过类接口形式进行功能封装
- 做基本的请求解析,根据具体请求返回具体内容,同时可以满足客户端的网页效果加载
:star2:高并发技术探讨
:star:高并发问题
-
衡量高并发的关键指标
- 响应时间(Response Time) : 接收请求后处理的时间
- 同时在线用户数量:同时连接服务器的用户的数量
- 每秒查询率QPS(Query Per Second): 每秒接收请求的次数
- 每秒事务处理量TPS(Transaction Per Second):每秒处理请求的次数(包含接收,处理,响应)
- 吞吐量(Throughput): 响应时间+QPS+同时在线用户数量
-
多大的并发量算是高并发
- 没有最高,只要更高
比如在一个小公司可能QPS2000+就不错了,在一个需要频繁访问的门户网站可能要达到QPS5W+
- C10K问题
早先服务器都是单纯基于进程/线程模型的,新到来一个TCP连接,就需要分配1个进程(或者线程)。而进程占用操作系统资源多,一台机器无法创建很多进程。如果是C10K就要创建1万个进程,那么单机而言操作系统是无法承受的,这就是著名的C10k问题。创建的进程线程多了,数据拷贝频繁, 进程/线程切换消耗大, 导致操作系统崩溃,这就是C10K问题的本质!
:star:更高并发的实现
为了解决C10K问题,现在高并发的实现已经是一个更加综合的架构艺术。涉及到进程线程编程,IO处理,数据库处理,缓存,队列,负载均衡等等,这些我们在后面的阶段还会学习。此外还有硬件的设计,服务器集群的部署,服务器负载,网络流量的处理等。
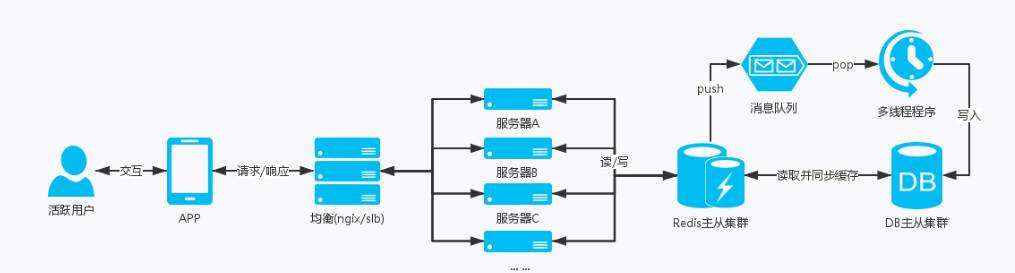
实际工作中,应对更庞大的任务场景,网络并发模型的使用有时也并不单一。比如多进程网络并发中每个进程再开辟线程,或者在每个进程中也可以使用多路复用的IO处理方法。




