一、基本介绍
1. 什么是语义分割
语义分割(Semantic Segmentation)是图像处理和机器视觉一个重要分支,其目标是精确理解图像场景与内容。语义分割是在像素级别上的分类,属于同一类的像素都要被归为一类,因此语义分割是从像素级别来理解图像的。如下如所示的照片,属于人的像素部分划分成一类,属于摩托车的像素划分成一类,背景像素划分为一类。

- 语义分割(semantic segmentation):对图像中的每个像素划分到不同的类别;
- 实例分割(instance segmentation):对图像中每个像素划分到不同的个体(可以理解为目标检测和语义分割的结合);
- 全景分割(panoptic segmentation):语义分割和实例分割的结合,即要对所有目标都检测出来,又要区分出同个类别中的不同实例。

1)无人驾驶

2)医学、生物图像分割(如病灶识别)
3)无人机着陆点判断
4)自动抠图
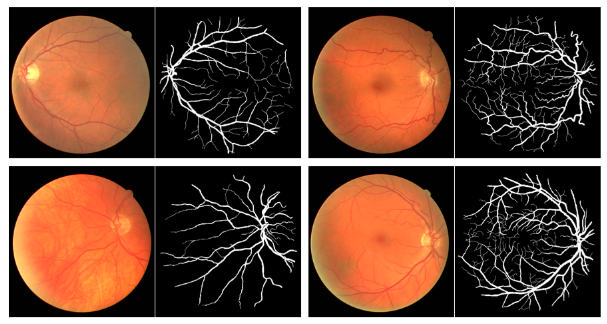
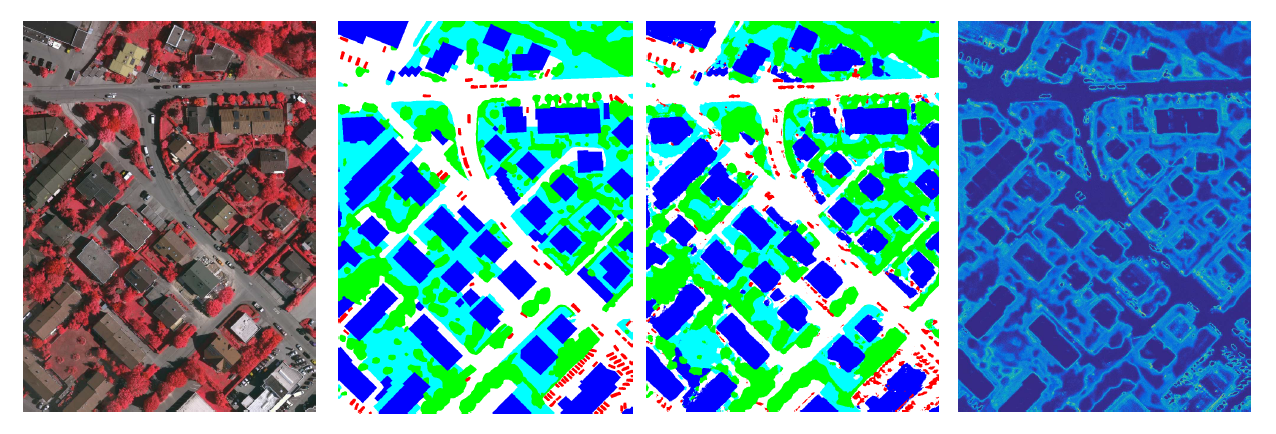
5)遥感图像分割
3. 语义分割的难点
1)数据问题:分割不像检测等任务,只需要标注边框就可以使用,分割需要精确到像素级标注,包括每一个目标的轮廓等信息;
2)计算资源问题:要想得到较高的精度就需要使用更深的网络、进行更精确的计算,对计算资源要求较高。目前业界有一些轻量级网络,但总体精度较低;
3)精细分割:目前很多算法对于道路、建筑物等类别分割精度很高,能达到98%,而对于细小的类别,由于其轮廓太小,而无法精确的定位轮廓;
4)上下文信息:分割中上下文信息很重要,否则会造成一个目标被分成多个部分,或者不同类别目标分类成相同类别;
二、语义分割基本原理
1. 整体实现思路
语义分割一般思路如下:
1)输入图像,利用深度卷积神经网络提取特征
2)对特征图进行上采样,输出每个像素的类别
3)利用损失函数,对模型进行优化,将每个像素的分类结果优化到最接近真实值
2. 评价指标
1)像素精度(pixel accuracy ):每一类像素正确分类的个数/ 每一类像素的实际个数;
2)均像素精度(mean pixel accuracy ):每一类像素的精度的平均值;
3)平均交并比(Mean Intersection over Union):求出每一类的IOU取平均值。
三、常用模型
1. FCN(2014)
FCN(全称Fully Convolutional Networks)是图像语义分割的开山之作,2014年由加州大学伯克利分校Jonathan Long等人提出(论文名称《Fully Convolutional Networks for Semantic Segmentation》,该论文存在多个版本)。在该网络模型中,使用卷积层代替普通CNN中的全连接层,使用不同尺度信息融合,可以生成任意大小的图像分割图,从而实现对图像进行像素级的分类。
1)什么是FCN
一个典型的卷积神经网络在处理图像分类问题时,通常会使用若干个卷积层,之后接若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量,由输出层在softmax激活函数的作用下,产生N个分类概率,取其中概率最大的类别作为分类结果。如下图所示:
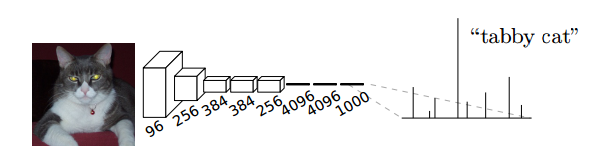
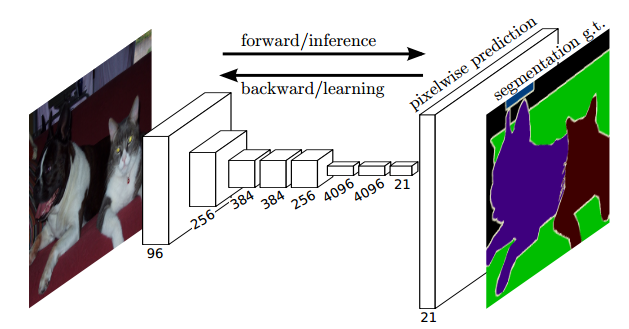
图像语义分割需要对图像进行像素级分类,所以在输出层使用全连接模型并不合适。FCN与CNN的区别在把于CNN最后的全连接层换成卷积层(所以称为“全卷积网络”)。该网络可以分为两部分,第一部分,通过卷积运算提取图像中的特征,形成特征图;第二部分,对特征图进行上采样,将特征图数据恢复为原来的大小,并对每个像素产生一个分类标签,完成像素级分类。结构如下图所示:
上采样示意图:
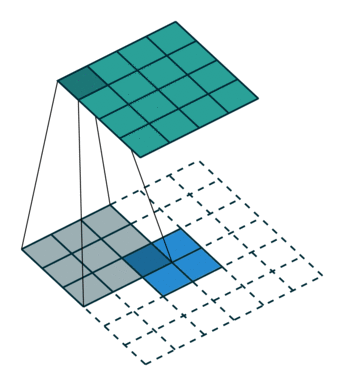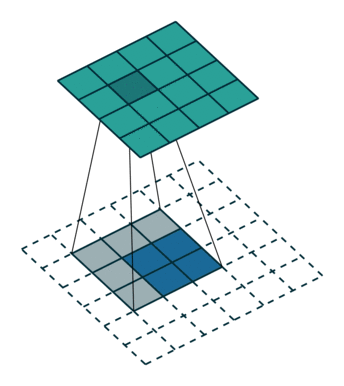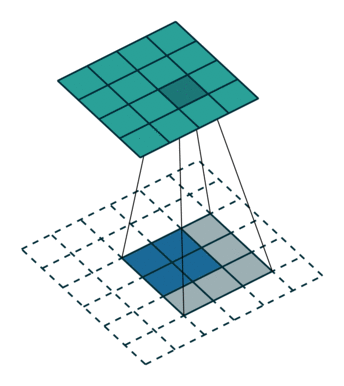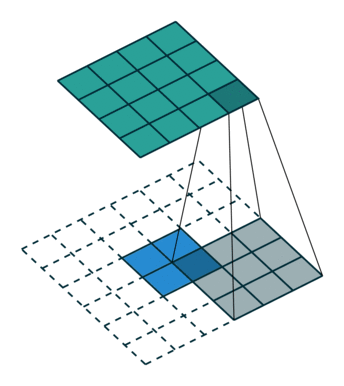
2)网络结构
下图是一个FCN的结构。
-
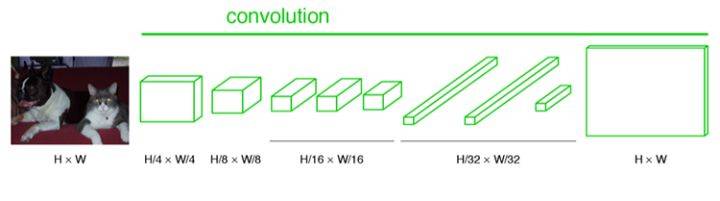
输入:H*W的图像。由于没有全连接层,网络可以接收任意维度的输入(而不是固定大小图像);
-
第1~5卷积层:执行卷积、池化操作。第一层pooling后变为原图大小的1/4,第二层变为原图大小的1/8,第五层变为原图大小的1/16,第八层变为原图大小的1/32(勘误:其实真正代码当中第一层是1/2,以此类推)。经过多次卷积和pooling以后,得到的图像越来越小,分辨率越来越低。其中图像到 $\frac{H}{32} * \frac{W}{32}$ 的时候图片是最小的一层时,所产生图叫做heatmap热图,热图就是我们最重要的高维特征图,得到高维特征的heatmap之后就是最重要的一步也是最后的一步对原图像进行upsampling,把图像进行放大、放大、放大,到原图像的大小;
-
输出:由于将全连接模型换成了卷积层,原本CNN中输出的1000*1*1维的特征变成了1000*W*H维,1000张热点图(heatmap)。在上述结构的基础上,将1000维变成21维(20种PASCAL类别+背景),再接一个反卷积层,以双线性上采样粗输出到像素密集输出,得到21张大小和原图一致的Mask,然后和真实标签逐像素比较分类结果,进行梯度下降优化。如下图右侧有狗狗和猫猫的图:

3)特征融合
FCN采用了特征融合,将粗的、高层信息与精细的、低层信息融合用来提高预测精度。融合实现方式是,对特征图进行上采样,然后将特征图对应元素相加。经过多次卷积、池化后,特征图越来越小,分辨率越来越低,为了得到和原图大小的特征图,所以需要进行上采样。作者不仅对pool5之后的特征图进行了上采样还原,也对pool4和pool3之后的特征图进行了还原,结果表明,从这些特征图能很好的获得关于图片的语义信息,而且随着特征图越来越大,效果越来越好。
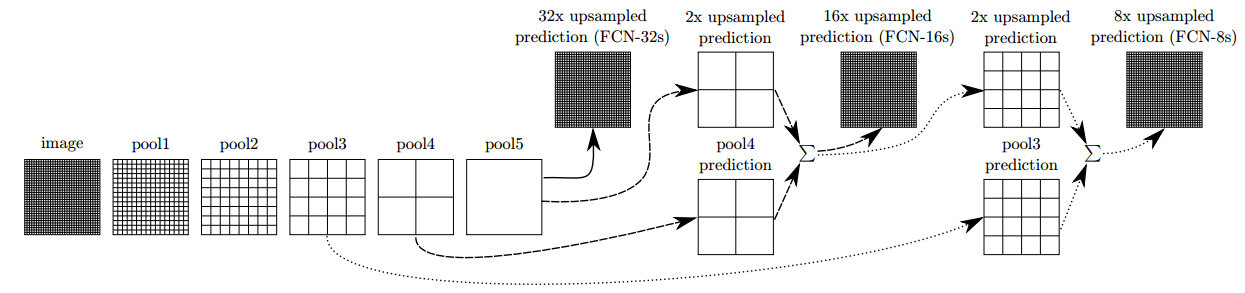
以下是不同大小特征图进行上采样,预测结果对比:

4)评价指标
作者在论文中提出了4种评价指标,即像素准确度、平均准确率、平均交并比、频率加权交并比。设$n_{ij}$为类别i预测为类别j的像素数量,有$n_{cl}$个不同的类别,类别i总共有$t_i = \Sigma_j n_{ij}$个像素,各指标具体表述如下:
- 像素准确率(Pixel Accuracy)
$$
PA = \frac{\Sigma_i n_{ii}}{\Sigma_i t_i}
$$
- 平均准确率(Mean Pixel Accuracy)
$$
MPA = \frac{1}{n_{cl}} \Sigma_i \frac{ n_{ii}}{t_i}
$$
- 平均交并比(Mean Intersection over Union)
$$
MIU = \frac{1}{n_{cl}} \Sigma_i \frac{n_{ii}}{t_i + \Sigma_j n_{ji} - n_{ii}}
$$
- 频率加权交并比(Frequency Weighted IU )
$$
FWIU = \frac{1}{\Sigma_k t_k} \Sigma_i \frac{t_i n_{ii}}{t_i + \Sigma_j n_{ji} - n_{ii}}
$$
5)结论
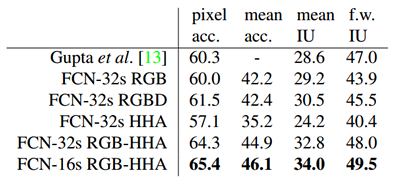
- NYUDv2数据集。该数据集包含1449个RGB-D图像。论文给出的实验结果如下(其中,FCN-32s表示未修改的粗糙模型,FCN-16s为16 stride的模型,RGB-HHA是采用了RGB和HHA融合的模型):
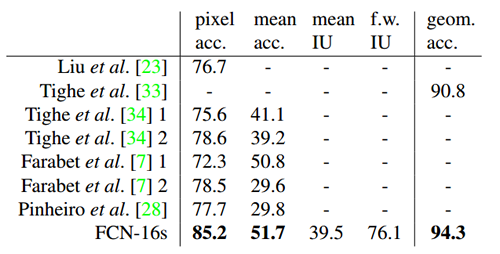
- SIFT Flow。该数据集包含2688幅图像,包含“桥”、“山”、“太阳”等33个语义类别以及“水平”、“垂直”和“天空”三个几何类别。论文给出的实验结果如下:
2. U-Net(2015)
生物医学分割是图像分割重要的应用领域。U-Net是2015年发表的用于生物医学图像分割的模型,该模型简单、高效、容易理解、容易定制,能在相对较小的数据集上实现学习。该模型在透射光显微镜图像(相衬度和DIC)上获得了2015年ISBI细胞跟踪挑战赛的冠军。该图像分割速度较快,在512x512图像实现分割只需不到一秒钟的时间。
U-Net基本实现图像分割基本原理与FCN一致,先对原图进行若干层卷积、池化,得到特征图,再对特征图进行不断上采样,并产生每个像素的类别值。
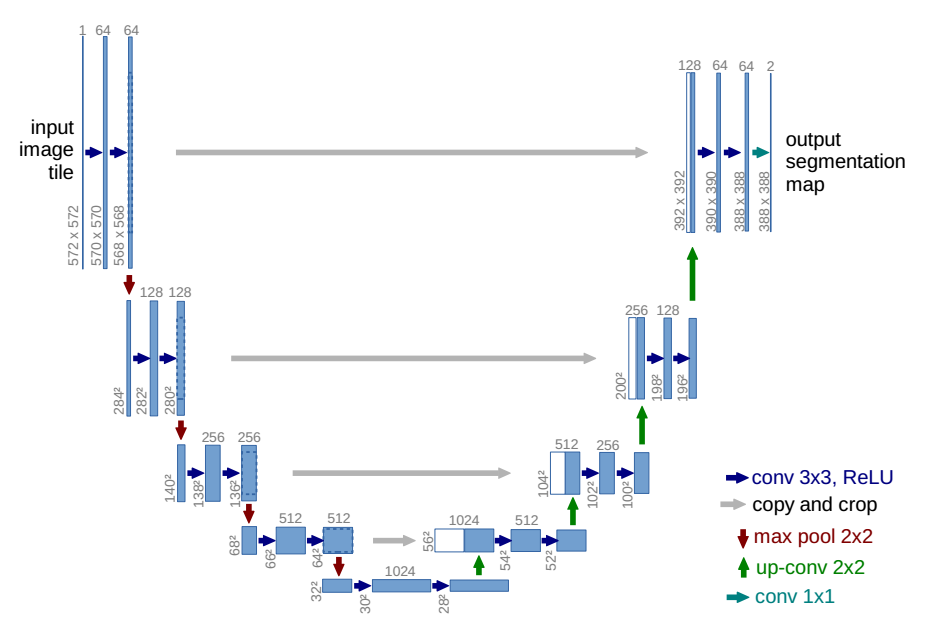
1)网络结构
U-Net网络体系结构如下图所示,它由收缩路径(左侧)和扩展路径(右侧)组成,共包含23个卷积层。
- 收缩路径遵循卷积网络的典型结构,它包括重复应用两个3x3卷积(未相加的卷积),每个卷积后面都有一个ReLU和一个2x2最大合并操作,步长为2,用于下采样。在每个下采样步骤中,特征通道的数量加倍。
- 扩展路径中的每一步都包括对特征映射进行上采样,然后进行2x2向上卷积(up-convolution ),将特征通道数量减半,与收缩路径中相应裁剪的特征映射进行串联,以及两个3x3卷积,每个卷积后面都有一个ReLU。在最后一层,使用1x1卷积将每个64分量特征向量映射到所需数量的类。
2)训练细节
- 损失函数:采用像素级交叉熵作为损失函数
- 输入:单个大的图像,而不是大的批次图像
- 输出:得到的输出图像比输入图像小,边界宽度不变
- 优化方法:随机梯度下降
- 激活函数:ReLU
- 权重初始值:标准差为$\sqrt{\frac{2}{N}}$的高斯分布(N表示一个神经元的传入节点数)
- 采用数据增强策略
3)效果
(1)任务一:电子显微镜记录中分割神经元结构
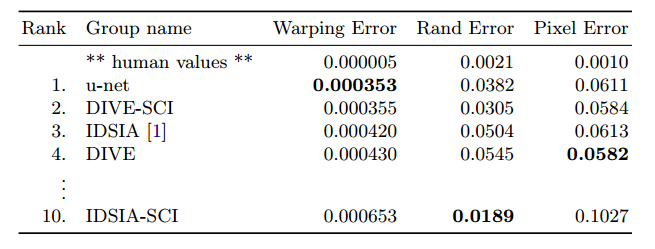
- 数据集:一组来自果蝇一龄幼虫腹侧神经索(VNC)的连续切片透射电镜图像(512x512像素)。每幅图像都有相应的完全注释的细胞(白色)和细胞膜(黑色)的真实分割图。测试集是公开的,但是它的分割图是保密的。通过将预测的膜概率图发送给组织者,可以得到评估。评估是通过在10个不同级别上对地图进行阈值化,并计算“扭曲误差”、“随机误差”和“像素误差”。
- 效果:u-net(在输入数据的7个旋转版本上的平均值)在没有任何进一步的预处理或后处理的情况下实现了0.0003529的翘曲误差(新的最佳分数,见下表)和0.0382的随机误差。
(2)任务二:u-net应用于光镜图像中的细胞分割任务
-
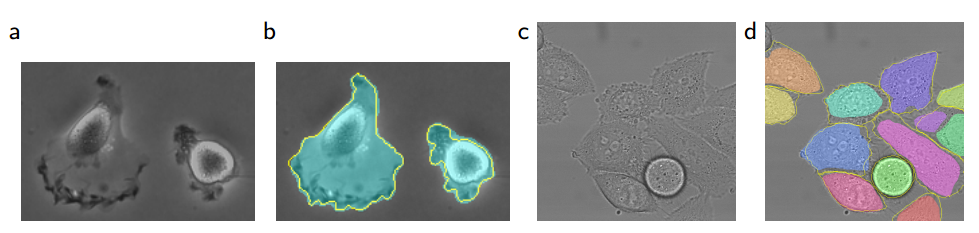
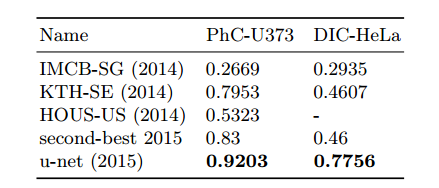
数据集:这个分离任务是2014年和2015年ISBI细胞追踪挑战赛的一部分,包含两个数据集。第一个数据集“PhC-U373”2包含由相差显微镜记录的聚丙烯腈基片上的胶质母细胞瘤星形细胞瘤U373细胞(见下图a,b),它包含35个部分注释的训练图像,该数据集下实现了92%的平均IOU;第二个数据集“DIC HeLa”3是通过差分干涉对比显微镜(DIC)记录在平板玻璃上的HeLa细胞(见下图c、d和补充材料)。它包含20个部分注释的训练图像。该数据集下实现了77.5%的平均IOU。
-
效果:见下表
3. Mask R-CNN(2017)
Mask R-CNN是一个小巧灵活的通用实例级分割框架,它不仅可对图像中的目标进行检测,还可以对每一个目标给出一个高质量的分割结果。它在Faster R-CNN基础之上进行扩展,并行地在bounding box recognition分支上添加一个用于预测目标掩模(object mask)的新分支。该网络具有良好的扩展性,很容易扩展到其它任务中,比如估计人的姿势。Mask R-CNN结构简单、准确度高、容易理解,是图像实例级分割的优秀模型。
1)主要思想
(1)**分割原理。**Mask R-CNN是在Faster R-CNN基础之上进行了扩展。Faster R-CNN是一个优秀的目标检测模型,能较准确地检测图像中的目标物体(检测到实例),其输出数据主要包含两组:一组是图像分类预测,一组是图像边框回归。Mask R-CNN在此基础上增加了FCN来产生对应的像素分类信息(称为Mask),用来描述检测出的目标物体的范围,所以Mask R-CNN可以理解为Faster R-CNN + FCN。整体结构如下图所示。
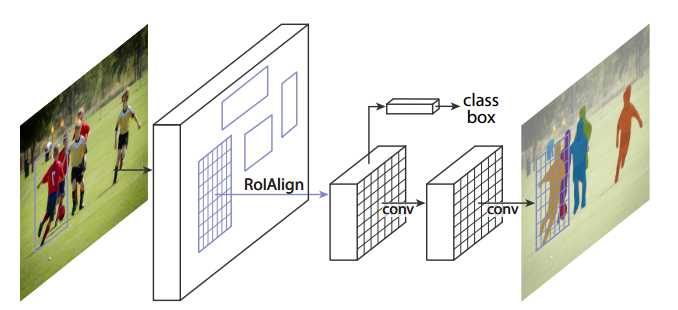
(2)算法步骤
- 输入待处理图片,进行预处理
- 将图片送入经过预训练的卷积神经网络,进行卷积运算获取图像的特征图
- 对特征图中的每个点产生ROI,从而获取多个候选区域
- 将候选区域送入RPN网络进行而分类回归(前景或背景)、边框回归,过滤掉一部分候选区域
- 对剩余的ROI进行ROIAlign操作(将原图中的像素和特征图中的点对应)
- 对这些ROI进行分类(N个类别)、边框回归、Mask生成
(3)**数据表示方式。**Mask R-CNN为每个RoI生成K个m×m的mask,其中K表示类别数量,每个mask均为二值化的矩阵,用来描述目标物体的像素范围。如下图所示:

2)网络结构
Mask R-CNN构建了多种不同结构的网络,以验证模型的适应性。论文中将网络结构分为两部分:提取特征的下层网络和产生预测结果的上层网络。如下图所示:
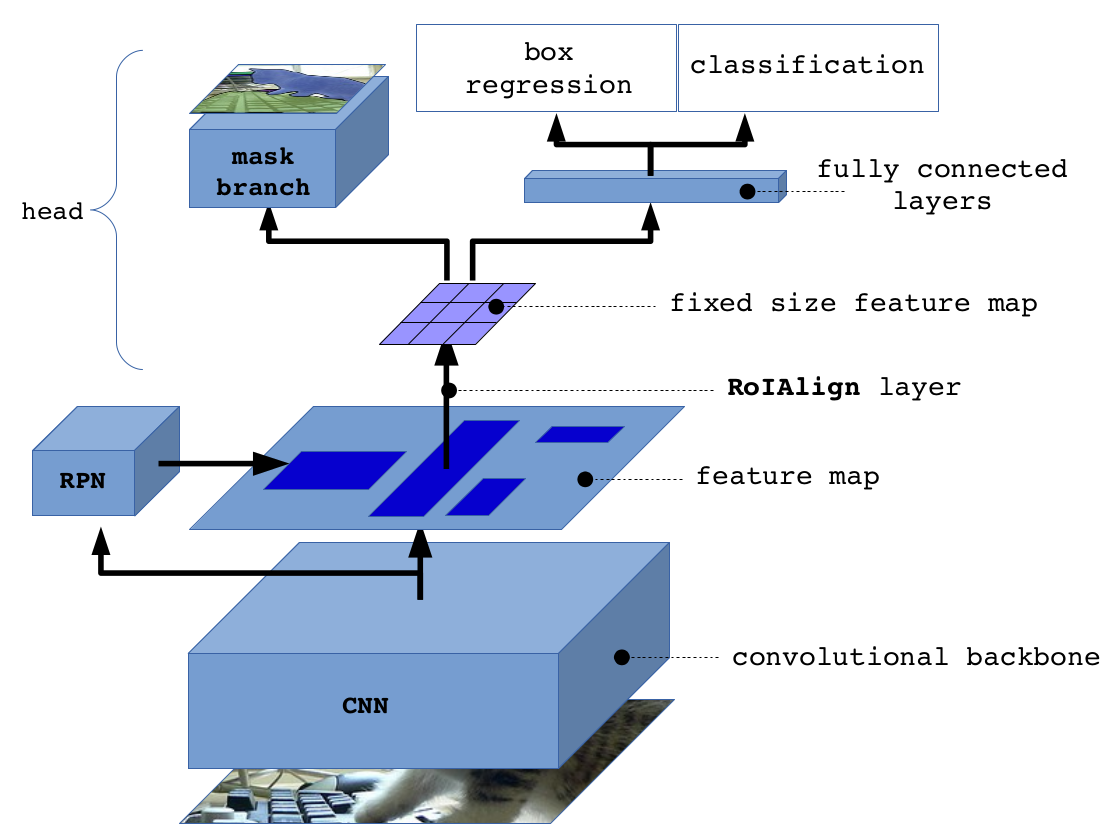
对于下层网络,论文中评估了深度为50或101层的ResNet和ResNeXt网络。
对于上层网络,主要增加了一个全卷积的掩码预测分支。如下图所示:
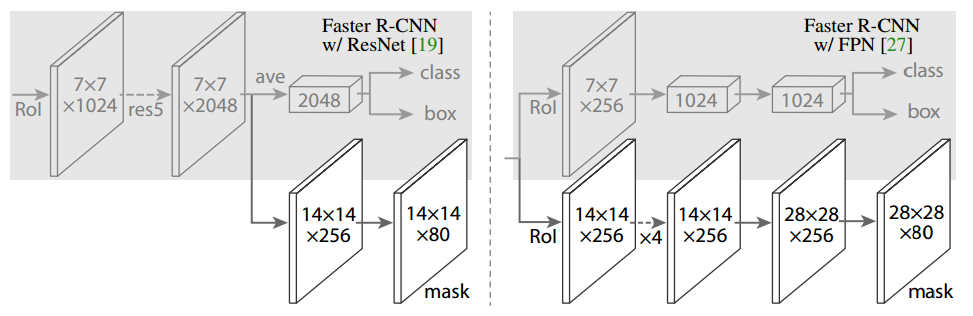
图中数字表示分辨率和通道数,箭头表示卷积、反卷积或全连接层(可以通过上下文推断,卷积减小维度,反卷积增加维度).所有的卷积都是3×3的,除了输出层,是1×1的。反卷积是2×2的,步长为2,隐藏层中使用ReLU。左图中,“res5”表示ResNet的第五阶段,为了简单起见,修改了第一个卷积操作,使用7×7,步长为1的RoI代替14×14,步长为2的RoI。右图中的“×4”表示堆叠的4个连续的卷积。
3)损失函数
Mask R-CNN损失函数由三部分构成,分类、边框回归及二值掩码。公式如下所示:
$$
L=L_{cls}+L_{box}+L_{mask}
$$
分类损失$L_{cls}$和检测框损失$L_{box}$与Faster R-CNN中定义的相同。掩码分支对于每个RoI的输出维度为$Km^2$,即K个分辨率为m×m的二值掩码,每个类别一个,K表示类别数量。每个像素应用Sigmoid,并将$L_{mask}$定义为平均二值交叉熵损失。对于真实类别为k的RoI,仅在第k个掩码上计算$L_{mask}$(其他掩码输出不计入损失)。
4)训练细节
- 与Faster R-CNN中的设置一样,如果RoI与真值框的IoU不小于0.5,则为正样本,否则为负样本。掩码损失函数$L_{mask}$仅在RoI的正样本上定义;
- 图像被缩放(较短边)到800像素,批量大小为每个GPU上2个图像,每个图像具有N个RoI采样,正负样本比例为1:3;
- 使用8个GPU训练(如此有效的批量大小为16)160k次迭代,学习率为0.02,在120k次迭代时学习率除以10。使用0.0001的权重衰减和0.9的动量;
- RPN锚点跨越5个尺度和3个纵横比。为方便剥离,RPN分开训练,不与Mask R-CNN共享特征。
5)结果
① 检测速度:5FPS
② COCO数据集实验结果
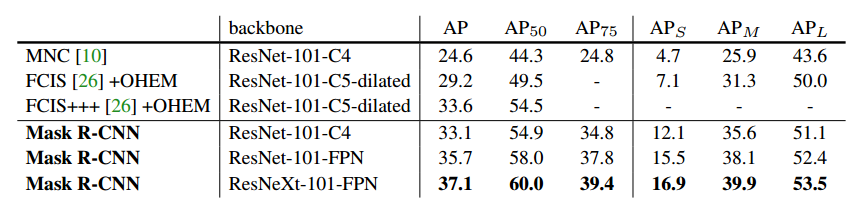
- AP:表示平均精度
- $AP_{50}$:IoU = 0.50(PASCAL VOC度量标准)
- $AP_{75}$:IoU = 0.75(严格度量标准)
- $AP_S$:小对象平均准确率(面积 < 322)
- $AP_M$:中等对象平均准确率(322 < 面积 < 962)
- $AP_L$:中等对象平均准确率(面积 > 962)
分割效果:

下图是Mask R-CNN分割效果对比。FCIS在重叠对象上有问题,Mask R-CNN则没有。

③ 人体姿态估计效果
Mask R-CNN框架可以很容易地扩展到人类姿态估计。将关键点的位置建模为one-hot掩码,并采用Mask R-CNN来预测K个掩码,每个对应K种关键点类型之一(例如左肩,右肘)。实验结果如下:
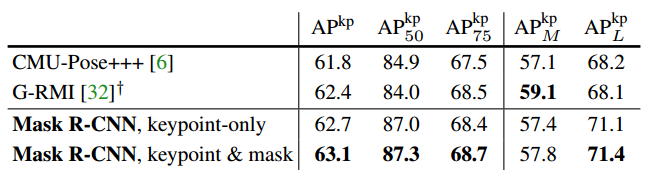
人体姿态估计效果图如下所示:

4. DeepLab系列
1)DeepLab v1(2015)
① 概述
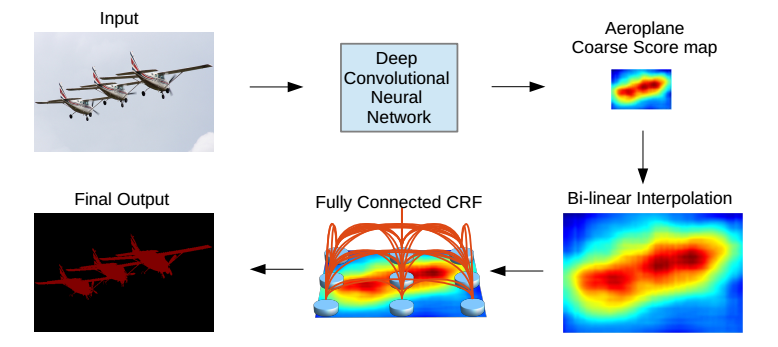
图像分割和图像分类不一样,要对图像每个像素进行精确分类。在使用CNN对图像进行卷积、池化过程中,会导致特征图尺寸大幅度下降、分辨率降低,通过低分辨率特征图上采样生成原图的像素分类信息,容易导致信息丢失,分割边界不精确。DeepLab v1采用了空洞卷积、条件随机场等技术,有效提升了分割准确率。在 Pascal VOC 2012 的测试集 IOU 上达到了 71.6%,排名第一。
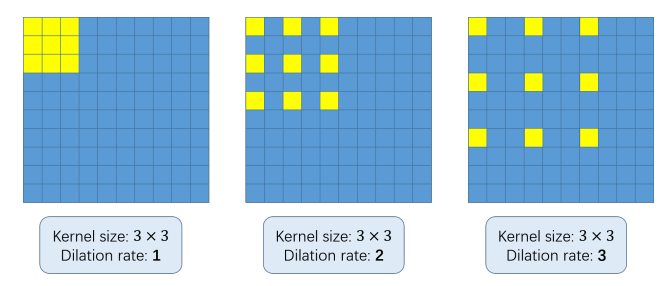
② 空洞卷积
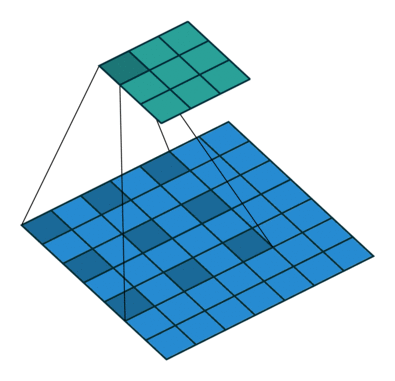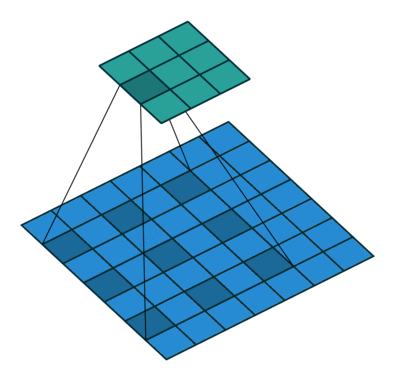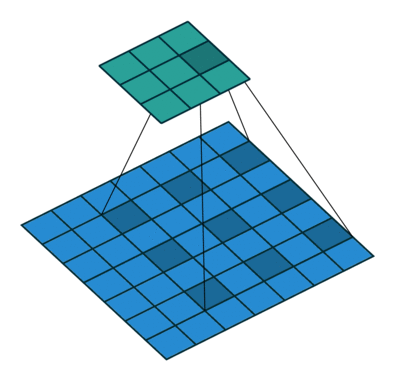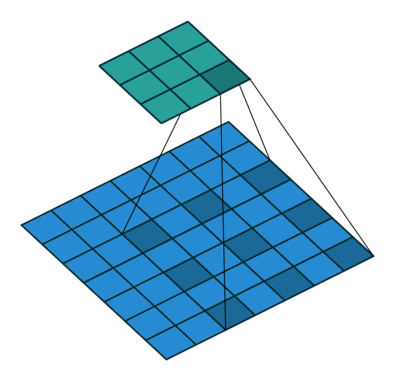
Dilated/Atrous Convolution(中文叫做空洞卷积或者膨胀卷积) ,是在标准的 convolution map 里注入空洞,以此来增加感受野。以下是一个空洞卷积示例图:
③ 条件随机场
条件随机场(Conditional random field,CRF)是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机变量构成马尔可夫随机场。
马尔科夫随机场是具有马尔科夫特性的随机场。马尔科夫性质指的是一个随机变量序列按时间先后关系依次排开的时候,第N+1时刻的分布特性,与N时刻以前的随机变量的取值无关。拿天气来打个比方。如果我们假定天气是马尔可夫的,其意思就是我们假设今天的天气仅仅与昨天的天气存在概率上的关联,而与前天及前天以前的天气没有关系。其它如传染病和谣言的传播规律,就是具有马尔可夫性质的。
④ 网络结构
DeepLab v1使用VGG-16作为基础模型,为了更适合图像分割任务,做出了以下修改:
- 将最后三个全连接层(fc6, fc7, fc8)改成卷积层
- 将最后两个池化层(pool4, pool5)步长由2改成1
- 将最后三个卷积层(conv5_1, conv5_2, conv_3)的dilate rate 设置为2
- 输出层通道数改为21(20个类别,1个背景)
⑤ 能量函数
- 自对比试验
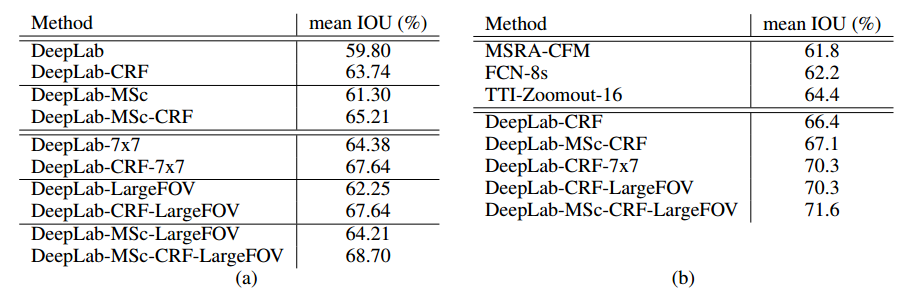
左表为采用不同策略下的IOU均值,其中,MSc表示多尺度融合,CRF表示条件随机场,LargFOV表大范围视野。右表为其它模型与该模型各种策略对比。
- 与FCN-8s和TTI-Zoomout-16的效果对比

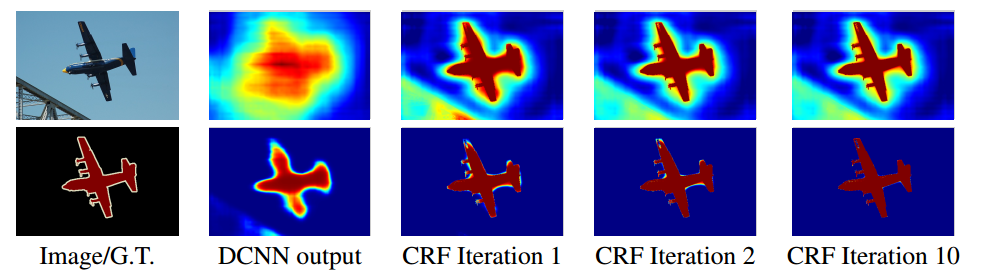
从上到下依次为原图、真实标记、被对比的模型分割效果、DeepLab-CRF分割效果。
2)DeepLab v2(2017)
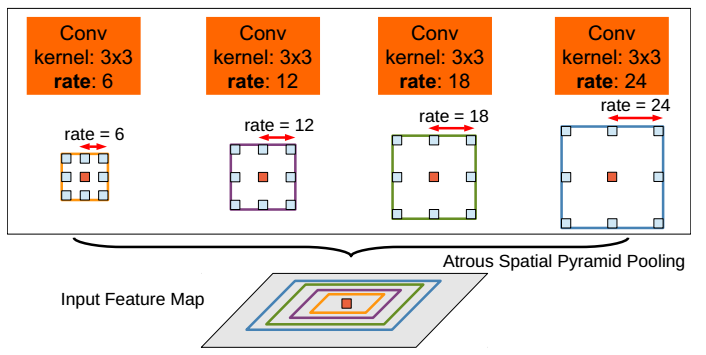
DeepLab v2在DeepLab v1的基础上,主要引入了ASPP(Atrous Spatial Pyramid Pooling,膨胀空间金字塔池化)策略,在给定的输入上以不同采样率的空洞卷积并行采样,相当于以多个比例捕捉图像的上下文,从而获得更好的分割性能。ASPP原理如下图所示:
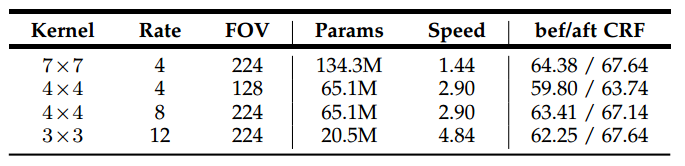
以下是PASCAL VOC 2012数据集上不同kernel size以及不同大小的膨胀率(atrous sampling rate)的实验对比:
以下是PASCAL VOC 2012数据集上分割效果展示:

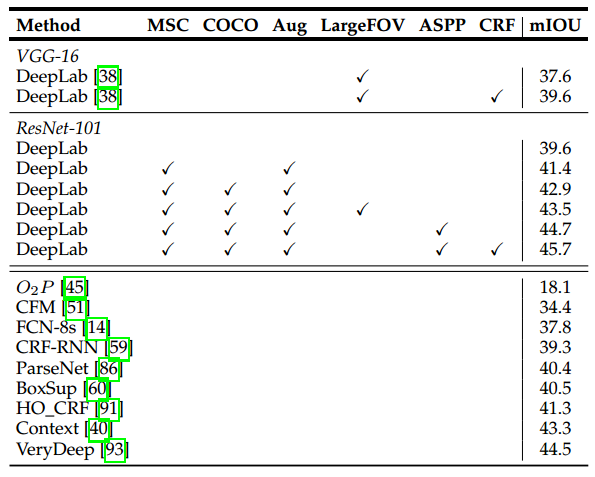
以下是使用ResNet-101在PASCAL VOC 2012数据集上的实验对比:

其中,MSC表示多尺度输入最大融合,COCO表示采用在MS-COCO上预训练的模型,Aug表示通过随机缩放增加数据。以下是跟其它模型的对比:
以下是在Cityscapes数据集上的分割效果:
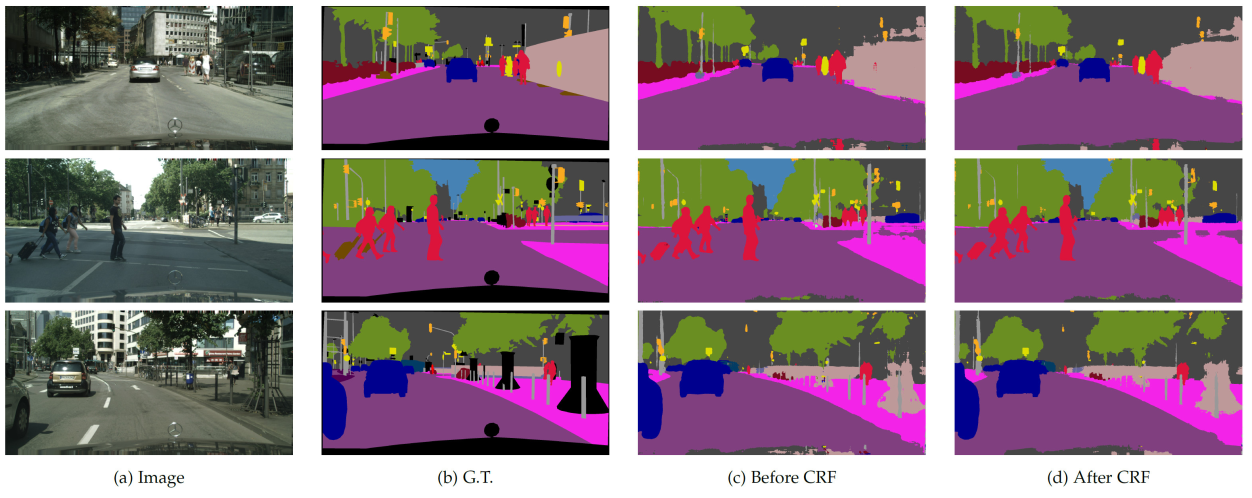
以下是分割失败的示例:

3)DeepLab v3(2017)
在DeepLab v3中,主要进行了以下改进:
- 使用更深的网络结构,以及串联不同膨胀率的空洞卷积,来获取更多的上下文信息
- 优化Atrous Spatial Pyramid Pooling
- 去掉条件随机场
① 串联结构
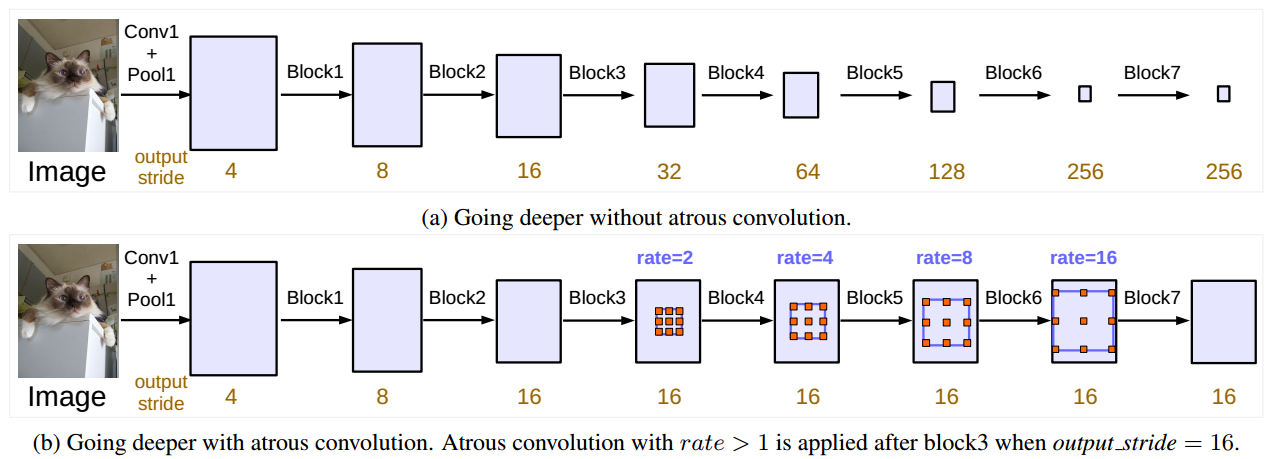
上图演示了ResNet结构中,不使用空洞卷积(上)和使用不同膨胀率的空洞卷积(下)的差异,通过在Block3后使用不同膨胀率的空洞卷积,保证在扩大视野的情况下,保证特征图的分辨率。
② 并行结构
作者通过实验发现,膨胀率越大,卷积核中的有效权重越少,当膨胀率足够大时,只有卷积核最中间的权重有效,即退化成了1x1卷积核,并不能获取到全局的context信息。为了解决这个问题,作者在最后一个特征上使用了全局平均池化(global everage pooling)(包含1x1卷积核,输出256个通道,正则化,通过bilinear上采样还原到对应尺度)。修改后的ASPP结构图如下:
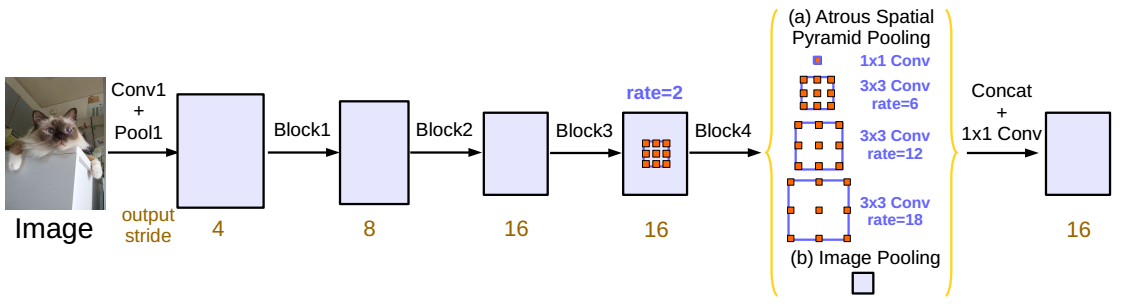
③ Mult-grid策略
作者考虑了multi-grid方法,即每个block中的三个卷积有各自unit rate,例如Multi Grid = (1, 2, 4),block的dilate rate=2,则block中每个卷积的实际膨胀率=2* (1, 2, 4)=(2,4,8)。
④ 训练策略
- 采用变化的学习率,学习率衰减策略如下(其中,power设置为0.9):
$$
(1 - \frac{iter}{max_iter})^{power}
$$
- 裁剪。在训练和测试期间,在PASCAL VOC 2012数据集上采用的裁剪尺寸为513,以保证更大的膨胀率有效。
- Batch Normalization。先在增强数据集上output stride = 16(输入图像与输出特征大小的比例),batch size=16,BN参数衰减为0.9997,训练30k个iter。之后在官方PASCAL VOC 2012的trainval集上冻结BN参数, output stride = 8,batch size=8,训练30k个iter。
- 采用上采样真值计算Loss。DeepLabv1/v2中都是下采样的真值来计算loss,这样会让细节标记产生损失,本模型使用上采样最后的输出结果计算。
- 数据随机处理。在训练阶段,对输入的图像进行随机缩放(缩放率在0.5-2.0之间),并随机执行左右翻转。
⑤ 效果
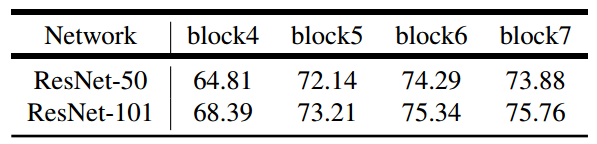
-
ResNet-50和ResNet-101结构比较,更多的级联采样能获得 更高的性能
-
各种优化测略效果实验
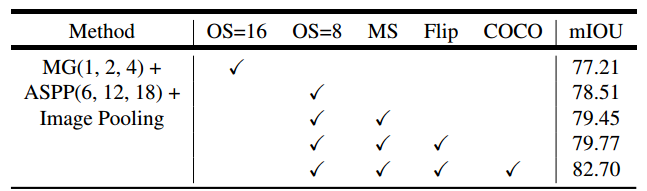
其中,MG表示Multi-grid,ASPP 表示Atrous spatial pyramid pooling ,OS表示output stride ,MS表示Multiscale inputs during test ,Flip表示镜像增强,COCO表示MS-COCO 预训练模型。
-
其它模型对比(PASCAL VOC 2012 测试集)
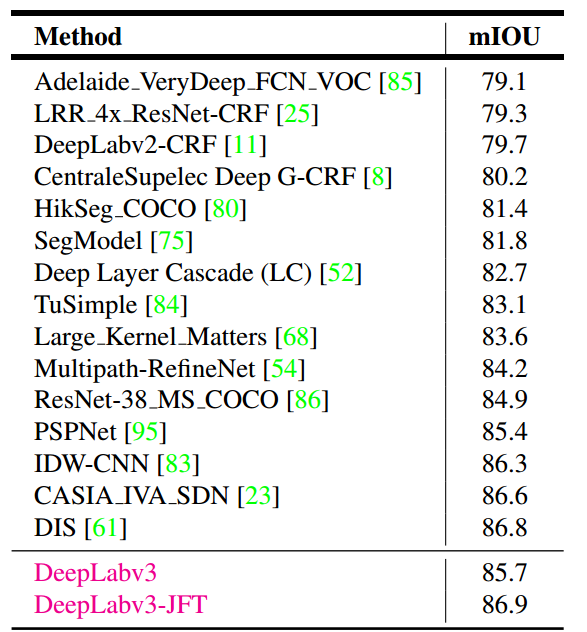
-
分割效果展示

4)DeepLab v3+
① 深度可分离卷积
采用深度可分离卷积,大幅度降低参数数量。
② 网络结构
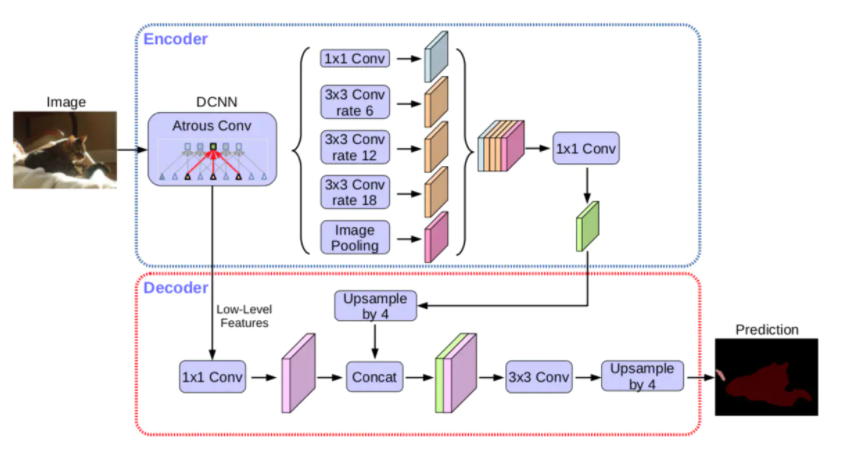
-
Encoder:同DeepLabv3。
-
Decoder:先把encoder的结果上采样4倍,然后与resnet中下采样前的Conv2特征进行concat融合,再进行3*3卷积,最后上采样4倍得到输出结果。
-
融合低层次信息前,先进行1*1卷积,目的是减少通道数,进行降维。
-
主干网部分:采用更深的Xception网络,所有max pooling结构为stride=2的深度可卷积代替;每个3*3的depthwise卷积都跟BN和Relu。改进后的主干网结构如下:
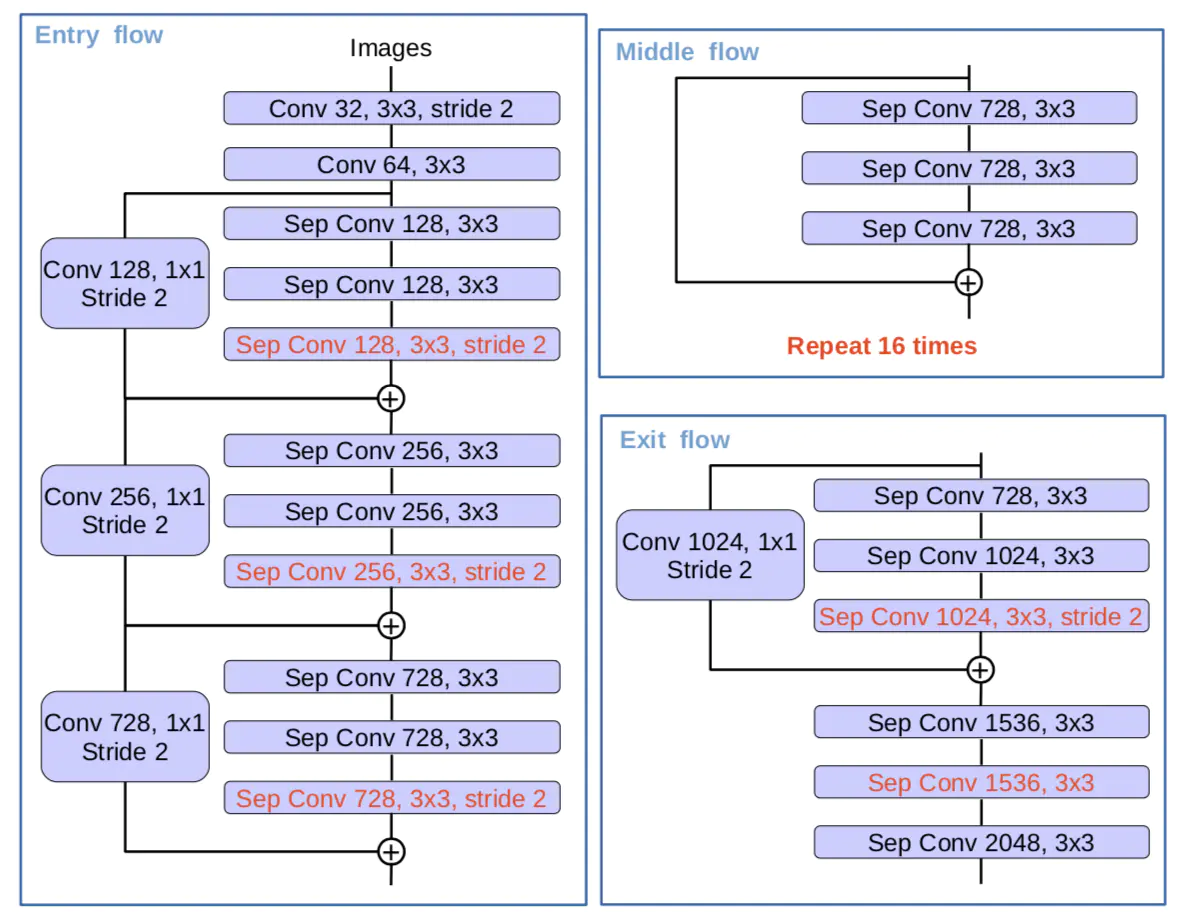
③ 结果
-
与其它模型的对比
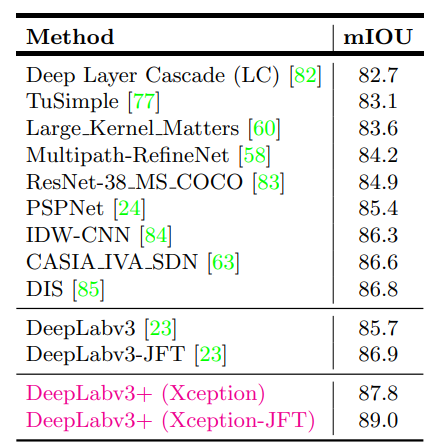
-
在Cityspaces数据集上实验结果如下:
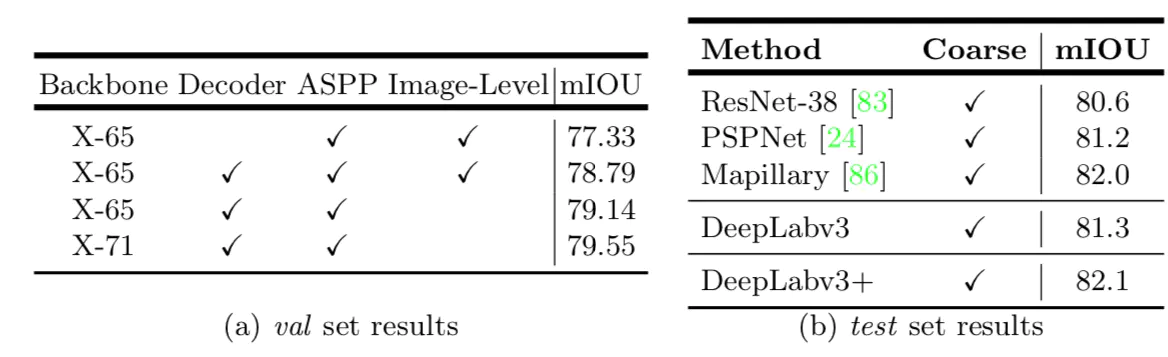
-
分割效果展示(最后一行是失败的分割)

5. 其它模型
四、数据集
1. VOC2012
Pascal VOC 2012:有 20 类目标,这些目标包括人类、机动车类以及其他类,可用于目标类别或背景的分割。
2. MSCOCO
是一个新的图像识别、分割和图像语义数据集,是一个大规模的图像识别、分割、标注数据集。它可以用于多种竞赛,与本领域最相关的是检测部分,因为其一部分是致力于解决分割问题的。该竞赛包含了超过80个物体类别。
3. Cityscapes
50 个城市的城市场景语义理解数据集,适用于汽车自动驾驶的训练数据集,包括19种都市街道场景:road、side-walk、building、wal、fence、pole、traficlight、trafic sign、vegetation、terain、sky、person、rider、car、truck、bus、train、motorcycle 和 bicycle。该数据库中用于训练和校验的精细标注的图片数量为3475,同时也包含了 2 万张粗糙的标记图片。
4. Pascal Context
有 400 多类的室内和室外场景。
5. Stanford Background Dataset
至少有一个前景物体的一组户外场景。
五、语义分割标注工具
1)labelme
-
安装
1
pip3 install labelme
-
运行
1
labelme
-
运行界面

六、代码实现
附录:术语表
| 英文简称 | 英文全称 | 中文名称 |
|---|---|---|
| ASPP | astrous spatial pyramid pooling | 空洞金字塔池化 |
| FOV | Field of View | 视野 |
| CRF | Fully-connected Conditional Random Field | 全连接条件随机场 |
| DSC | Depthwise Separable Convolution | 深度可分离卷积 |



