待办清单:
- 网络整体:x_net.py
- 特征融合网络层:x_net_fusion_layers.py
- 网络配置文件:xnet
开发日志:
日志01
使用pycharm的SSH连接docker,不如设置pycharm的编译器为docker中的python。这样做的优势有三:
- 不需要通过ssh传输图像,pycharm的运行速度更快。
- 因为docker同步了工作目录,不需要使用pycharm来同步,节省时间。
- 不需要重新弄配置pycharm。
需要修改的有两个位置,一个是configs中的配置文件,一个是mmdet3d中的models相关文件。参照官方教程:教程 1: 学习配置文件和教程 4: 自定义模型
整个框架的思路是从配置文件中去找对应的模型,程序会在一开始把模型全部注册到一个位置,然后使用配置文件中的type关键字去搜索,然后使用其他的作为参数输入,具体需要什么参数由模型决定。
阅读代码的时候发现,框架对自编码器有一定的支持,这一点在完成主干网络的构建后深入调查一下。
日志02
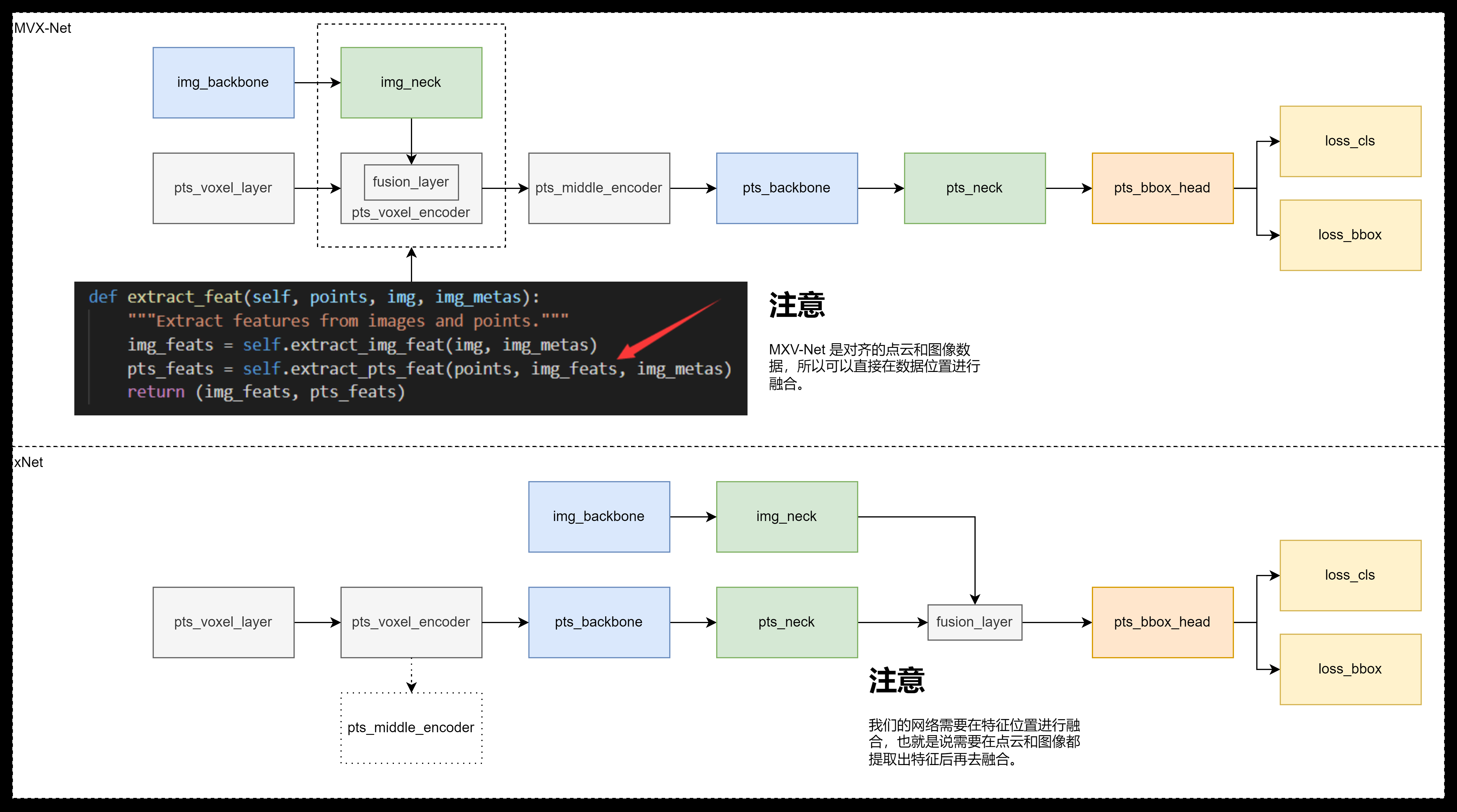
注意到代码中 fusion layer 本来是分出来的,但是因为代码复用的问题,实际上并没有分出来,导致变量冗余。我们对代码进行重构,在完成图像和点云特征提取后再使用 fusion layer 合并。
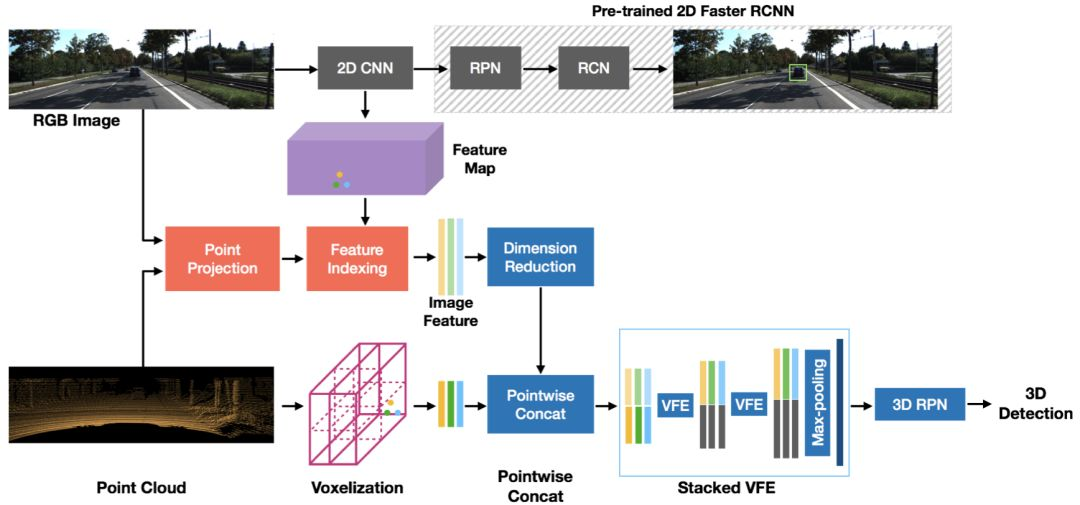
上述问题描述并不正确,这样的结构不仅仅是因为代码复用,也是因为分析的MVX-Net的模型的结构。MVX-Net是一个数据级融合,需要对齐点云和图像数据,然后将图像的数据提炼(降维),然后将提炼后的数据补充到点云数据上,最后进入检测主干网络(这里用的SECOND backbone)。
日志03
哪一块儿网络需要预训练参数,哪里就加上Pretrained参数,格式为Pretrained="<模型路径>"
小技巧:直接搜索配置文件中的tpye关键字即可找到对应的模型类位置。
主模态交换网络是可以使用的,而且很容易实现,因为在fusion返回了每一个模态对应的输出,所以只要融合以后返回对应的就好了。
辅模态Attention机制稍微有些麻烦,需要多出来很多的计算量,但是也是很简单就可以实现的。
PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds

我们也可以直接用PointNet++的解码器来做这件事。
日志04
将数据集软链接到工作目录下。
使用wget下载anaconda,配置运行权限,开始安装。
1 | conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge |
日志05
原先使用的MVX使用的是预训练图像特征提取网络,所以代码中没有图像特征提取模型的训练。
1 | # 单卡训练: |
1 | # 单块显卡测试/生成评估结果 |
日志06
- 显存问题:Pytorch Memory management
- 解决no grad问题:https://discuss.pytorch.org/t/ddp-parameters-didnt-receive-gradients-for-used-module/137796
日志07
- concate方法实现,不需要修改太多的东西,我们只需要保证Fusion layer输出的形状是4维即可。



