说明
- 本页面无手机端适配,强制缩放阅读。
- 使用纯html格式,保存教学用ppt,添加了部分个人笔记。
- 目录工作正常,可以跳转。
PaddlePaddle概述
PaddlePaddle概述
PaddlePaddle概述
PaddlePaddle简介
为什么要学PaddlePaddle
什么是PaddlePaddle
PaddlePaddle优点
PaddlePaddle缺点
国际竞赛获奖情况
行业应用
课程概览
学习资源

知
识
讲
解
什么是PaddlePaddle
Ø
PaddlePaddle(Parallel Distributed Deep Learning,中文名飞桨)
是百度公司推出的开源、易学习、易使用的分布式深度学习平台
Ø
源于产业实践,在实际中有着优异表现
Ø
支持多种机器学习经典模型

知
识
讲
解
为什么学习PaddlePaddle
Ø
开源、国产
Ø
能更好、更快解工程决实际问题

知
识
讲
解
PaddlePaddle优点
Ø
易用性。语法简洁,API的设计干净清晰
Ø
丰富的模型库。借助于其丰富的模型库,可以非常容易的复现一些经典
方法
Ø
全中文说明文档。首家完整支持中文文档的深度学习平台
Ø
运行速度快。充分利用 GPU 集群的性能,为分布式环境的并行计算进行
加速

知
识
讲
解
PaddlePaddle缺点
Ø
教材少
Ø
学习难度大、曲线陡峭

知
识
讲
解
国际竞赛获奖情况

知
识
讲
解
行业应用

知
识
讲
解
学习资源
Ø
官网
ü
地址:https://www.paddlepaddle.org.cn/
ü
内容:学习指南、文档、API手册
Ø
百度云智学院
ü
地址:http://abcxueyuan.cloud.baidu.com/#/courseDetail?id=14958
ü
内容:教学视频
Ø
AIStudio
ü
地址:https://aistudio.baidu.com/aistudio/projectoverview/public/1
ü
内容:项目案例
体系结构
体系结构
体系结构
体系结构
编译时与执行时
总体架构
三个重要术语
案例1:快速开始
知
识
讲
解
总体架构
组网模块
PythonAPI
服务器预测
服务器预测API
服务器预测RunTime
训练模块
训练RunTime
CPU/GPU集群
模型Program
统一中间表达
统一中间表达优化
移动端预测
移动端预测API
移动端预测RunTime
模型表达与优化

知
识
讲
解
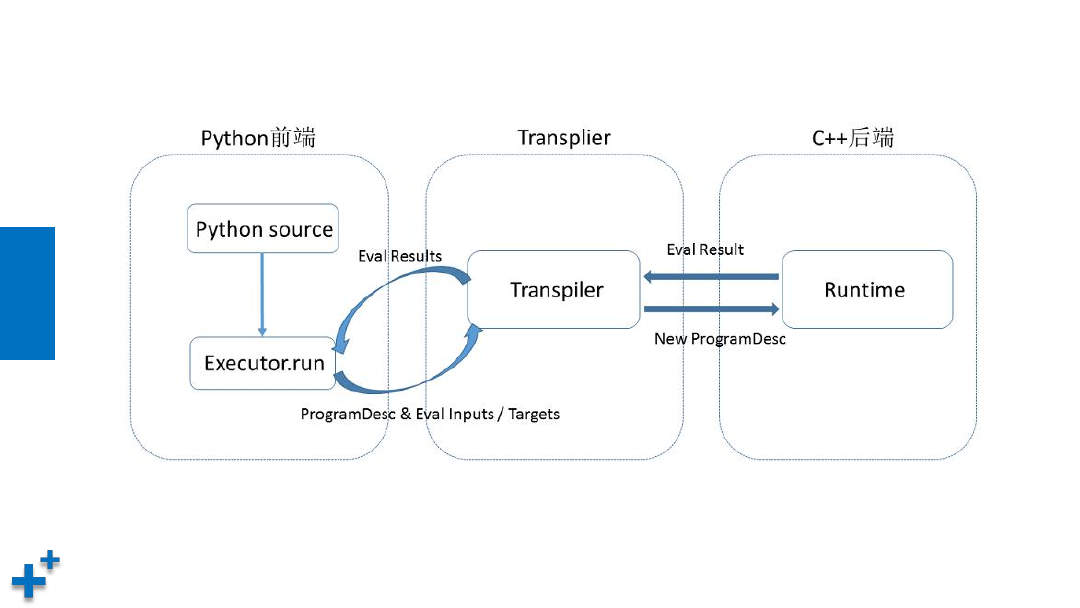
编译与执行过程
1. 用户编写的python程序通过调用 Paddle 提供的算子,向Program 中添加变量
(Tensor)以及对变量的操作(Operators 或者 Layers)
2. 原始Program在框架内部转换为中间描述语言: ProgramDesc
3. Transpiler 接受一段 ProgramDesc ,输出一段变化后的 ProgramDesc ,作为后端
Executor 最终需要执行的 Program
4. 执行 ProgramDesc 中定义的 Operator(可以类比为程序语言中的指令),在执行
过程中会为 Operator 创建所需的输入输出并进行管理
知
识
讲
解
编译与执行过程(续)

知
识
讲
解
三个重要术语
Ø
Fluid:定义程序执行流程
Ø
Program:对用户来说一个完整的程序
Ø
Executor:执行器,执行程序
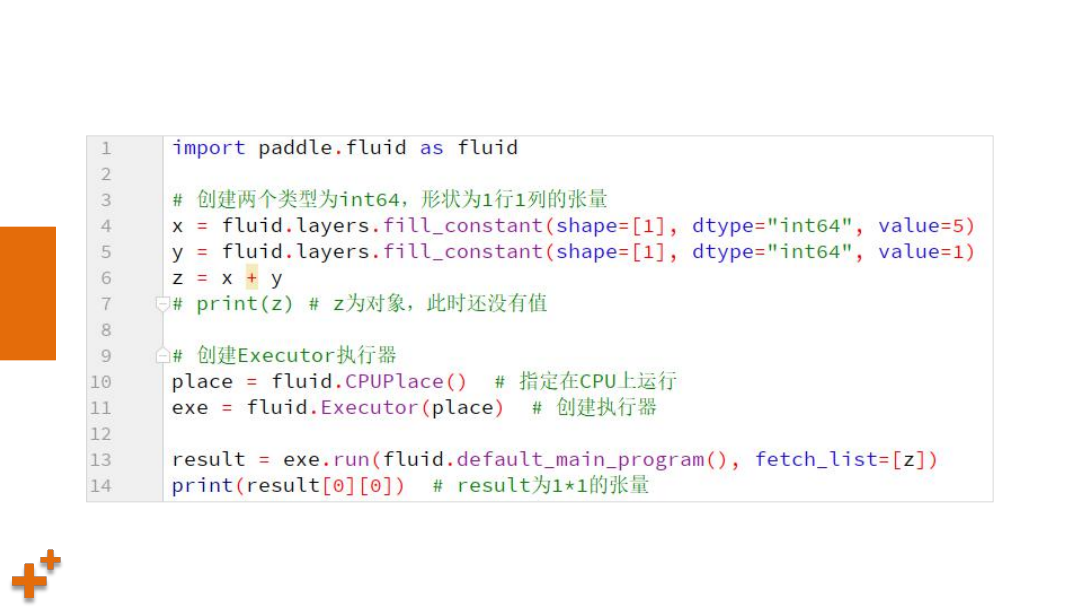
课
堂
练
习
案例1:快速开始
基本概念与操作
基本概念与操作
基本概念与操作
基本概念
Layer
张量
Variable
Program
Place
Optimizer
案例2:执行两个张量计算
实现线性回归
程序执行步骤
案例3:编写简单线性回归
Executor
Fluid API结构图
基本概念
知
识
讲
解
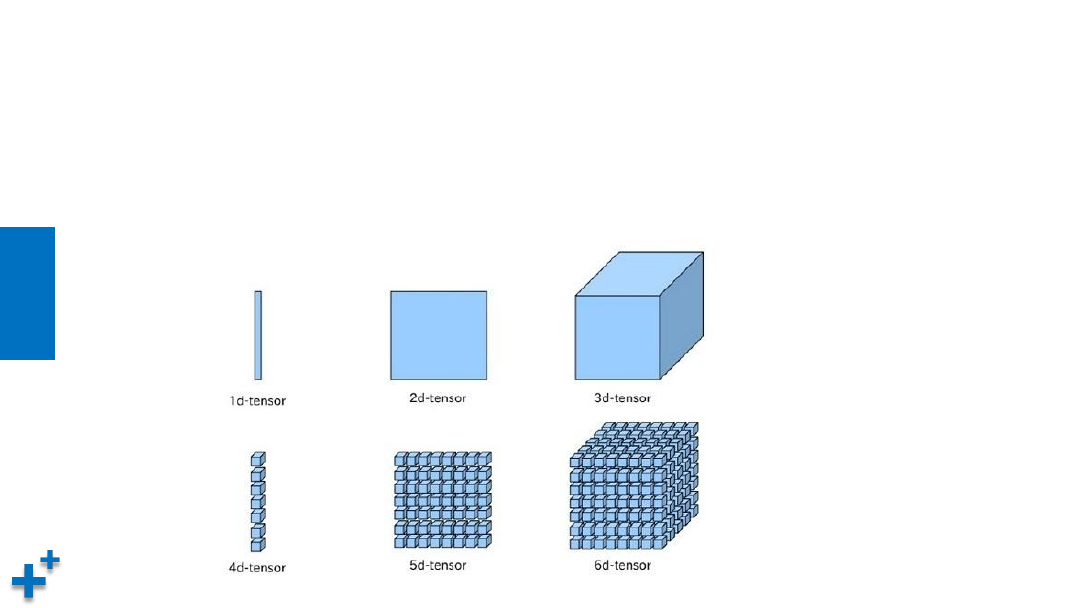
张量
• 什么是张量
张量(Tensor): 多维数组或向量,同其它主流深度学习框架一样,
PaddlePaddle使用张量来承载数据
知
识
讲
解
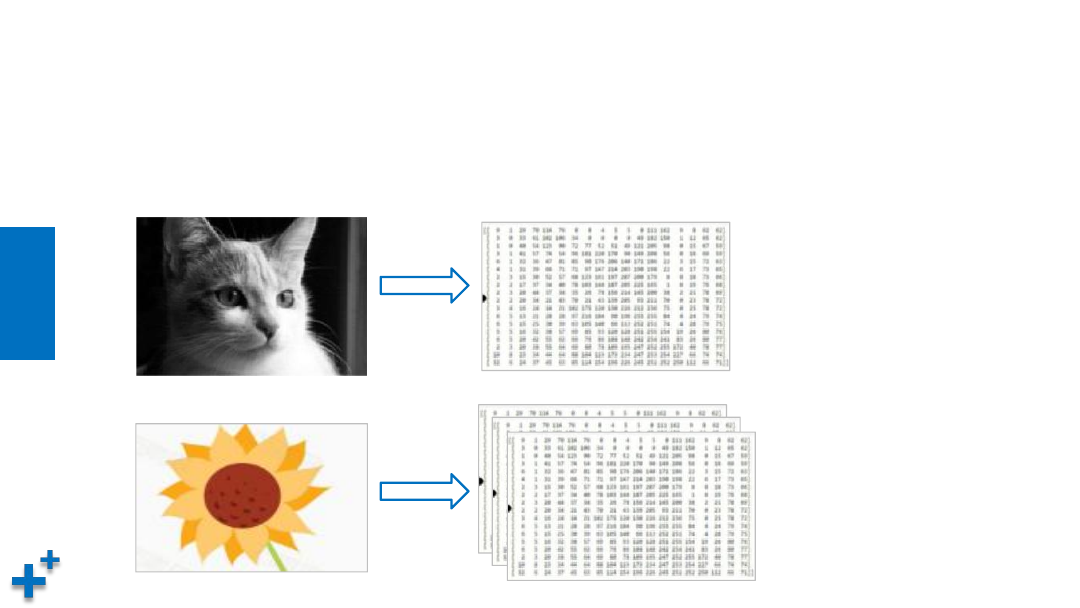
张量(续1)
• 张量示例
灰度图像为二维张量(矩阵),彩色图像为三维张量

知
识
讲
解
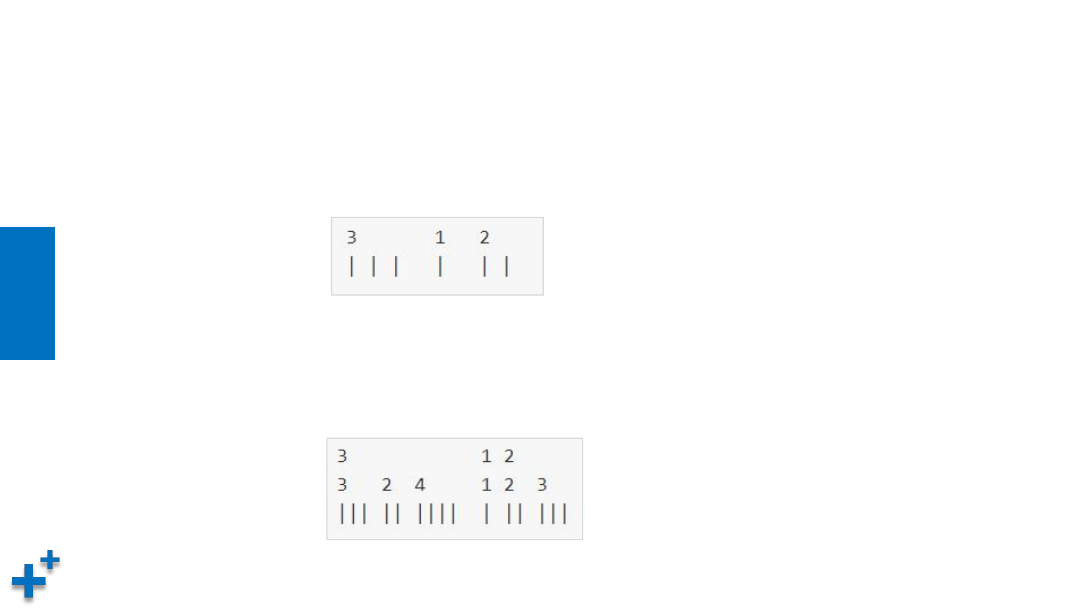
LoDTensor
Ø
LoD(Level-of-Detail) Tensor是Paddle的高级特性,是对Tensor的一种
扩充。LoDTensor通过牺牲灵活性来提升训练的效率。
Ø
LoDTensor用来处理变长数据信息,将长度不一致的维度拼接为一个大的
维度,并引入了一个索引数据结构(LoD)来将张量分割成序列。
知
识
讲
解
LoDTensor(续)
Ø
假设一个mini-batch中有3个句子,每个句子中分别包含3个、1个和2个单词,我
们可以用(3+1+2)xD维Tensor 加上一些索引信息来表示这个mini-batch:
Ø
假设存在一个mini-batch中包含3个句子、1个句子和2个句子的文章,每个句子都
由不同数量的单词组成,则这个mini-batch的可以表示为2-Level的LoDTensor:

知
识
讲
解
Layer
Ø
表示一个独立的计算逻辑,通常包含一个或多个operator(操
作),如layers.relu表示ReLU计算;layers.pool2d表示pool操
作。Layer的输入和输出为Variable。

知
识
讲
解
Variable
Ø
表示一个变量,在paddle中,Variable 基本等价于 Tensor 。
Variable进入Layer计算,然后Layer返回Variable。创建变量方式:
Paddle变量
Python变量

知
识
讲
解
Variable(续)
Ø
Paddle 中存在三种 Variable:
ü
模型中的可学习参数:
包括网络权重、偏置,生存期和整个训练任务
一样长。通过 fluid.layers.create_parameter 来创建可学习参数
ü
占位 Variable:
Paddle 中使用 fluid.data 来接收输入数据,
fluid.data 需要提供输入 Tensor 的形状信息,当遇到无法确定的维度
时,相应维度指定为 None
ü
常量 Variable:
通过 fluid.layers.fill_constant 来实现常量Variable
知
识
讲
解
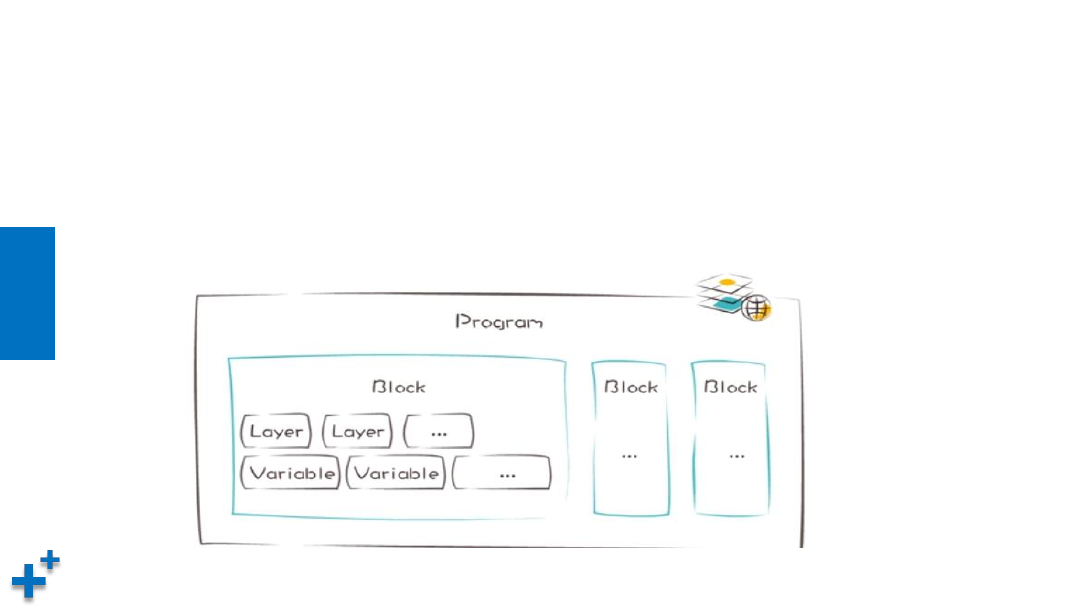
Program
Ø
Program包含Variable定义的多个变量和Layer定义的多个计算,是
一套完整的计算逻辑。从用户角度来看,Program是顺序、完整执
行的。
program 的作用是存储网络结构,但不存储参数。

知
识
讲
解
Program(续)
Ø
用户完成网络定义后,一段 Paddle 程序中通常存在 2 个 Program
ü
fluid.default_startup_program
:定义了模型参数初始化、优化器参
数初始化、reader初始化等各种操作。该program可以由框架自动生成,
使用时无需显式地创建
ü
fluid.default_main_program
:定义了神经网络模型,前向反向计算,
以及模型参数更新、优化器参数更新等各种操作

知
识
讲
解
Scope
Ø
scope 在 paddle 里可以看作变量空间,存储fluid创建的变量。变量
存储于unordered_map 数据结构中,该结构类似于python中的dict,
键是变量的名字,值是变量的指针。
Ø
一 个 p a d d l e 程 序 有 一 个 默 认 的 全 局 s c o p e ( 可 以 通 过
fluid.global_scope() 获取)。如果没有主动创建 scope 并且通过
fluid.scope_guard() 替换当前 scope,那么所有参数都在全局 scope
中。
参数创建的时机不是在组网时,而是在 executor.run() 执行时。
Ø
program 和 scope 配合,才能表达完整模型(模型=网络结构+参数)
知
识
讲
解
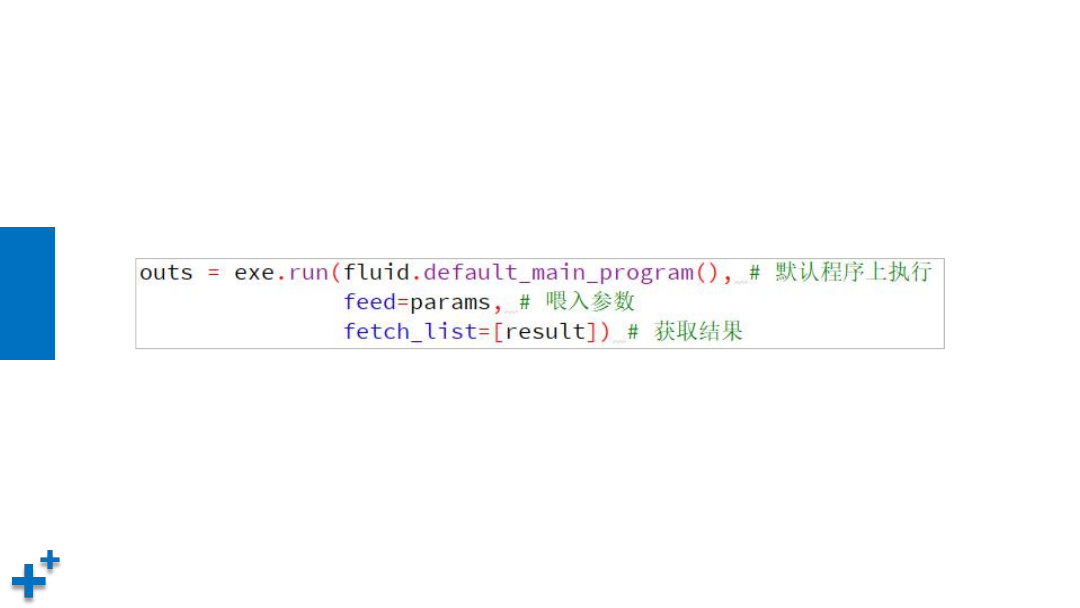
Executor
Ø
Executor用来接收并执行Program,会一次执行Program中定义的
所有计算。通过feed来传入参数,通过fetch_list来获取执行结果。
知
识
讲
解
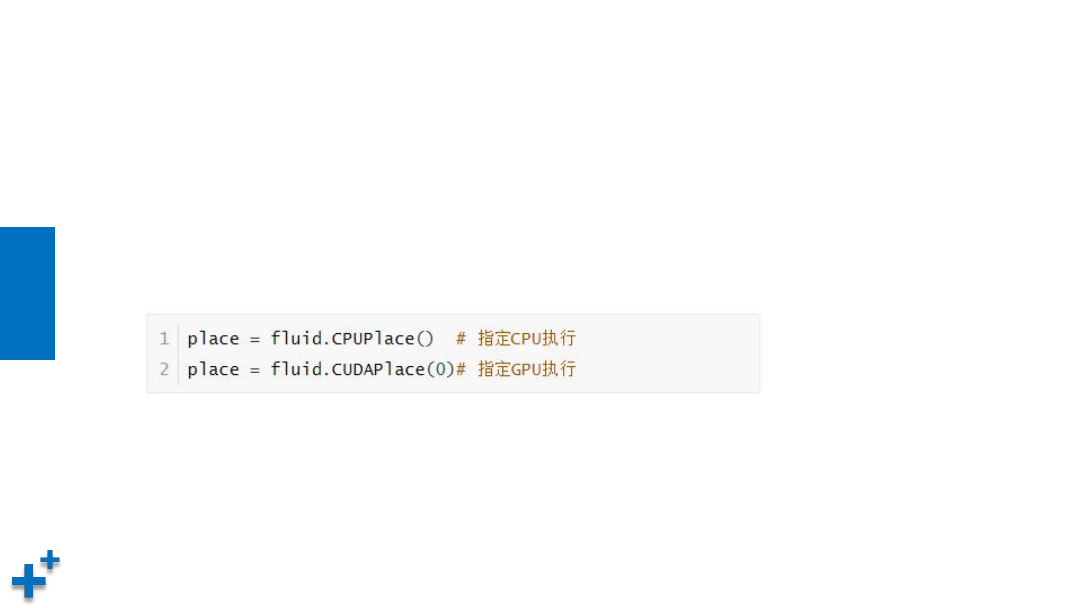
Place
Ø
PaddlePaddle可以运行在Intel CPU,Nvidia GPU,ARM CPU和更
多嵌入式设备上,可以通过Place用来指定执行的设备(CPU或
GPU)。

知
识
讲
解
Optimizer
Ø
优化器,用于优化网络,一般用来对损失函数做梯度下降优化,从而
求得最小损失值
课
堂
练
习
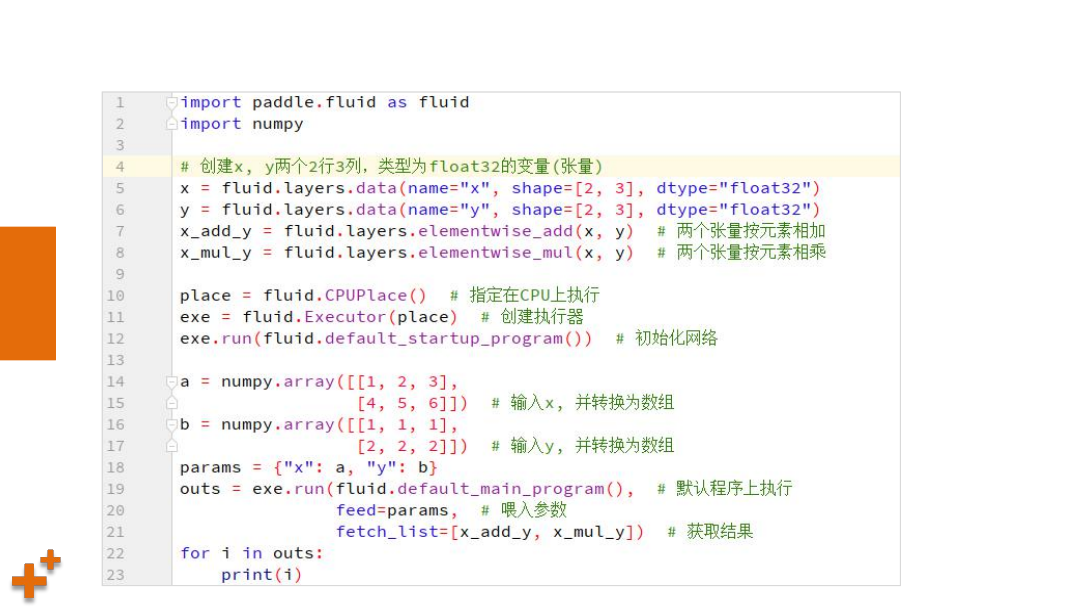
案例2:执行两个张量计算
知
识
讲
解
程序执行步骤
定
义
变
量
定
义
操
作
定
义
执
行
器
定义
loss
和
优化
器
训
练
模
型
获
取
结
果
保
存
/
加
载
模
型
执
行
课
堂
练
习
案例3:编写简单线性回归
Ø
任务:
ü
给出输入样本
ü
给出实际输出样本
ü
找出
y = wx+b
公式中的
w
和
b
Ø
思路:
ü
定义输入数据、实际输出结果
ü
将数据送入神经网络进行训练(全连接网络,即分类器)
ü
根据实际输出、预测输出之间的损失值,进行梯度下降,直到收敛到极小值为止

课
堂
练
习
案例3:编写简单线性回归(续)
Ø
技术要点:
ü
神经网络,选择
fluid.layers.fc( )
,该函数在神经网络中建立一个全连接层。接收
多个输入,为每个输入分配一个权重w, 并维护一个偏置值b;预测时产生一个输出
ü
损 失 函 数 : 回 归 问 题 , 选 择 均 方 差
f l u i d . l a y e r s .
s q u a r e _ e r r o r _ c o s t 和
fluid.layers.mean( )
作为损失函数
ü
优化器:随机梯度下降优化器
fluild.SGD
,做梯度下降计算
代码见:simple_lr.py
知
识
讲
解
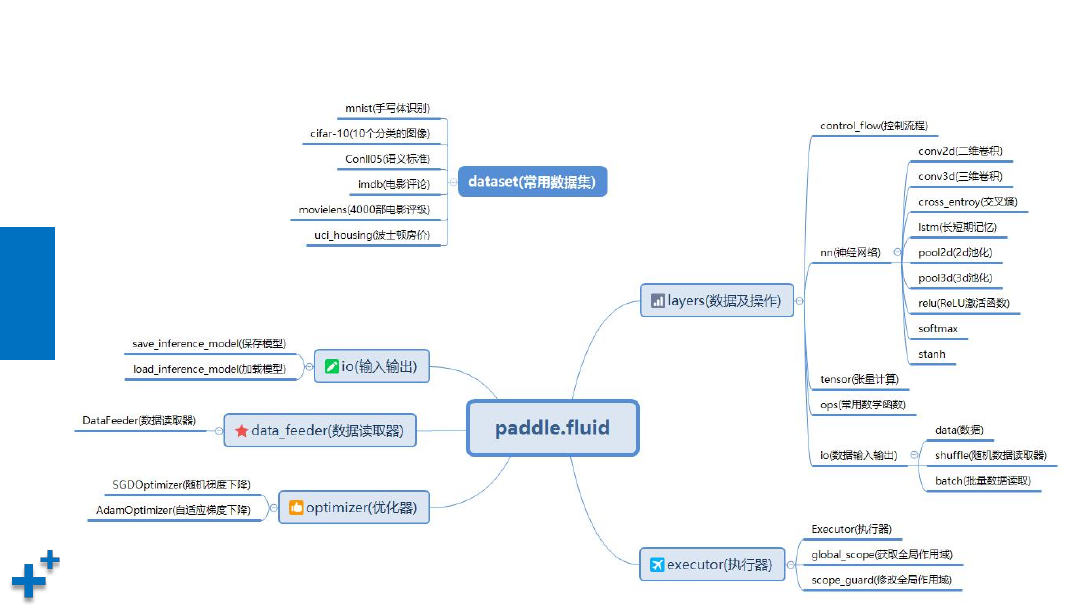
fluid API结构图
数据准备
数据准备
数据准备
数据准备
案例4:使用reader
什么是数据准备
为什么需要数据准备
实现多元回归
数据集及任务
思路
执行结果
案例5:波士顿房价预测

知
识
讲
解
深度学习数据读取要求
Ø
从文件读入数据。
因为程序无法保存大量数据,数据一般保存到文
件中,所以需要单独的数据读取操作
Ø
批量快速读入。
深度学习样本数据量较大,需要快速、高效读取
(批量读取模式)
Ø
随机读入。
为了提高模型泛化能力,有时需要随机读取数据(随机
读取模式)
课
堂
练
习
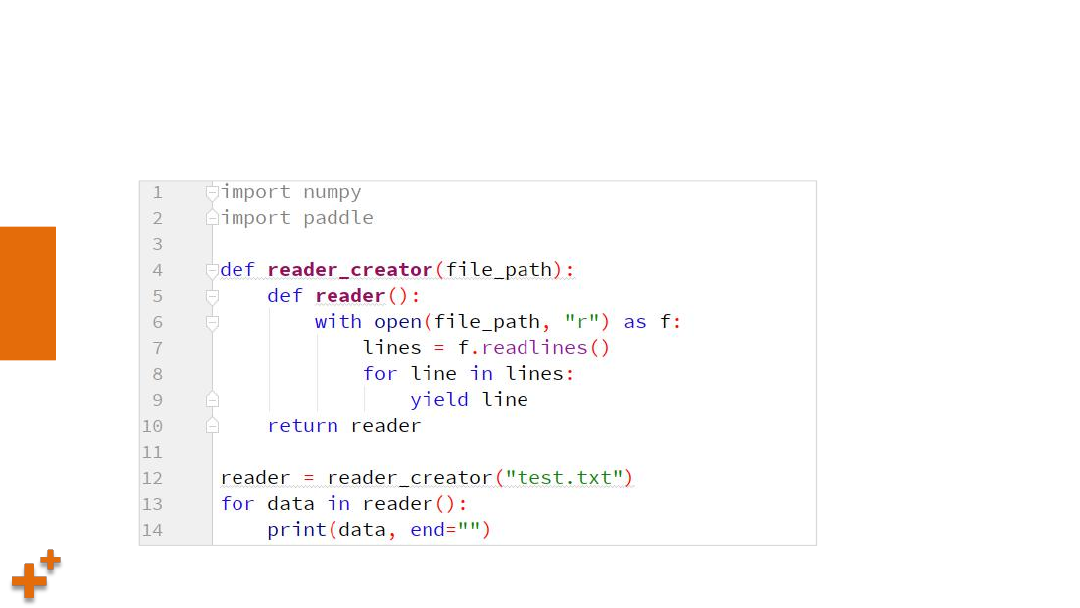
案例4:使用reader
Ø
自定义reader creator,从文本文件test.txt中读取一行数据
课
堂
练
习
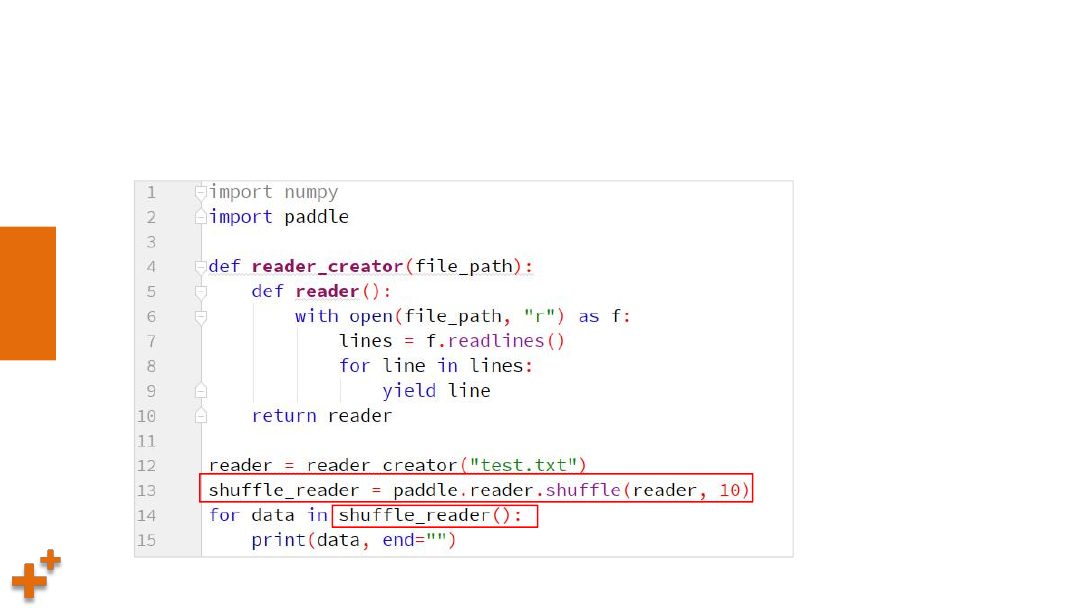
案例4:使用reader(续1)
Ø
从上一个reader中以随机方式读取数据
课
堂
练
习
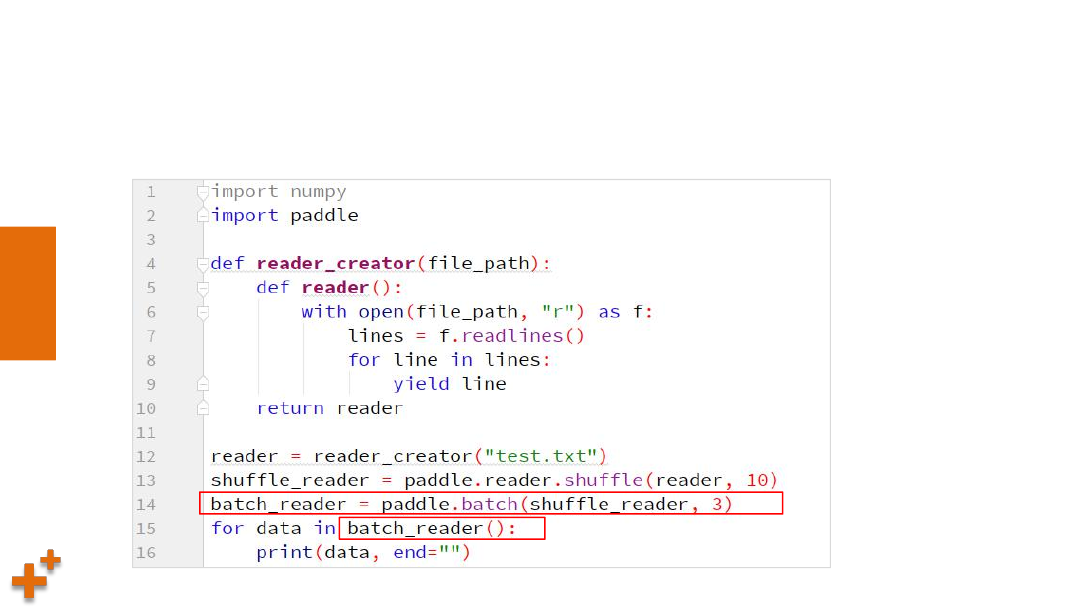
案例4:使用reader(续2)
Ø
从上一个随机读取器中,分批次读取数据
实现多元回归

知
识
讲
解
数据集及任务
Ø
数据集介绍
ü
数据量:506笔
ü
特征数量:13个(见
右图)
ü
标签:价格中位数
Ø
任务:根据样本数据,
预测房价中位数(回归
问题)
知
识
讲
解
思路
数据准备
搭建网络
模型训练、评估
模型预测
使用reader对象,随机、批量读取数据样本
两个reader分别读取训练、测试样本
使用全连接网络模型,输入为13个特征值
输出为一个预测价格中位数
均方差损失函数(回归问题)
使用随机梯度下降优化器优化
训练迭代N轮
加载模型,喂入测试数据
进行测试
代码见:linear_regression.py
知
识
讲
解
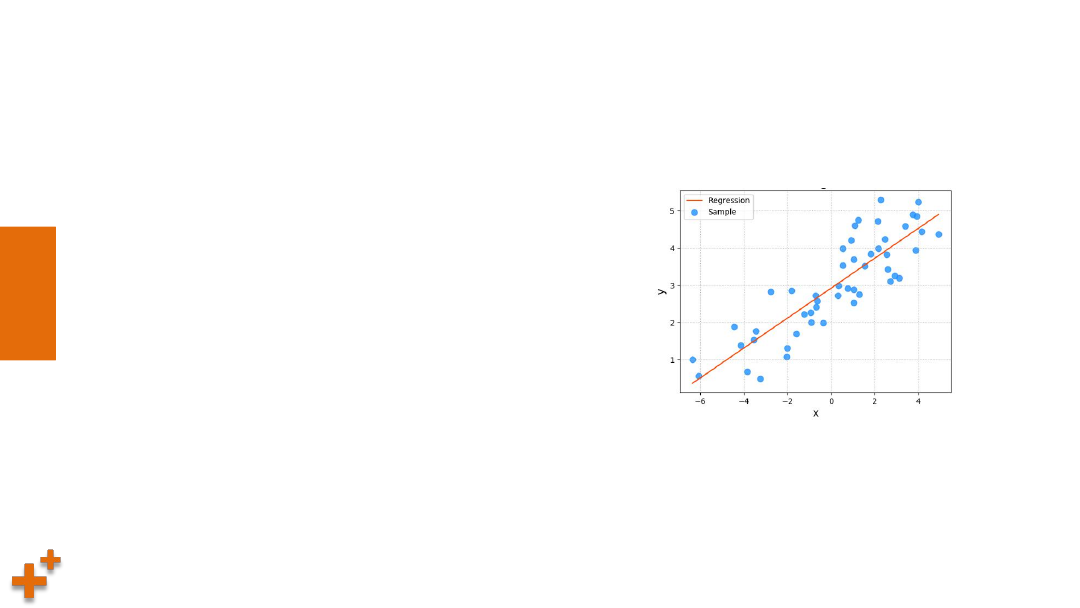
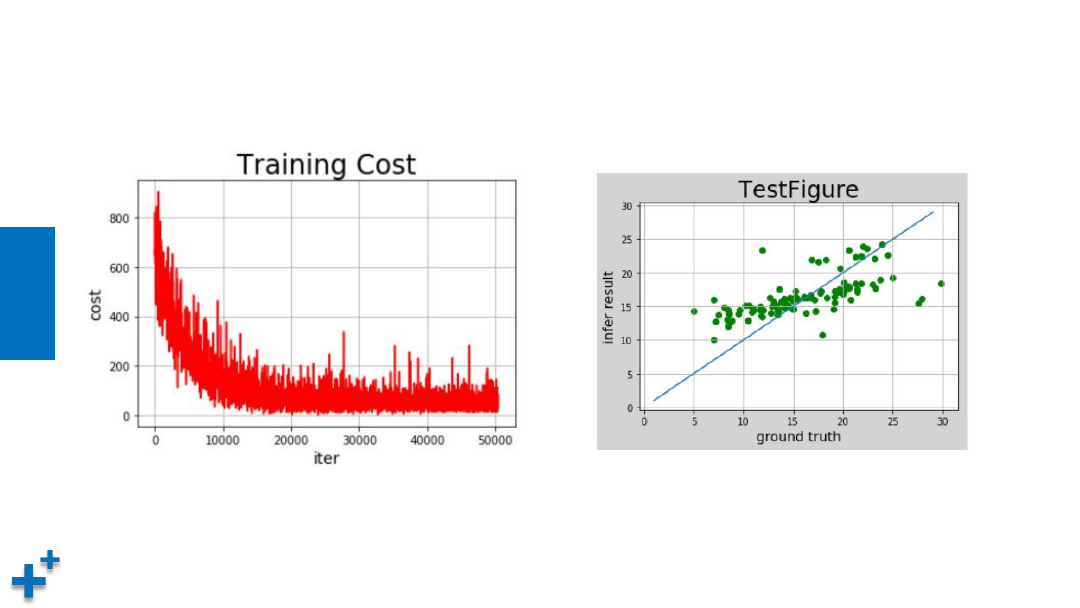
执行结果
损失函数收敛过程
预测值与实际值对比

课
堂
练
习
案例5:波士顿房价预测
Ø
全部代码见:uci_housing.py

今日总结
• PaddlePaddle体系结构与基本概念
– Tensor, Layer, Program, Variable, Executor,Place
– Fluid API组织结构
• 案例:
– 简单线性回归
– 机器学习经典案例:波士顿房价预测



