@ 作者:达内 Python 教学部,吕泽
@ 编辑:博主,Discover304
:star2:多任务概述
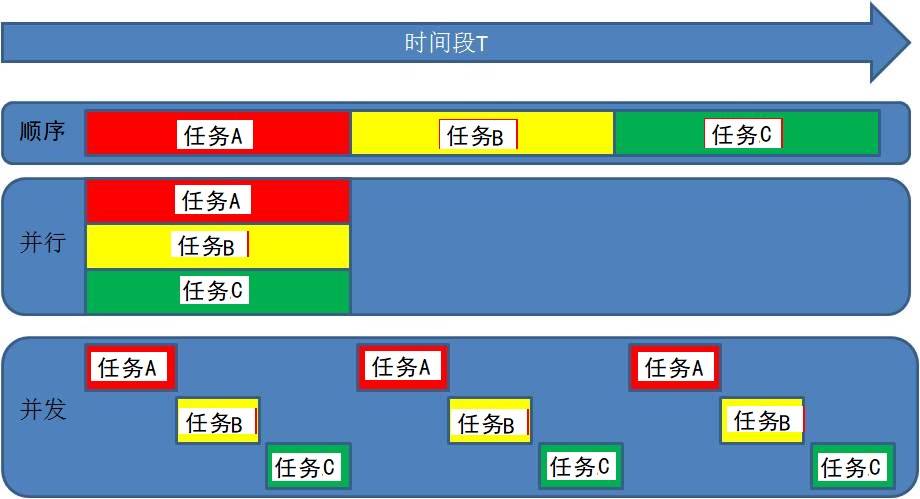
- 多任务
即操作系统中可以同时运行多个任务。比如我们可以同时挂着qq,听音乐,同时上网浏览网页。这是我们看得到的任务,在系统中还有很多系统任务在执行,现在的操作系统基本都是多任务操作系统,具备运行多任务的能力。 - 什么是多任务编程
多任务编程即一个程序中编写多个任务,在程序运行时让这多个任务一起运行,而不是一个一个的顺次执行。
比如微信视频聊天,这时候在微信运行过程中既用到了视频任务也用到了音频任务,甚至同时还能发消息。这就是典型的多任务。而实际的开发过程中这样的情况比比皆是。- 实现多任务编程的方法 : 多进程编程,多线程编程
- 多任务意义
- 提高了任务之间的配合,可以根据运行情况进行任务创建。
比如: 你也不知道用户在微信使用中是否会进行视频聊天,总不能提前启动起来吧,这是需要根据用户的行为启动新任务。 - 充分利用计算机资源,提高了任务的执行效率。
- 提高了任务之间的配合,可以根据运行情况进行任务创建。
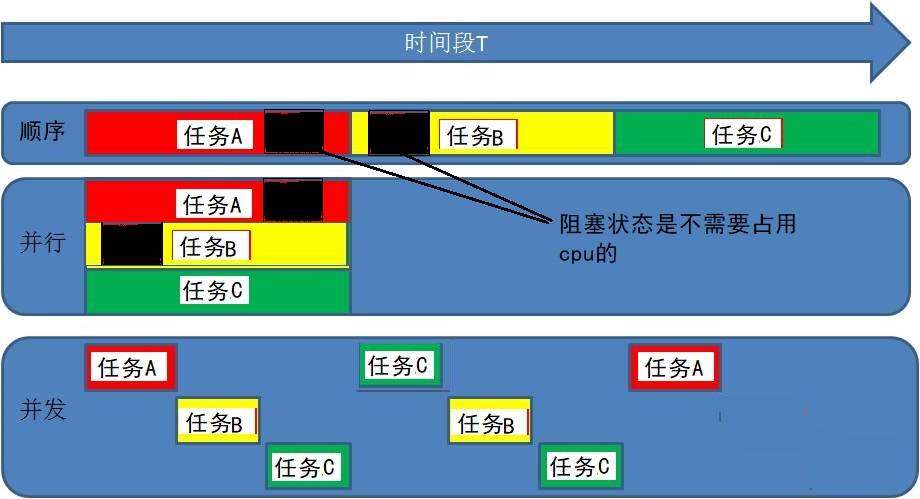
- 在任务中无阻塞时只有并行状态才能提高效率
- 在任务中有阻塞时并行并发都能提高效率
计算机原理
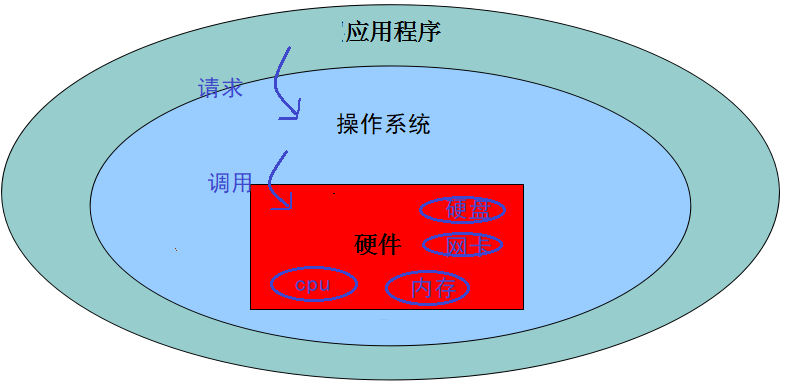
- CPU:计算机硬件的核心部件,用于对任务进行执行运算。
- 操作系统调用CPU执行任务
- cpu轮询机制 : cpu都在多个任务之间快速的切换执行,切换速度在微秒级别,其实cpu同时只执行一个任务,但是因为切换太快了,从应用层看好像所有任务同时在执行。
- 多核CPU:现在的计算机一般都是多核CPU,比如四核,八核,我们可以理解为由多个单核CPU的集合。这时候在执行任务时就有了选择,可以将多个任务分配给某一个cpu核心,也可以将多个任务分配给多个cpu核心,操作系统会自动根据任务的复杂程度选择最优的分配方案。
- 并发 : 多个任务如果被分配给了一个cpu内核,那么这多个任务之间就是并发关系,并发关系的多个任务之间并不是真正的"同时"。
- 并行 : 多个任务如果被分配给了不同的cpu内核,那么这多个任务之间执行时就是并行关系,并行关系的多个任务时真正的“同时”执行。


:star2:进程 v.s. 线程
| 进程 | 线程 |
| 都是多任务编程方式 | |
| 都能使用计算机的多核资源 | |
| 空间独立,数据互不干扰,有专门的通信方法 | 使用全局变量通信 |
| 一个进程可以有多个分支线程,两者有包含关系 | |
| 多个线程共享进程资源,往往需要同步互斥处理 | |
| 不存在GIL问题 | 存在GIL问题 |
| 一个项目可能有多个进程 | 一个进程有多个线程 |
| Python由于GIL问题往往使用多进程 | Java,C#之类的编程语言在执行多任务时一般都是用线程完成,因为线程资源消耗少 |
:star2:进程(Process)
:star:进程概述
- 定义: 程序在计算机中的一次执行过程。
- 程序是一个可执行的文件,是静态的占有磁盘。
- 进程是一个动态的过程描述,占有计算机运行资源,有一定的生命周期。

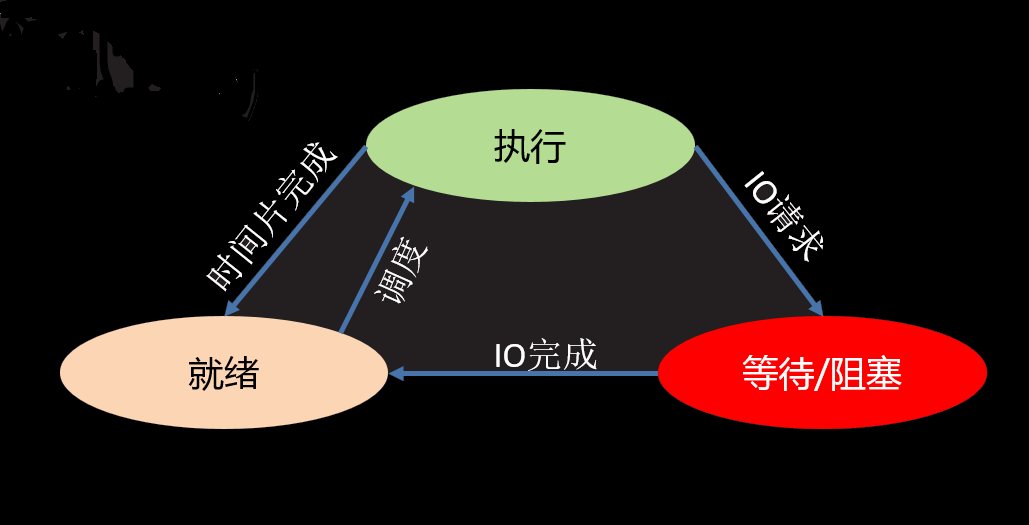
- 进程状态
- 三态
就绪态 : 进程具备执行条件,等待系统调度分配cpu资源
运行态 : 进程占有cpu正在运行
等待态 : 进程阻塞等待,此时会让出cpu
- 五态 (在三态基础上增加新建和终止)
新建 : 创建一个进程,获取资源的过程
终止 : 进程结束,释放资源的过程
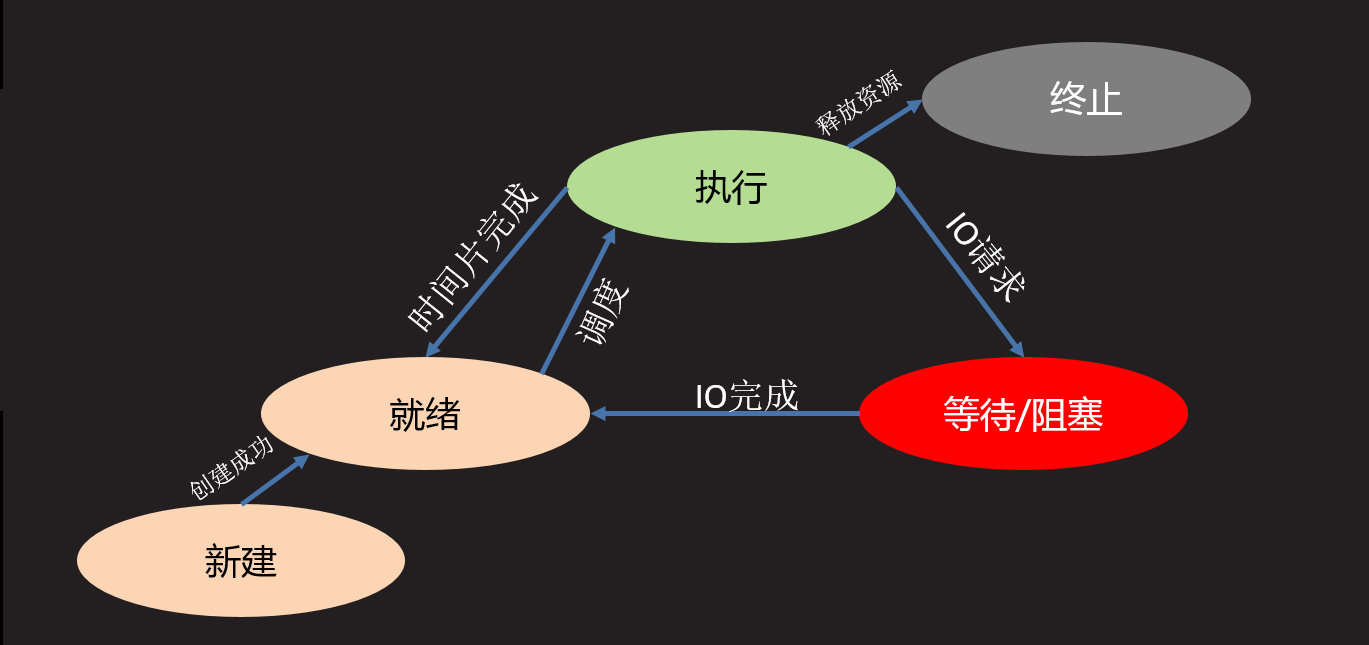
- 三态
- 进程命令
- 查看进程信息
1
ps -aux
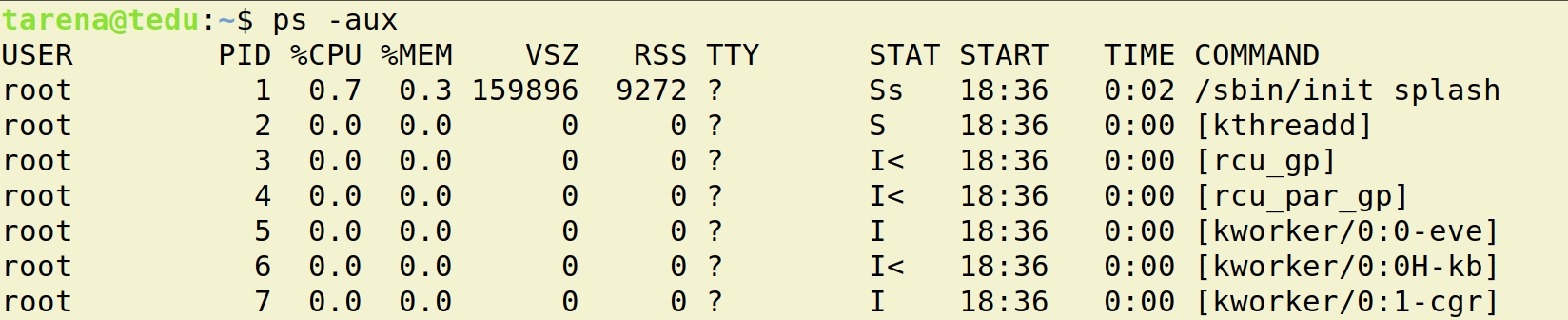
- USER : 进程的创建者
- PID : 操作系统分配给进程的编号,大于0的整数,系统中每个进程的PID都不重复。PID也是重要的区分进程的标志。
- %CPU,%MEM : 占有的CPU和内存
- STAT : 进程状态信息,S I 表示阻塞状态 ,R 表示就绪状态或者运行状态
- START : 进程启动时间
- COMMAND : 通过什么程序启动的进程
- 进程树形结构
1
pstree
- 父子进程:在Linux操作系统中,进程形成树形关系,任务上一级进程是下一级的父进程,下一级进程是上一级的子进程。
- 查看进程信息
:star:多进程编程
- 使用模块 : multiprocessing
- 创建流程
- 将需要新进程执行的事件封装为函数
- 通过模块的Process类创建进程对象,关联函数
- 通过进程对象调用start启动进程
- 主要类和函数使用
1 | Process() |
1 | p.start() |
注意 : 启动进程此时target绑定函数开始执行,该函数作为新进程执行内容,此时进程真正被创建
1 | p.join([timeout]) |
1 | 进程创建示例: |
1 | """ |
- 进程执行现象理解 (难点)
- 新的进程是原有进程的子进程,子进程复制父进程全部内存空间代码段,一个进程可以创建多个子进程。
- 子进程只执行指定的函数,其余内容均是父进程执行内容,但是子进程也拥有其他父进程资源。
- 各个进程在执行上互不影响,也没有先后顺序关系。
- 进程创建后,各个进程空间独立,相互没有影响。
- multiprocessing 创建的子进程中无法使用标准输入(即无法使用input)。
:star:进程处理细节
- 进程相关函数
1 | os.getpid() |
1 | os.getppid() |
1 | sys.exit(info) |
1 | """ |
- 孤儿进程和僵尸进程
- 孤儿进程: 父进程先于子进程退出时,子进程会成为孤儿进程,孤儿进程会被系统自动收养,成为孤儿进程新的父进程,并在孤儿进程退出时释放其资源。
- 僵尸进程: 子进程先于父进程退出,父进程又没有处理子进程的退出状态,此时子进程就会成为僵尸进程。
特点: 僵尸进程虽然结束,但是会存留部分进程资源在内存中,大量的僵尸进程会浪费系统资源。Python模块当中自动建立了僵尸处理机制,每次创建新进程都进行检查,将之前产生的僵尸处理掉,而且父进程退出前,僵尸也会被自动处理。
:star:创建进程类
进程的基本创建方法将子进程执行的内容封装为函数。如果我们更热衷于面向对象的编程思想,也可以使用类来封装进程内容。
-
创建步骤
- 继承Process类
- 重写
__init__方法添加自己的属性,使用super()加载父类属性 - 重写run()方法
-
使用方法
- 实例化对象
- 调用start自动执行run方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20"""
自定义进程类
"""
from multiprocessing import Process
from time import sleep
class MyProcess(Process):
def __init__(self, value):
self.value = value
super().__init__() # 调用父类的init
# 重写run 作为进程的执行内容
def run(self):
for i in range(self.value):
sleep(2)
print("自定义进程类。。。。")
p = MyProcess(3)
p.start() # 将 run方法作为进程执行
:star:进程间通信
-
必要性: 进程间空间独立,资源不共享,此时在需要进程间数据传输时就需要特定的手段进行数据通信。
-
常用进程间通信方法:消息队列,套接字等。
-
消息队列使用
-
通信原理: 在内存中开辟空间,建立队列模型,进程通过队列将消息存入,或者从队列取出完成进程间通信。
-
实现方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19from multiprocessing import Queue
q = Queue(maxsize=0)
功能: 创建队列对象
参数:最多存放消息个数
返回值:队列对象
q.put(data)
功能:向队列存入消息
参数:data 要存入的内容
q.get()
功能:从队列取出消息
返回值: 返回获取到的内容
q.full() 判断队列是否为满
q.empty() 判断队列是否为空
q.qsize() 获取队列中消息个数
q.close() 关闭队列
-
:star2:线程 (Thread)
:star:线程概述
- 什么是线程
- 线程被称为轻量级的进程,也是多任务编程方式
- 也可以利用计算机的多cpu资源
- 线程可以理解为进程中再开辟的分支任务
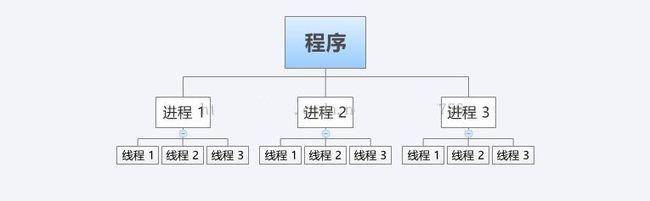
- 线程特征
- 一个进程中可以包含多个线程
- 线程也是一个运行行为,消耗计算机资源
- 一个进程中的所有线程 共享 这个进程的资源,可以对进程中的资源进行修改,见线程同步互斥。
- 多个线程之间的运行同样互不影响各自运行
- 线程的创建和销毁消耗资源远小于进程
:star:多线程编程
注:类似于 multiprocessing 模块
- 线程模块: threading
- 创建方法
- 创建线程对象
1
2
3
4
5
6
7
8from threading import Thread
t = Thread()
功能:创建线程对象
参数:target 绑定线程函数
args 元组 给线程函数位置传参
kwargs 字典 给线程函数键值传参
daemon bool值,主线程推出时该分支线程也推出 - 启动线程
1
t.start()
- 等待分支线程结束
1
2
3t.join([timeout])
功能:阻塞等待分支线程退出
参数:最长等待时间
- 创建线程对象
:star:创建线程类
-
创建步骤
- 继承Thread类
- 重写
__init__方法添加自己的属性,使用super()加载父类属性 - 重写run()方法
-
使用方法
- 实例化对象
- 调用start自动执行run方法
:star:线程同步互斥
- 线程通信方法: 线程间使用全局变量进行通信
- 共享资源争夺
- 共享资源:多线程都可以操作的资源称为共享资源。对共享资源的操作代码段称为临界区。
- 影响 : 对共享资源的无序操作可能会带来数据的混乱,或者操作错误。此时往往需要 同步互斥机制 协调操作顺序。
- 同步互斥机制
- 同步 : 同步是一种协作关系,为完成操作,线程间形成一种协调,按照必要的步骤有序执行操作。
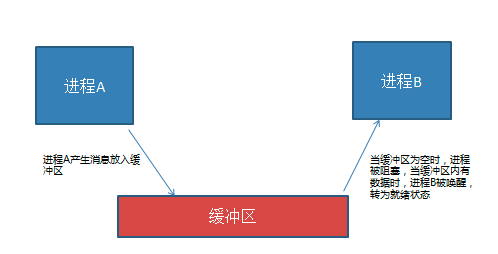
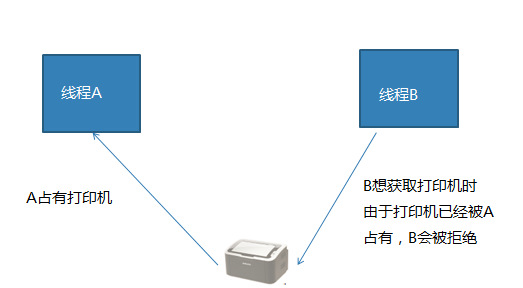
- 互斥 : 互斥是一种制约关系,当一个进程或者线程占有资源时会进行加锁处理,此时其他进程线程就无法操作该资源,直到解锁后才能操作。
- 同步 : 同步是一种协作关系,为完成操作,线程间形成一种协调,按照必要的步骤有序执行操作。
:star:线程Event
1 | from threading import Event |
1 | Event使用示例: |
:star:线程锁Lock
1 | from threading import Lock |
1 | Lock使用示例: |
:star:Event 和 Lock 的关系
- Event 在线程间存在先后顺序的时候使用,表示前置事件的结束和开始。
- Lock 在线程间无先后顺序的时候使用,表示不可同时对锁部分进行处理。
:star:死锁
-
什么是死锁
死锁是指两个或两个以上的线程在执行过程中,由于 竞争资源 或者由于 彼此通信 而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁。
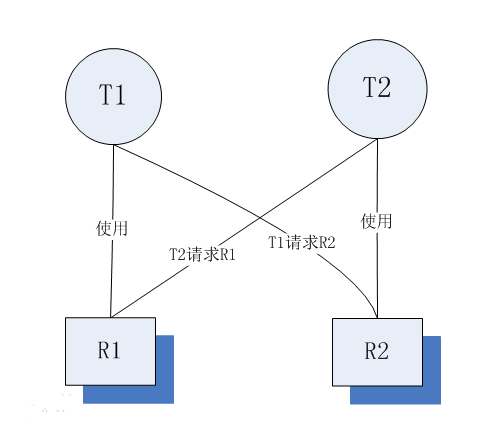
死锁产生条件展开说明
- 互斥条件:指线程使用了互斥方法,使用一个资源时其他线程无法使用。
- 请求和保持条件:指线程已经保持至少一个资源,但又提出了新的资源请求,在获取到新的资源前不会释放自己保持的资源。
- 不剥夺条件:不会受到线程外部的干扰,如系统强制终止线程,设置最长等待时间等。
- 环路等待条件:指在发生死锁时,必然存在一个线程——资源的环形链,如 T0正在等待一个T1占用的资源;T1正在等待T2占用的资源,……,Tn正在等待已被T0占用的资源。
为了避免死锁,我们需要有一个清晰的逻辑,防止同时出现上述死锁产生的四个条件,并且通过测试工程师进行的死锁检测。
:star:全局解释器锁(GIL)问题
由于 python 的 C 解释器设计中加入了解释器锁,导致python解释器同一时刻只能解释执行 一个线程,无法实现线程的并行。因此Python多线程并发在执行 多阻塞 任务时可以提升程序效率,其他情况并不能对效率有所提升。
注:线程遇到阻塞时线程会主动让出解释器,去解释其他线程。
关于GIL问题的处理
- 尽量使用进程完成无阻塞的并发行为
- 不使用c作为解释器 (可以用Java C#)
- GIL问题与Python语言本身并没什么关系,属于解释器设计的历史问题。
Guido的声明



