一、概述
生成对抗网络(Generative Adversarial Networks)是一种无监督深度学习模型,用来通过计算机生成数据,由Ian J. Goodfellow等人于2014年提出。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。生成对抗网络被认为是当前最具前景、最具活跃度的模型之一,目前主要应用于样本数据生成、图像生成、图像修复、图像转换、文本生成等方向。
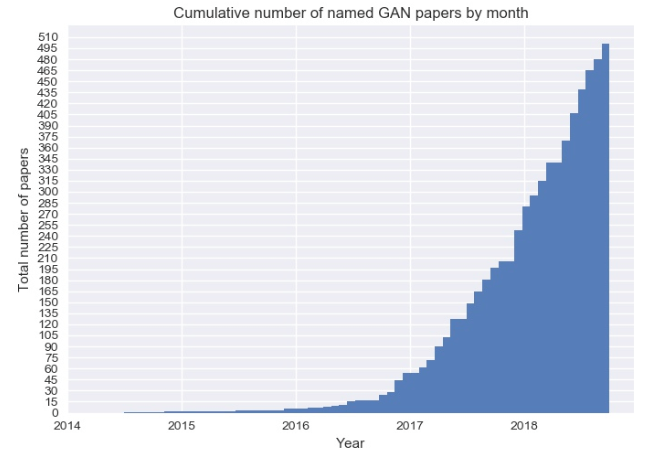
GAN这种全新的技术在生成方向上带给了人工智能领域全新的突破。在之后的几年中生GAN成为深度学习领域中的研究热点,近几年与GAN有关的论文数量也急速上升,目前数量仍然在持续增加中。
二、GAN基本原理
1. 构成
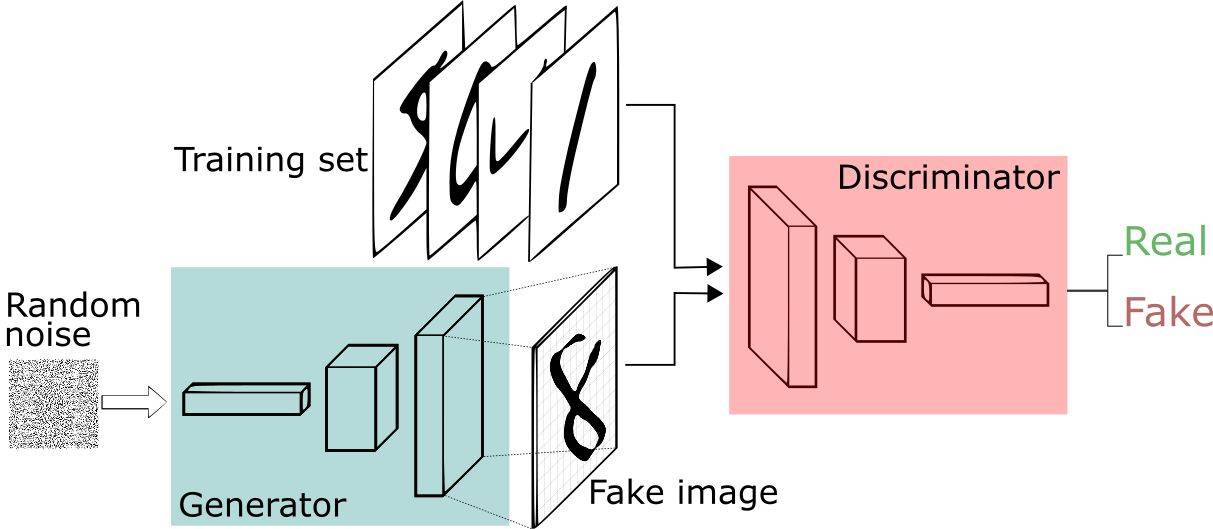
GAN由两个重要的部分构成:生成器(Generator,简写作G)和判别器(Discriminator,简写作D)。
- 生成器:通过机器生成数据,目的是尽可能“骗过”判别器,生成的数据记做G(z);
- 判别器:判断数据是真实数据还是「生成器」生成的数据,目的是尽可能找出「生成器」造的“假数据”。它的输入参数是x,x代表数据,输出D(x)代表x为真实数据的概率,如果为1,就代表100%是真实的数据,而输出为0,就代表不可能是真实的数据。
这样,G和D构成了一个动态对抗(或博弈过程),随着训练(对抗)的进行,G生成的数据越来越接近真实数据,D鉴别数据的水平越来越高。在理想的状态下,G可以生成足以“以假乱真”的数据;而对于D来说,它难以判定生成器生成的数据究竟是不是真实的,因此D(G(z)) = 0.5。训练完成后,我们得到了一个生成模型G,它可以用来生成以假乱真的数据。
- 第一阶段:固定「判别器D」,训练「生成器G」。使用一个性能不错的判别器,G不断生成“假数据”,然后给这个D去判断。开始时候,G还很弱,所以很容易被判别出来。但随着训练不断进行,G技能不断提升,最终骗过了D。这个时候,D基本属于“瞎猜”的状态,判断是否为假数据的概率为50%。
- 第二阶段:固定「生成器G」,训练「判别器D」。当通过了第一阶段,继续训练G就没有意义了。这时候我们固定G,然后开始训练D。通过不断训练,D提高了自己的鉴别能力,最终他可以准确判断出假数据。
- 重复第一阶段、第二阶段。通过不断的循环,「生成器G」和「判别器D」的能力都越来越强。最终我们得到了一个效果非常好的「生成器G」,就可以用它来生成数据。
3. GAN的优缺点
1)优点
- 能更好建模数据分布(图像更锐利、清晰);
- 理论上,GANs 能训练任何一种生成器网络。其他的框架需要生成器网络有一些特定的函数形式,比如输出层是高斯的;
- 无需利用马尔科夫链反复采样,无需在学习过程中进行推断,没有复杂的变分下界,避开近似计算棘手的概率的难题。
2)缺点
- 模型难以收敛,不稳定。生成器和判别器之间需要很好的同步,但是在实际训练中很容易D收敛,G发散。D/G 的训练需要精心的设计。
- 模式缺失(Mode Collapse)问题。GANs的学习过程可能出现模式缺失,生成器开始退化,总是生成同样的样本点,无法继续学习。
4. GAN的应用
1)生成数据集
人工智能的训练是需要大量的数据集,可以通过GAN自动生成低成本的数据集。
2)人脸生成

3)物品生成

4)图像转换
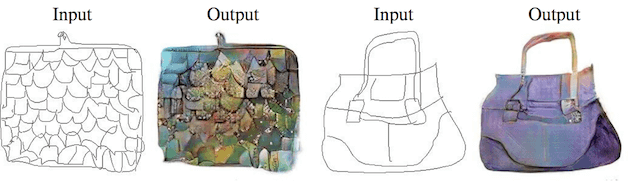
5)图像修复

三、GAN的数学原理
1.GAN的数学推导
生成模型会从一个输入空间将数据映射到生成空间(即通过输入数据,在函数作用下生成输出数据),写成公式的形式是x=G(z)。通常,输入z会满足一个简单形式的随机分布(比如高斯分布或者均匀分布等),为了使得生成的数据分布能够尽可能地逼近真实数据分布,生成函数G会是一个神经网络的形式,通过神经网络可以模拟出各种完全不同的分布类型。
以下是生成对抗网络中的代价函数,以判别器D为例,代价函数写作$J^{(D)}$,形式如下所示:
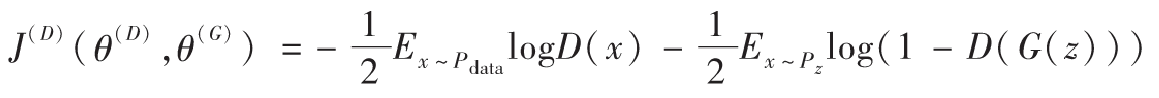
其中,E表示期望概率,$x \sim P_{data}$表示x满足$P_{data}$分布。
对于生成器来说它与判别器是紧密相关的,我们可以把两者看作一个零和博弈,它们的代价综合应该是零,所以生成器的代价函数应满足如下等式:
$$
J^{(G)} = -J^{(D)}
$$
这样一来,我们可以设置一个价值函数V来表示$J^{(G)}$和$J^{(D)}$:
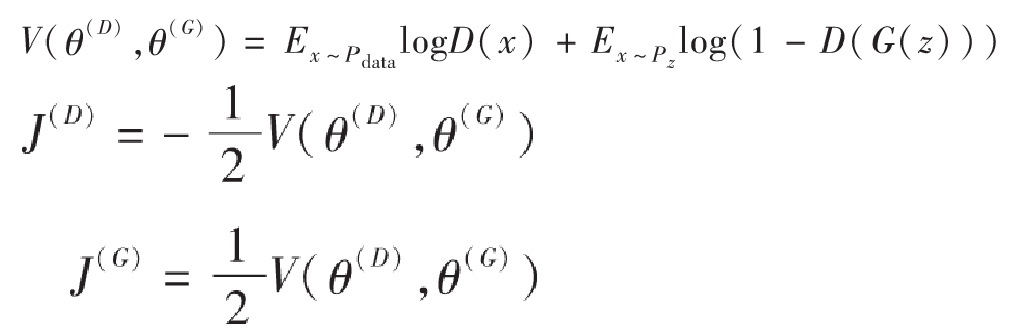
我们现在把问题变成了需要寻找一个合适的$V(θ^{(D)},θ^{(G)})$使得$J^{(G)}$和$J^{(D)}$都尽可能小,也就是说对于判别器而言越大越$V(θ^{(D)},θ^{(G)})$好,而对于生成器来说则是越小越好$V(θ^{(D)},θ^{(G)})$,从而形成了两者之间的博弈关系。
在博弈论中,博弈双方的决策组合会形成一个纳什平衡点(Nash equilibrium),在这个博弈平衡点下博弈中的任何一方将无法通过自身的行为而增加自己的收益。在生成对抗网络中,我们要计算的纳什平衡点正是要寻找一个生成器G与判别器D使得各自的代价函数最小,从上面的推导中也可以得出我们希望找到一个$V(θ^{(D)},θ^{(G)})$对于生成器来说最小而对判别器来说最大,我们可以把它定义成一个寻找极大极小值的问题,公式如下所示:
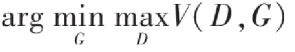
我们可以用图形化的方法理解一下这个极大极小值的概念,一个很好的例子就是鞍点(saddle point),如下图所示,即在一个方向是函数的极大值点,而在另一个方向是函数的极小值点。
在上面公式的基础上,我们可以分别求出理想的判别器D*和生成器G*:
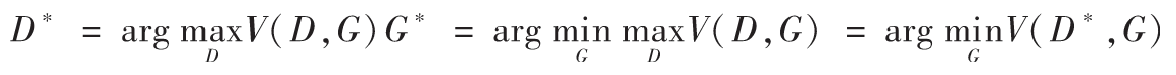
下面我们先来看一下如何求出理想的判别器,对于上述的D*,我们假定生成器G是固定的,令式子中的G(z)=x。推导如下:
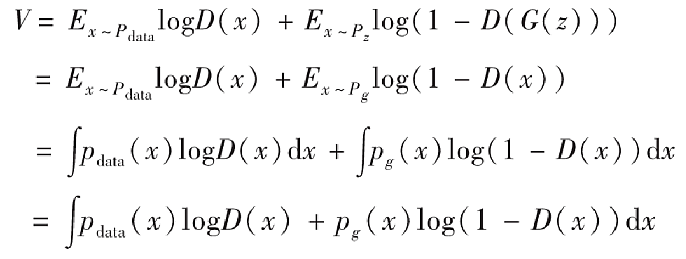
我们现在的目标是希望寻找一个D使得V最大,我们希望对于积分中的项$f(x)=p_{data}(x)logD(x)+p_g(x)log(1-D(x))$,无论x取何值都能最大。其中,我们已知$p_data$是固定的,之前我们也假定生成器G固定,所以$p_g$也是固定的,所以我们可以很容易地求出D以使得f(x)最大。我们假设x固定,f(x)对D(x)求导等于零,下面是求解D(x)的推导。
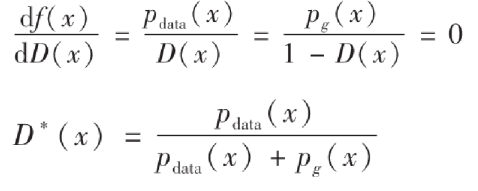
可以看出它是一个范围在0到1的值,这也符合我们判别器的模式,理想的判别器在接收到真实数据时应该判断为1,而对于生成数据则应该判断为0,当生成数据分布与真实数据分布非常接近的时候,应该输出的结果为1/2.
找到了D*之后,我们再来推导一下生成器G*。现在先把D*(x)代入前面的积分式子中重新表示:
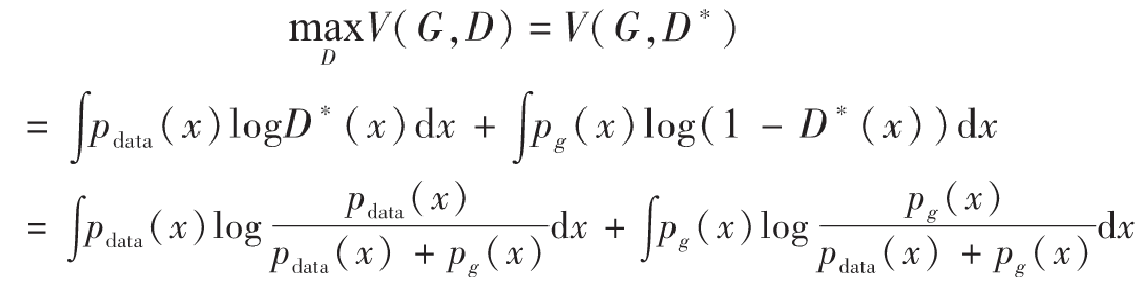
到了这一步,我们需要先介绍一个定义——Jensen–Shannon散度,我们这里简称JS散度。在概率统计中,JS散度也与前面提到的KL散度一样具备了测量两个概率分布相似程度的能力,它的计算方法基于KL散度,继承了KL散度的非负性等,但有一点重要的不同,JS散度具备了对称性。JS散度的公式如下,我们还是以P和Q作为例子,另外我们设定$M=\frac{1}{2}(P+Q)$,KL为KL散度公式。
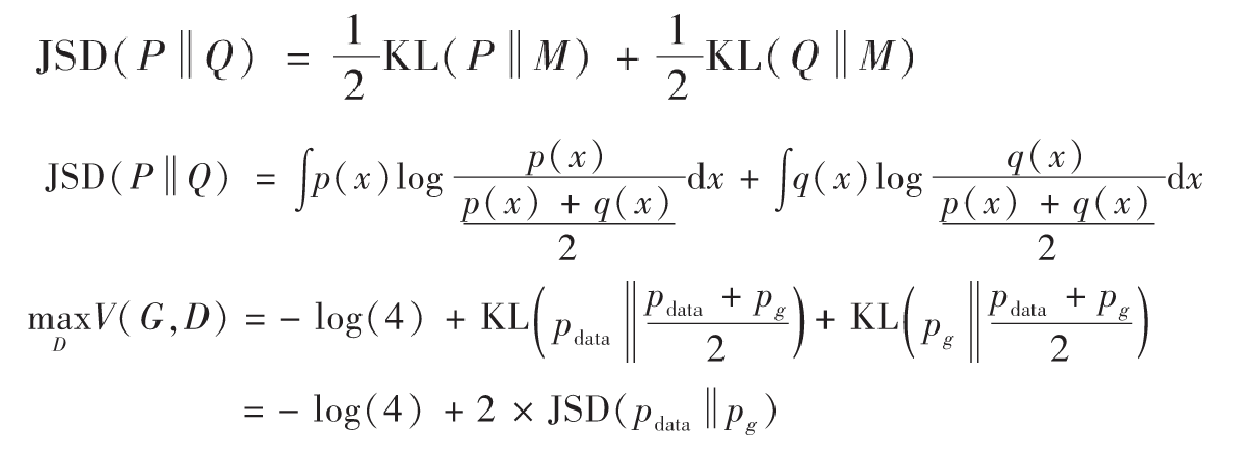
对于上面的$MaxV(G,D)$,由于JS散度是非负的,当且仅当$p_{data}=p_g$的时候,上式可以取得全局最小值$-log(4)$。所以我们要求的最优生成器G*,正是要使得G*的分布$p_g=p_{data}$.
2. GAN的可视化理解
下面我们用一个可视化概率分布的例子来更深入地认识一下生成对抗网络。Ian Goodfellow的论中给出了这样一个GAN的可视化实现的例子:下图中的点线为真实数据分布,曲线为生成数据样本,生成对抗网络在这个例子中的目标在于,让曲线(也就是生成数据的分布)逐渐逼近点线(代表的真实数据分布)。
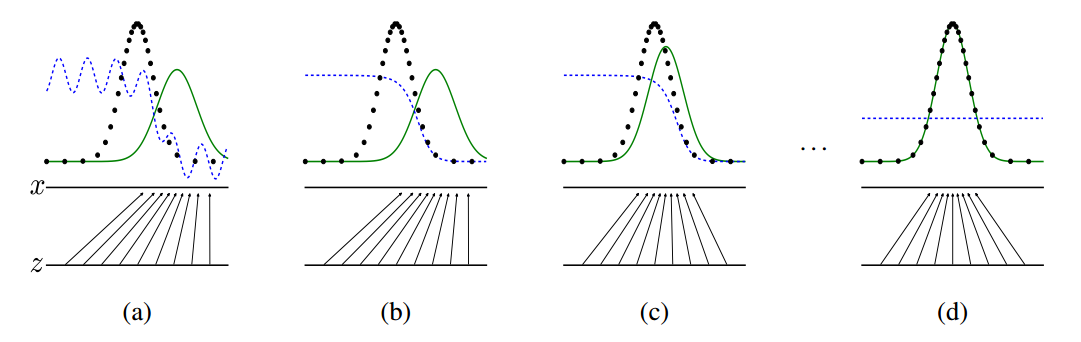
虚线为生成对抗网络中的判别器,它被赋予了初步区分真实数据与生成数据的能力,并对于它的划分性能加上一定的白噪声,使得模拟环境更为真实。输入域为z(图中下方的直线)在这个例子里默认为一个均匀分布的数据,生成域为x(图中上方的直线)为不均匀分布数据,通过生成函数x=G(z)形成一个映射关系,如图中的那些箭头所示,将均匀分布的数据映射成非均匀数据。
从a到d的四张图可以展现整个生成对抗网络的运作过程。在a图中,可以说是一种初始的状态,生成数据与真实数据还有比较大的差距,判别器具备初步划分是否为真实数据的能力,但是由于存在噪声,效果仍有缺陷。b图中,通过使用两类标签数据对于判别器的训练,判别器D开始逐渐向一个比较完善的方向收敛,最终呈现出图中的结果。当判别器逐渐完美后,我们开始迭代生成器G,如图c所示。通过判别器D的倒数梯度方向作为指导,我们让生成数据向真实数据的分布方向移动,让生成数据更容易被判别器判断为真实数据。在反复的一系列上述训练过程后,生成器与判别器会进入图d的最终状态,此时$p_g$会非常逼近甚至完全等于$p_{data}$,当达到理想的$p_g=p_{data}$的时候,D与G都已经无法再更进一步优化了,此时G生成的数据已经达到了我们期望的目的,能够完全模拟出真实数据的分布,而D在这个状态下已经无法分辨两种数据分布(因为它们完全相同),此时$D(x)=\frac{1}{2}$.
四、DCGAN
1. 概述
DCGAN的创始论文《Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks》(基于深层卷积生成对抗网络的无监督表示学习)发表于2015年,文章在GAN的基础之上提出了全新的DCGAN架构,该网络在训练过程中状态稳定,并可以有效实现高质量的图片生成及相关的生成模型应用。由于其具有非常强的实用性,在它之后的大量GAN模型都是基于DCGAN进行的改良版本。为了使得GAN能够很好地适应于卷积神经网络架构,DCGAN提出了四点架构设计规则,分别是:
- 使用卷积层替代池化层。首先第一点是把传统卷积网络中的池化层全部去除,使用卷积层代替。对于判别器,我们使用步长卷积(strided convolution)来代替池化层;对于生成器,我们使用分数步长卷积(fractional-strided convolutions)来代替池化层。
- 去除全连接层。目前的研究趋势中我们会发现非常多的研究都在试图去除全连接层,常规的卷积神经网络往往会在卷积层后添加全连接层用以输出最终向量,但我们知道全连接层的缺点在于参数过多,当神经网络层数深了以后运算速度会变得非常慢,此外全连接层也会使得网络容易过度拟合。有研究使用了全局平均池化(global average pooling)来替代全连接层,可以使得模型更稳定,但也影响了收敛速度。论文中说的一种折中方案是将生成器的随机输入直接与卷积层特征输入进行连接,同样地对于判别器的输出层也是与卷积层的输出特征连接,具体的操作会在后面的框架结构介绍中说明。
- 使用批归一化(batch normalization)。由于深度学习的神经网络层数很多,每一层都会使得输出数据的分布发生变化,随着层数的增加网络的整体偏差会越来越大。批归一化的目标则是为了解决这一问题,通过对每一层的输入进行归一化处理,能够有效使得数据服从某个固定的数据分布。
- 使用恰当的激活函数。在DCGAN网络框架中,生成器和判别器使用了不同的激活函数来设计。生成器中使用ReLU函数,但对于输出层使用了Tanh激活函数,因为研究者们在实验中观察到使用有边界的激活函数可以让模型更快地进行学习,并能快速覆盖色彩空间。而在判别器中对所有层均使用LeakyReLU,在实际使用中尤其适用于高分辨率的图像判别模型。这些激活函数的选择是研究者在多次实验测试中得出的结论,可以有效使得DCGAN得到最优的结果。
2. 网络结构
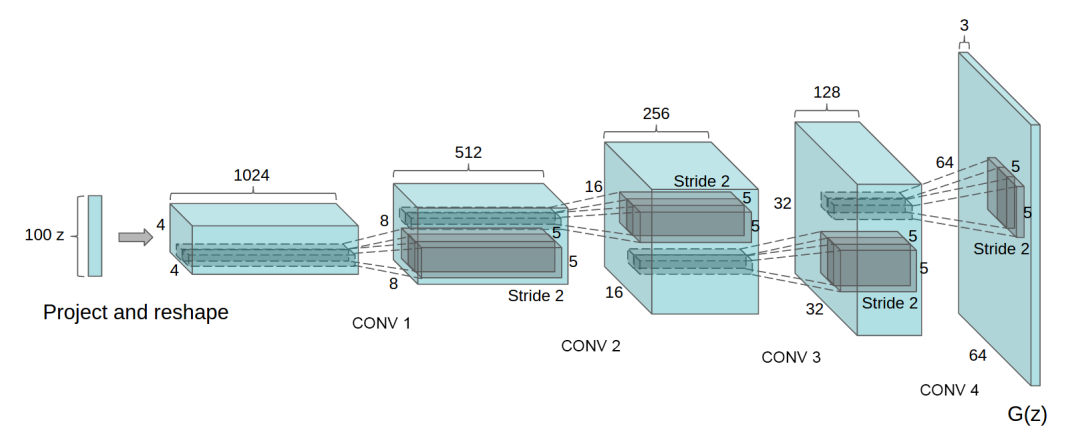
下图是DCGAN生成器G的架构图,输入数据为100维的随机数据z,服从范围在[-1,1]的均匀分布,经过一系列分数步长卷积后,最后形成一幅64×64×3的RGB图片,与训练图片大小一致。
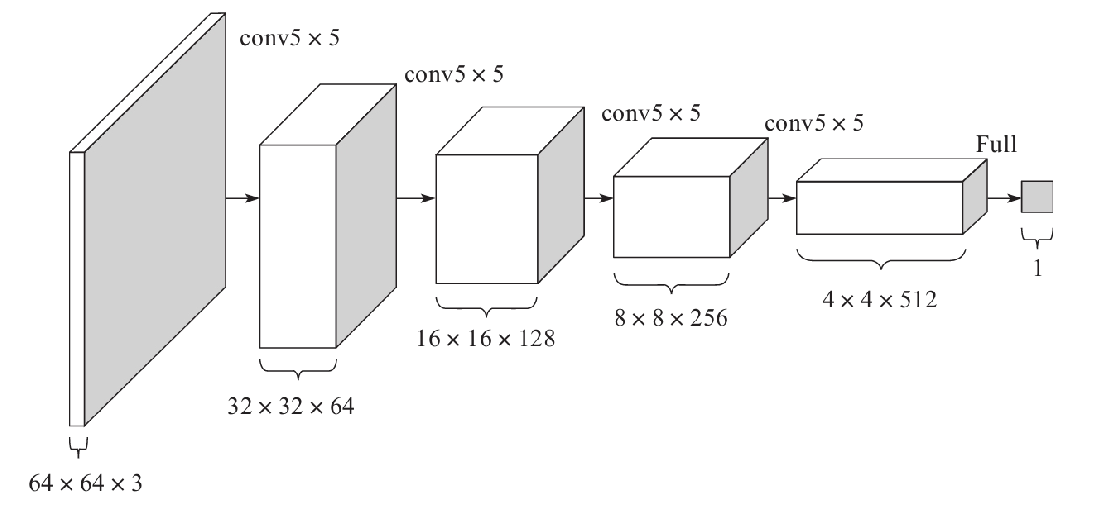
对于判别器D的架构,基本是生成器G的反向操作,如下图所示。输入层为64×64×3的图像数据,经过一系列卷积层降低数据的维度,最终输出的是一个二分类数据。
3. 训练细节
1)对于用于训练的图像数据样本,仅将数据缩放到[-1,1]的范围内,这个也是tanh的取值范围,并不做任何其他处理。
2)模型均采用Mini-Batch大小为128的批量随机梯度下降方法进行训练。权重的初始化使用满足均值为0、方差为0.02的高斯分布的随机变量。
3)对于激活函数LeakyReLU,其中Leak的部分设置斜率为0.2。
4)训练过程中使用Adam优化器进行超参数调优。学习率使用0.0002,动量β1取0.5,使得训练更加稳定。
五、实现DCGAN
1. 任务目标
实现DCGAN,并利用其合成卡通人物头像。
2. 数据集
样本内容:卡通人物头像
样本数量:51223个
![]()
3. 代码清单
1 | import os |
2)avatar_model.py
1 | # DCGAN |
3)avatar_train.py
1 | from avatar_model import AvatarModel # wdb 20200325 |
4)avatar_gen.py
1 | from avatar_model import AvatarModel # wdb 20200325 |
4. 实验结果
为了加快训练速度,实际只采用了8903个样本进行训练,执行每20轮一次增量训练。实验结果如下:
- 1轮训练
![]()
- 5轮训练
![]()
- 10轮训练
![]()
- 20轮训练
![]()
- 40轮训练
![]()
- 60轮训练
![]()
六、其它GAN模型
1)文本生成图像:GAWWN
2)匹配数据图像转换:Pix2Pix

3)非匹配数据图像转换:CycleGAN,用于实现两个领域图片互转

4)多领域图像转换:StarGAN

七、参考资源
1. 在线视频
1)李宏毅GAN教程:https://www.ixigua.com/pseries/6783110584444387843/?logTag=cZwYY0OhI8vRiNppza2UW
2. 书籍
1)《生成对抗网络入门指南》,史丹青编著,机械工业出版社



