From subword units to n-grams: hierarchy of models
Defining a hierarchy of models: we can compile different HMMs to create models of utterances

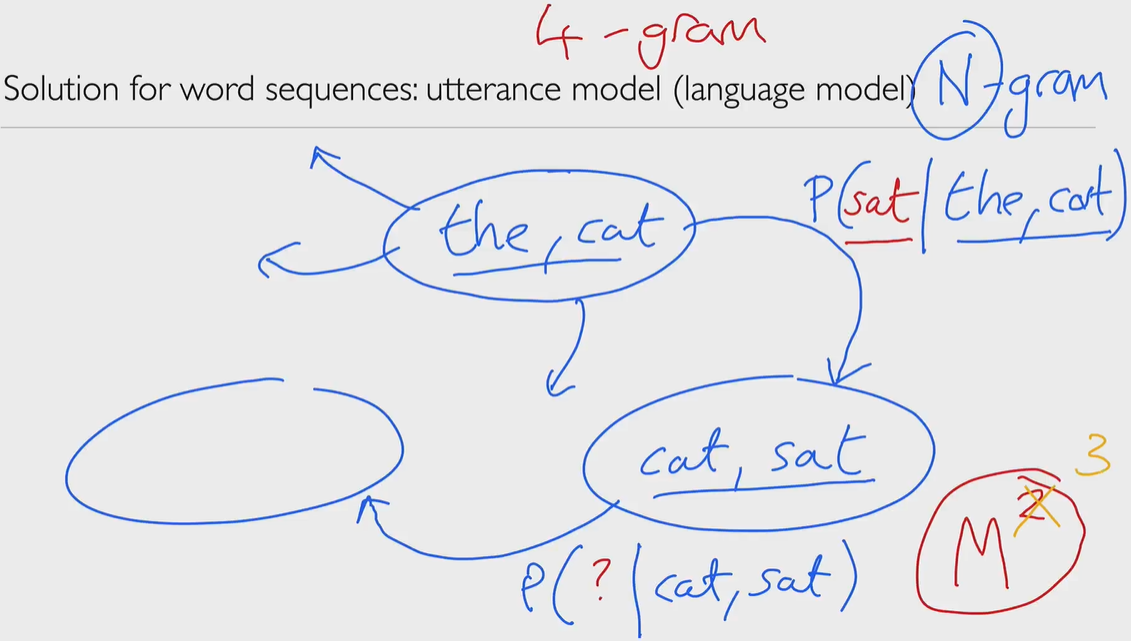

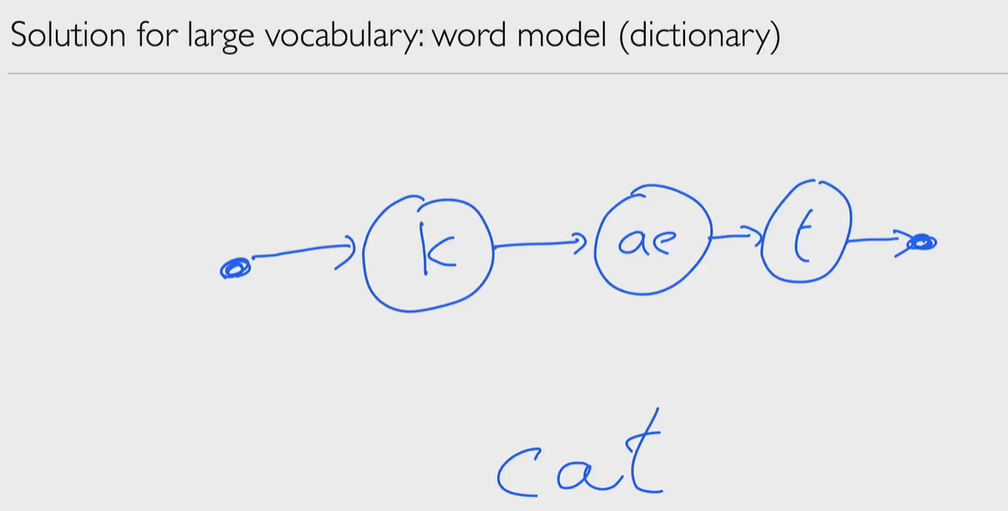


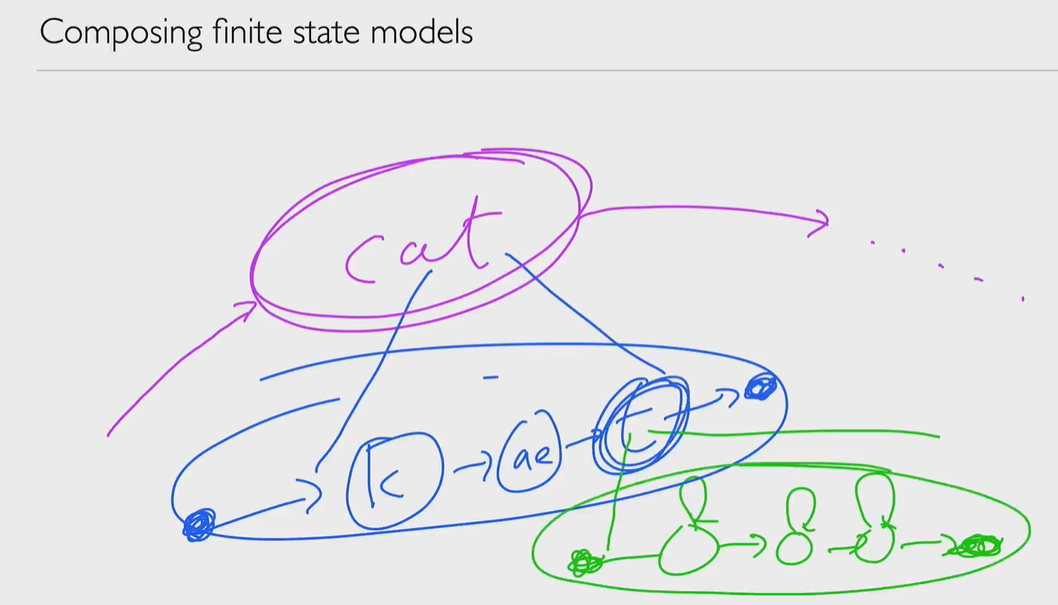
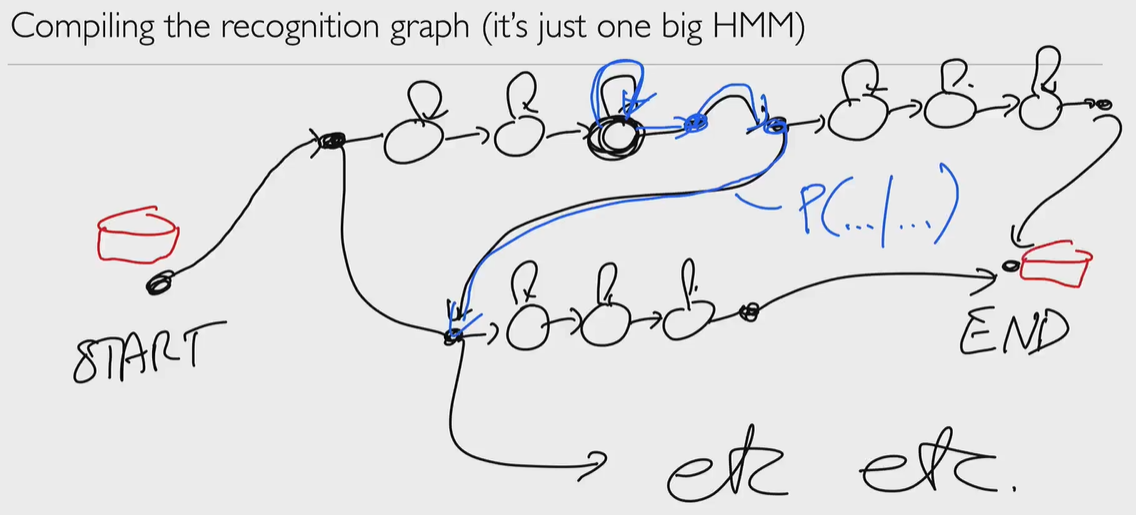
We can do some pruning, remove some tokens while proceeding, reduce computation cost (Maybe Heuristic is also can be helpful in such case.)
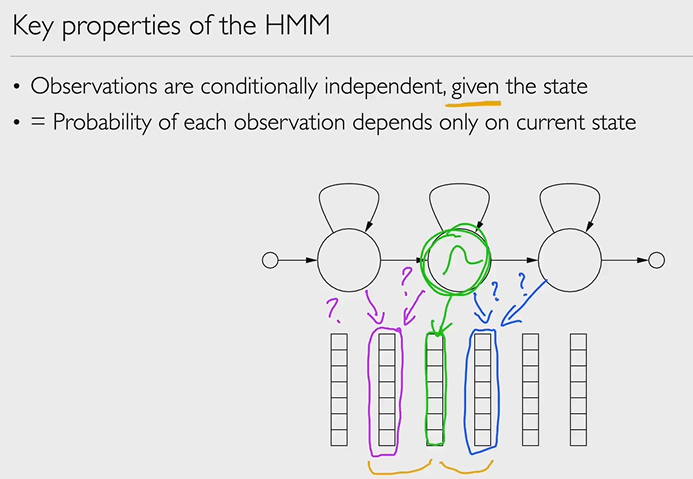
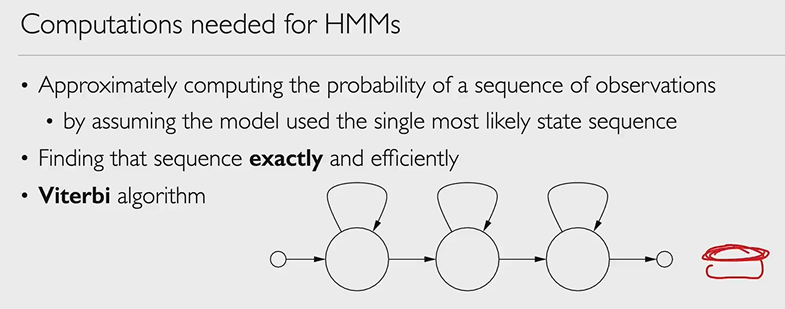
Conditional independence and the forward algorithm
We use the Markov property of HMMs (i.e. conditional independence assumptions) to make computing probabilities of observation sequences easier
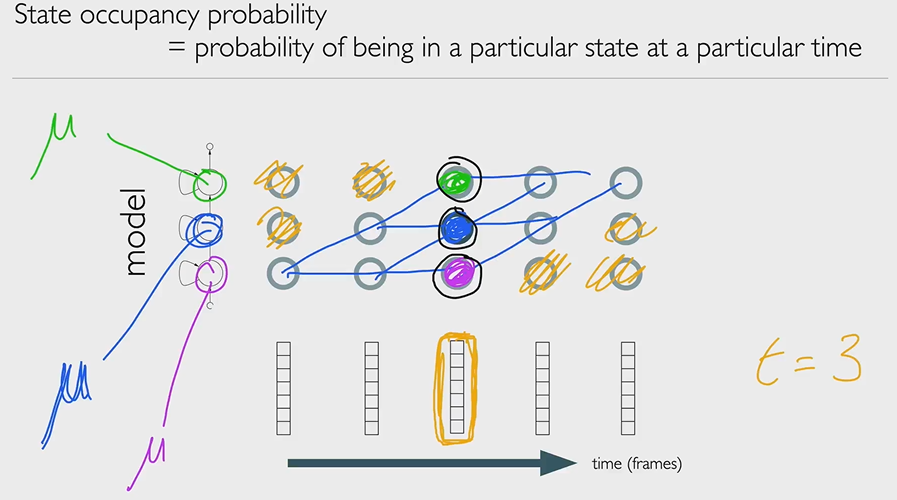
HMM training with the Baum-Welch algorithm
HMM training using the Baum-Welch algorithm. This gives a very high level overview of forward and backward probability calculation on HMMs and Expectation-Maximization as a way to optimise model parameters. The maths is in the readings (but not examinable).

Origin: Module 10 – Speech Recognition – Connected speech & HMM training
Translate + Edit: YangSier (Homepage)
:four_leaf_clover:碎碎念:four_leaf_clover:
Hello米娜桑,这里是英国留学中的杨丝儿。我的博客的关键词集中在编程、算法、机器人、人工智能、数学等等,点个关注吧,持续高质量输出中。
:cherry_blossom:唠嗑QQ群:兔叽的魔术工房 (942848525)
:star:B站账号:白拾Official(活跃于知识区和动画区)


