本文站在第三方的角度审视我在2022年的团队科研经历,一来是自省,二来是帮助更多同学更好的开始自己的科研生活。
科研工作是围绕一个科学问题展开的探索,只要是探索就有成功,有失败。而人工智能的科研探索,永远是以失败为主旋律。再详尽的计划,再强大的开发能力,都无法保证实验不出现问题。和数学条理清晰的证明不一样,人工智能深度学习的黑盒性质,使科研工作的展开注定磕磕绊绊。
:star:对科研成果的要求
不同会议或期刊的收录倾向不同,例如CVPR喜欢新应用,NeurlPS喜欢理论的突破,AAAI相对就比较杂食,但对于一篇好文章的要求无非如下:
- 研究点新颖,要做到读者听上去就想要复现一下。
- 背景资料详实,需要找老前辈讨论。
- 论证的严谨,参考文献充足且逻辑自洽。
- 实验完备且充分,多角度多任务多场景(多数据集、多网络适配、多应用)
- 文章的行文规范且流畅,体现一个团队的积累。

:star:研究的三个板块
对于一个课题组,如何进行人员的组织是一定要考虑的问题。任何一个错误的分工,或者一个模糊不清的角色定位都会造成课题推进的困难。接下来我们从三个主要的板块,展开讨论,科研团队中的大家如何扮演好自己的角色。
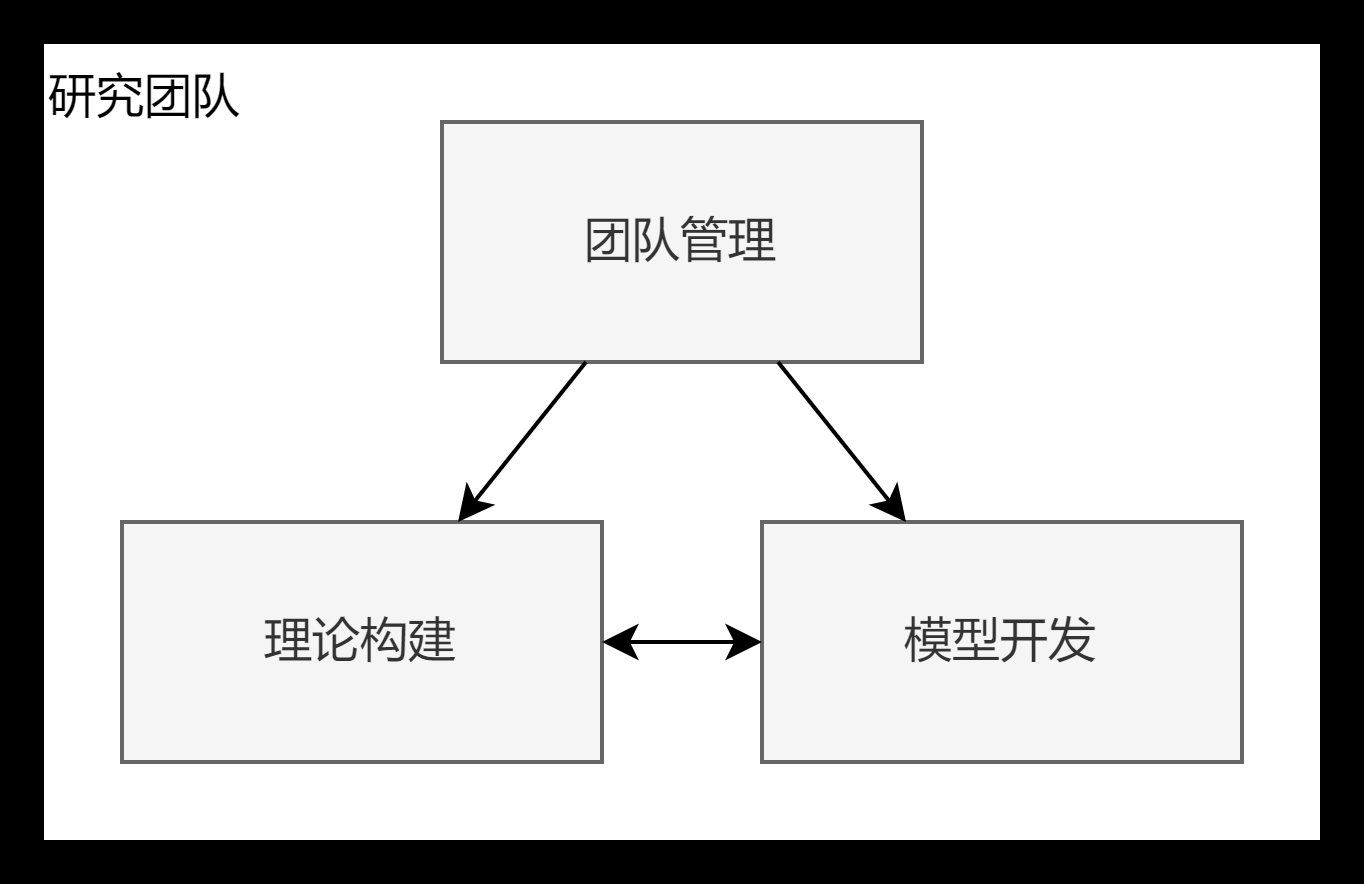
:stars:团队管理
关键词:规范、动量、计划、弹性、变通
十人的科研团队和百人的科研团队的管理肯定是不同的,这里我们只讨论一下个位数团队的管理,包括经验和教训。
什么人适合作为管理:
热情阳光的聪明笨蛋。热情阳光自不必说,这样的人能够支撑起一个向上的团队氛围。聪明是说作为一个管理,需要有自己的一技之长,管好自己负责工作的同时管理他人,才能服众。笨蛋是特质,在人与人的合作过程中,难免会出现摩擦,进而产生负面情绪,而管理员首当其冲会被影响,这个时候一个后知后觉的笨蛋才能作为一个矛盾之外的旁观者,做到决策时的不偏不倚。
管理的职责是什么:
说大了是承担责任的那一个,要保证团队在截止日期前产出期望成果;说小了是推进项目进度的人,保证研究工作的正常展开。具体如何履行管理的职责,我们将在接下来展开。
管理一个科研团队的方法可以从两个方面阐述:人员管理和任务管理。
首先是人员管理:
-
保证团队成员之间的沟通顺畅。需要统一术语,创建课题组共享的知识库,预订所有成员都时间允许的会议,不厌其烦的重复研究点上的决议,且在推翻的时候留存论证思路文档。上述几点应是缺一不可。
-
调动团队成员的积极性。每个人都有自己的方法,最简单最实用的就是在分工的时候提前了解清楚成员的情况和需求,为每个人创造与需求相关的岗位,实现内在积极性的挖掘。

-
积极布局应对科研人员的高流动性。对于类似实习生团队或者社团这样高流动性的情景,应对流动性的方案一定要提前设计。尤其是核心成员的离职会对一个课题的开展造成毁灭性的打击,可能是理论构建上的难度骤增,也可能是代码开发上的断流。可以使用的方法有二,其一是所有的关键岗位永远有两个人共同负责,临时走了一个的时候另一个可以支撑上并培养新的补位成员;其二是将所有的研究内容文档化,包括思考过程和个人或者团队未来的研究计划,赋予课题在暂停很久后依然可以重启的能力。
再来是任务管理:
- 确定每一个阶段的阶段性目标。规划未来是任务管理首先要做的事情,要明确最终目标和期限,对实现目标所需工作进行划分,提前安排成员负责不同阶段的任务。每一个课题的研究工作都有几个阶段:开题、论证、实验、写作。开题包括调研工作等一系列与课题展开相关学习和调查工作;论证阶段的目标是完成论文理论部分的构建;实验部分主要是设计实验方案,对理论进行验证;写作即文章写作,可以先完成中文的草稿,然后在翻译过程中修改,润色。
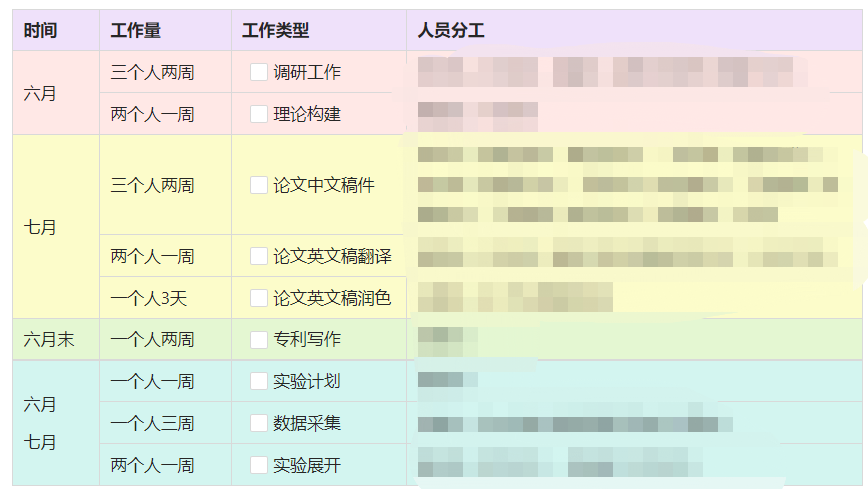
- 在每一个阶段进行详实的分工。这里可以参考OKRs管理的思想,每一个确定好的分工一定是可量化的,也就是说需要是类似是否或者有一个具体数字的分工,将分工记录在固定文档中,截图发送到团队的群聊中提醒大家,最后在约定日期确认可以确认的节点。
:stars:模型开发
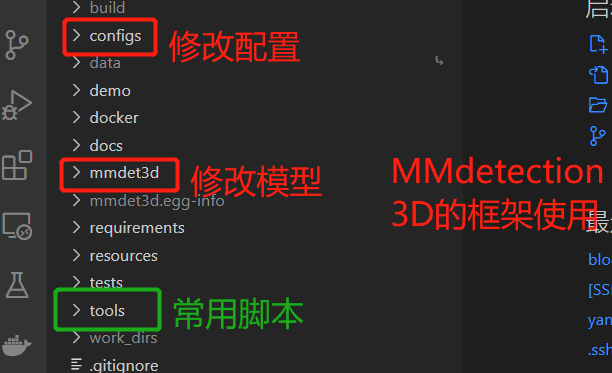
人工智能模型的开发,得益于人工智能框架的成熟,已经规范化,流程化了,甚至出现了低代码的趋势。就算是从0开始搭建一套深度学习模型,也无非是按照前人积累的经验,搭建类似八股文一样的代码。因此为了避免重复工作,也是为了更快的展开研究工作,研究初期选用一套合适框架尤为重要。
在不同领域的高级框架有很多,如目标检测领域的MMDetetion和Detectron2,都集成了不同公共数据集的加载、预处理、结果生成等,并将训练、推理、验证、测试等封装成了高级接口,可以随时调用。因此,人工智能的模型的代码实现并不困难,所有的困难都集中于一点,即研究点相关深度学习网络模块的代码实现。

研究点的代码实现面临三个挑战:
- 与框架接口的适配。需要准确定位研究点在框架中的位置,然后才能对原有框架代码进行替换或增改。网络层的修改定是在模型内部修改,相应的损失函数的代码放在损失函数部分。
- 与框架运行平台的适配。人工智能框架大多都是在GPU上开展计算工作,因此插入代码片段使用与框架相同的方法支持GPU运算就尤为重要。举例就是我们需要使用pytorchGPU实现原本使用math库下的小小概率计算。
- 研究点本身的实现难度。这一点对有经验的模型开发者来说是耗费时间的,如果一个研究涉及到一套模型的方方面面,那修改的时候也会涉及到框架不同位置的知识。
所以对一个研究团队的代码开发的要求有如下两点:
- 要熟悉团队常用的开发框架,拥有修改框架的能力。
- 要熟悉团队的研究点,有参与到研究点讨论的能力。
:stars:理论构建
一篇论文的Method或Theory部分是核心,这些部分一定要做到条理清晰、措辞规范、逻辑自洽才能获得审稿人的青睐。因此对于参与理论构建工作的同学就有了较高的要求。成为一个可以胜任理论构建工作的成员,一定要经过以下的步骤:
- 学习理论提出的基础知识。为了不闹笑话,学习更多的相关知识一定是必要的。同时也是为了在团队讨论时更好的理解讨论的内容。
- 了解理论提出的背景,确定理论提出的动机。为了更好的进行理论构建的合作,每一个参与理论构建的团队成员都要拥有同样的思维出发点,使用一套术语进行讨论,避免不在一个频道的多余讨论。
- 在调研工作中学习相关研究中的理论展开方法,积累常用的逻辑或措辞,同时有意识的在日常的文档工作中去模仿。
除了上述对于成员的期望,对于理论构建工作本身也有几个需要极力避免的事情。
- 很多时候团队中会有很多脑子转得特别快的同学,理论构建起来一套一套的,这种时候一定要避免论文出现头重脚轻的问题。因为论文不是考试作文,任何一个提出的论点,一定要有先人工作或者充分实验进行支撑。一定要有一个论文全文的观念,分清主次,可以把想到的东西记录在一旁,完成一个点的完整论证和试验后,再做下一个。
- 因为现阶段人工智能的研究偏向工程,就算是纯理论的人工智能研究也需要有代码上的具体实现。如果理论设计得太过复杂,超出了框架或者开人成员所能实现的范围,会导致研究点无法进一步推进。因此,理论复杂程度和模型开发能力的平衡非常重要。
- 理论推导的层数过多同样会导致问题。我们设想这样一个极端情况,理论这边耗费大精力构建了一个20层的逻辑链条,实验计划也是环环相扣,但在验证到第5环的时候出现了问题,之后的逻辑直接断链,直白一点说就是白干。因此在理论构建的时候,不能只要考虑到理论的深度,还要考虑到理论的广度,多思考几种可能性,做到在之后的研究中灵活应对变化。当然,最好是理论构建和实验并行,真正做到动态构建链条。
:star2:其他一些话
- :ab:注意:团队中每一个人都有他存在的价值,前期分工的时候一定要全方位了解每一个人,为每个人创造合适的岗位,拆分科研工作。
- :ab:注意:不论分工如何,一个团队中需要有一定数量的核心成员,核心成员决定了课题的走向,通常也会作为论文的一二三作者。