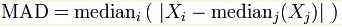线性模型
线性模型是自然界最简单的模型之一,它描述了一个(或多个)自变量对另一个因变量的影响是呈简单的比例、线性关系.例如:
住房每平米单价为1万元,100平米住房价格为100万元,120平米住房为120万元;
一台挖掘机每小时挖$100m^3$沙土,工作4小时可以挖掘$400m^3$沙土.
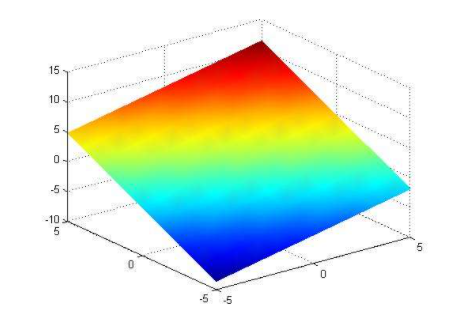
线性模型在二维空间内表现为一条直线,在三维空间内表现为一个平面,更高维度下的线性模型很难用几何图形来表示(称为超平面).如下图所示:
二维空间下线性模型表现为一条直线
三维空间下线性模型表现为一个平面
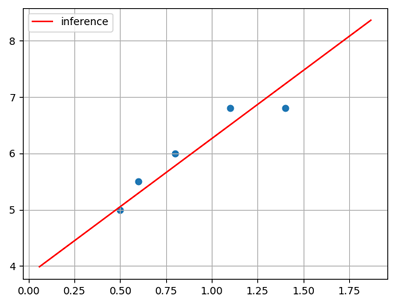
输入(x)
输出(y)
0.5
5.0
0.6
5.5
0.8
6.0
1.1
6.8
1.4
6.8
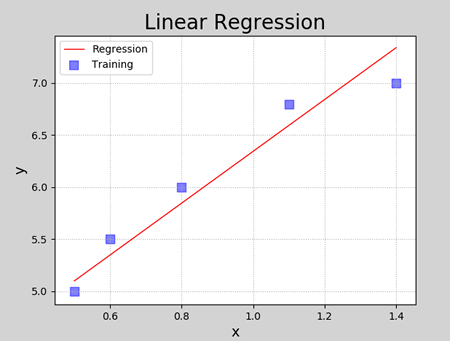
根据样本拟合的线性模型如下图所示:
线性模型定义
设给定一组属性$x, x=(x_1;x_2;…;x_n)$,线性方程的一般表达形式为:
模型训练
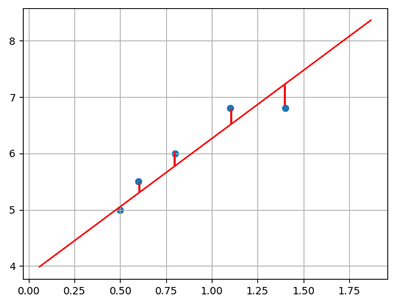
在二维平面中,给定两点可以确定一条直线.但在实际工程中,可能有很多个样本点,无法找到一条直线精确穿过所有样本点,只能找到一条与样本”足够接近“或”距离足够小“的直线,近似拟合给定的样本.如下图所示:
如何确定直线到所有样本足够近呢?可以使用损失函数来进行度量.
损失函数
损失函数用来度量真实值(由样本中给出)和预测值(由模型算出)之间的差异.损失函数值越小,表明模型预测值和真实值之间差异越小,模型性能越好;损失函数值越大,模型预测值和真实值之间差异越大,模型性能越差.在回归问题中,均方差是常用的损失函数,其表达式如下所示:, b^ ) = arg min \frac{1}{2}\sum_{i=1}^{n}{(y - y’)^2} \
梯度下降法
为什么使用梯度下降
在实际计算中,通过最小二乘法求解最优参数有一定的问题:
(1)最小二乘法需要计算逆矩阵,有可能逆矩阵不存在;
(2)当样本特征数量较多时,计算逆矩阵非常耗时甚至不可行.
所以,在实际计算中,通常采用梯度下降法来求解损失函数的极小值,从而找到模型的最优参数.
什么是梯度下降
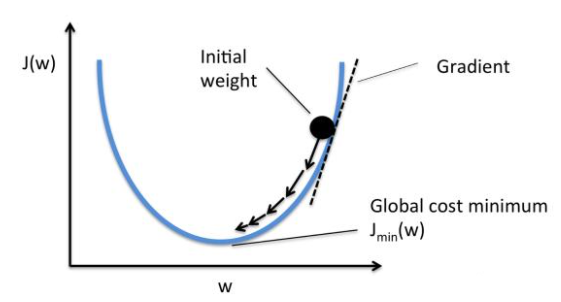
梯度(gradient)是一个向量(矢量,有方向),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大.损失函数沿梯度相反方向收敛最快(即能最快找到极值点).当梯度向量为零(或接近于零),说明到达一个极值点,这也是梯度下降算法迭代计算的终止条件.
这种按照负梯度不停地调整函数权值的过程就叫作“梯度下降法”.通过这样的方法,改变权重让损失函数的值下降得更快,进而将值收敛到损失函数的某个极小值.
通过损失函数,我们将“寻找最优参数”问题,转换为了“寻找损失函数最小值”问题.梯度下降法算法描述如下:
(1)损失是否足够小?如果不是,计算损失函数的梯度.
梯度下降法中通过沿着梯度负方向不断调整参数,从而逐步接近损失函数极小值所在点. 如下图所示:
参数更新法则
在直线方程中,有两个参数需要学习,$w_0$和$w_1$,梯度下降过程中,分别对这两个参数单独进行调整,调整法则如下:
实现线性回归
自己编码实现
以下是实现线性回归的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import numpy as npimport matplotlib.pyplot as mpfrom mpl_toolkits.mplot3d import axes3dimport sklearn.preprocessing as sptrain_x = np.array([0.5 , 0.6 , 0.8 , 1.1 , 1.4 ]) train_y = np.array([5.0 , 5.5 , 6.0 , 6.8 , 7.0 ]) n_epochs = 1000 lrate = 0.01 epochs = [] losses = [] w0, w1 = [1 ], [1 ] for i in range (1 , n_epochs + 1 ): epochs.append(i) y = w0[-1 ] + w1[-1 ] * train_x loss = (((train_y - y) ** 2 ).sum ()) / 2 losses.append(loss) print ("%d: w0=%f, w1=%f, loss=%f" % (i, w0[-1 ], w1[-1 ], loss)) d0 = -(train_y - y).sum () d1 = -(train_x * (train_y - y)).sum () w0.append(w0[-1 ] - (d0 * lrate)) w1.append(w1[-1 ] - (d1 * lrate))
程序执行结果:
1 2 3 4 5 6 7 8 9 10 11 1 w0 =1.00000000 w1 =1.00000000 loss =44.17500000 2 w0 =1.20900000 w1 =1.19060000 loss =36.53882794 3 w0 =1.39916360 w1 =1.36357948 loss =30.23168666 4 w0 =1.57220792 w1 =1.52054607 loss =25.02222743 5 w0 =1.72969350 w1 =1.66296078 loss =20.71937337 .. .. .. 996 w0 =4.06506160 w1 =2.26409126 loss =0.08743506 997 w0 =4.06518850 w1 =2.26395572 loss =0.08743162 998 w0 =4.06531502 w1 =2.26382058 loss =0.08742820 999 w0 =4.06544117 w1 =2.26368585 loss =0.08742480 1000 w0 =4.06556693 w1 =2.26355153 loss =0.08742142
可以给数据加上可视化,让结果更直观.添加如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 w0 = np.array(w0[:-1 ]) w1 = np.array(w1[:-1 ]) mp.figure("Losses" , facecolor="lightgray" ) mp.title("epoch" , fontsize=20 ) mp.ylabel("loss" , fontsize=14 ) mp.grid(linestyle=":" ) mp.plot(epochs, losses, c="blue" , label="loss" ) mp.legend() mp.tight_layout() pred_y = w0[-1 ] + w1[-1 ] * train_x mp.figure("Linear Regression" , facecolor="lightgray" ) mp.title("Linear Regression" , fontsize=20 ) mp.xlabel("x" , fontsize=14 ) mp.ylabel("y" , fontsize=14 ) mp.grid(linestyle=":" ) mp.scatter(train_x, train_y, c="blue" , label="Traing" ) mp.plot(train_x, pred_y, c="red" , label="Regression" ) mp.legend() arr1 = np.linspace(0 , 10 , 500 ) arr2 = np.linspace(0 , 3.5 , 500 ) grid_w0, grid_w1 = np.meshgrid(arr1, arr2) flat_w0, flat_w1 = grid_w0.ravel(), grid_w1.ravel() loss_metrix = train_y.reshape(-1 , 1 ) outer = np.outer(train_x, flat_w1) flat_loss = (((flat_w0 + outer - loss_metrix) ** 2 ).sum (axis=0 )) / 2 grid_loss = flat_loss.reshape(grid_w0.shape) mp.figure('Loss Function' ) ax = mp.gca(projection='3d' ) mp.title('Loss Function' , fontsize=14 ) ax.set_xlabel('w0' , fontsize=14 ) ax.set_ylabel('w1' , fontsize=14 ) ax.set_zlabel('loss' , fontsize=14 ) ax.plot_surface(grid_w0, grid_w1, grid_loss, rstride=10 , cstride=10 , cmap='jet' ) ax.plot(w0, w1, losses, 'o-' , c='orangered' , label='BGD' , zorder=5 ) mp.legend(loc='lower left' ) mp.show()
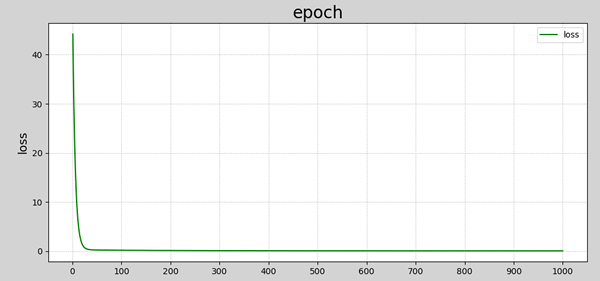
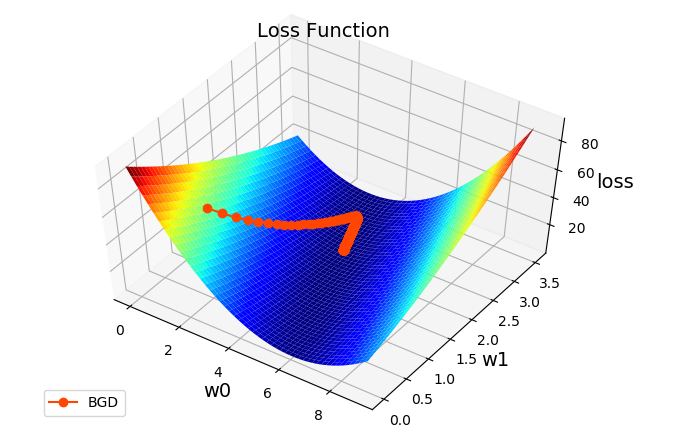
数据可视化结果如下图所示:
回归得到的线性模型
损失函数收敛过程
梯度下降过程 通过sklearn API实现
同样,可以使用sklearn库提供的API实现线性回归.代码如下:
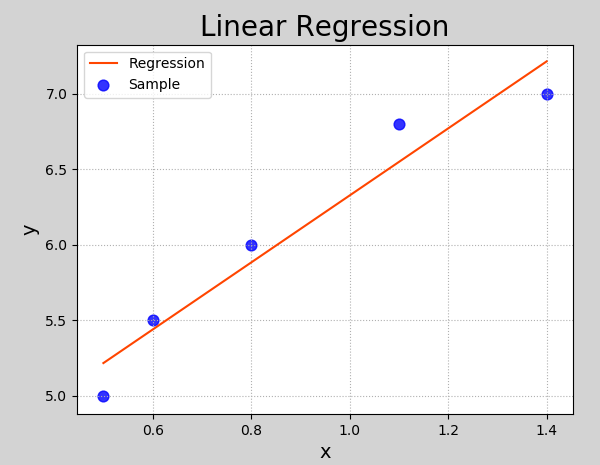
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import numpy as npimport sklearn.linear_model as lm import sklearn.metrics as sm import matplotlib.pyplot as mptrain_x = np.array([[0.5 ], [0.6 ], [0.8 ], [1.1 ], [1.4 ]]) train_y = np.array([5.0 , 5.5 , 6.0 , 6.8 , 7.0 ]) model = lm.LinearRegression() model.fit(train_x, train_y) pred_y = model.predict(train_x) print ("coef_:" , model.coef_) print ("intercept_:" , model.intercept_) mp.figure('Linear Regression' , facecolor='lightgray' ) mp.title('Linear Regression' , fontsize=20 ) mp.xlabel('x' , fontsize=14 ) mp.ylabel('y' , fontsize=14 ) mp.tick_params(labelsize=10 ) mp.grid(linestyle=':' ) mp.scatter(train_x, train_y, c='blue' , alpha=0.8 , s=60 , label='Sample' ) mp.plot(train_x, pred_y, c='orangered' , label='Regression' ) mp.legend() mp.show()
执行结果:
模型评价指标
(1)平均绝对误差(Mean Absolute Deviation):单个观测值与算术平均值的偏差的绝对值的平均;
(2)均方误差:单个样本到平均值差值的平方平均值;
(3)MAD(中位数绝对偏差):与数据中值绝对偏差的中值;
(4)R2决定系数:趋向于1,模型越好;趋向于0,模型越差.
多项式回归
什么是多项式回归
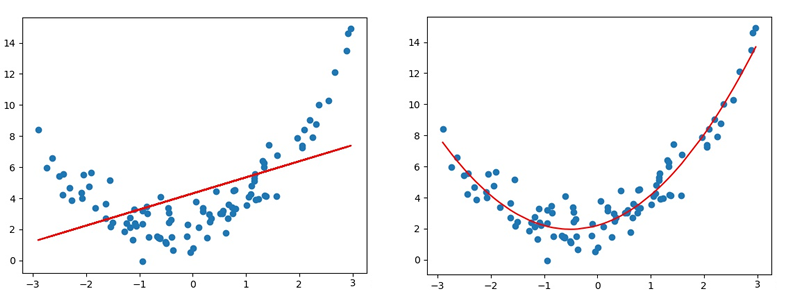
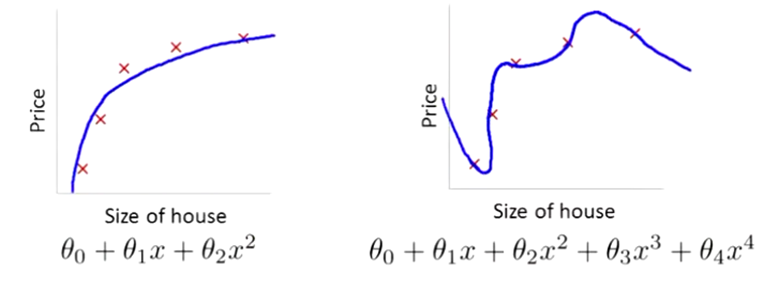
线性回归适用于数据呈线性分布的回归问题.如果数据样本呈明显非线性分布,线性回归模型就不再适用(下图左),而采用多项式回归可能更好(下图右).例如:
多项式模型定义
与线性模型相比,多项式模型引入了高次项,自变量的指数大于1,例如一元二次方程:
与线性回归的关系
多项式回归可以理解为线性回归的扩展,在线性回归模型中添加了新的特征值.例如,要预测一栋房屋的价格,有$x_1, x_2, x_3$三个特征值,分别表示房子长、宽、高,则房屋价格可表示为以下线性模型:
房屋价格是关于长、宽、高三个特征的线性模型
房屋价格是关于体积的多项式模型
因此,可以将一元n次多项式变换成n元一次线性模型.
多项式回归实现
对于一元n次多项式,同样可以利用梯度下降对损失值最小化的方法,寻找最优的模型参数$w_0, w_1, w_2, …, w_n$.可以将一元n次多项式,变换成n元一次多项式,求线性回归.以下是一个多项式回归的实现.
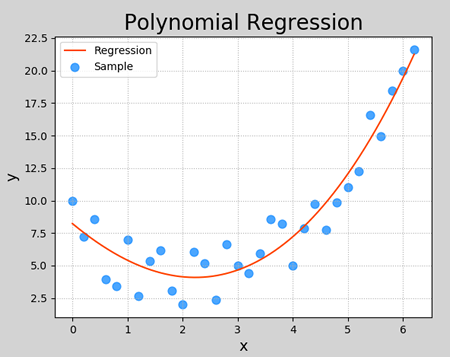
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import numpy as npimport sklearn.linear_model as lmimport sklearn.metrics as smimport matplotlib.pyplot as mpimport sklearn.pipeline as plimport sklearn.preprocessing as sptrain_x, train_y = [], [] with open ("poly_sample.txt" , "rt" ) as f: for line in f.readlines(): data = [float (substr) for substr in line.split("," )] train_x.append(data[:-1 ]) train_y.append(data[-1 ]) train_x = np.array(train_x) train_y = np.array(train_y) model = pl.make_pipeline(sp.PolynomialFeatures(3 ), lm.LinearRegression()) model.fit(train_x, train_y) pred_train_y = model.predict(train_x) err4 = sm.r2_score(train_y, pred_train_y) print (err4)test_x = np.linspace(train_x.min (), train_x.max (), 1000 ) pre_test_y = model.predict(test_x.reshape(-1 , 1 )) mp.figure('Polynomial Regression' , facecolor='lightgray' ) mp.title('Polynomial Regression' , fontsize=20 ) mp.xlabel('x' , fontsize=14 ) mp.ylabel('y' , fontsize=14 ) mp.tick_params(labelsize=10 ) mp.grid(linestyle=':' ) mp.scatter(train_x, train_y, c='dodgerblue' , alpha=0.8 , s=60 , label='Sample' ) mp.plot(test_x, pre_test_y, c='orangered' , label='Regression' ) mp.legend() mp.show()
打印输出:
执行结果:
过拟合与欠拟合
什么是欠拟合、过拟合
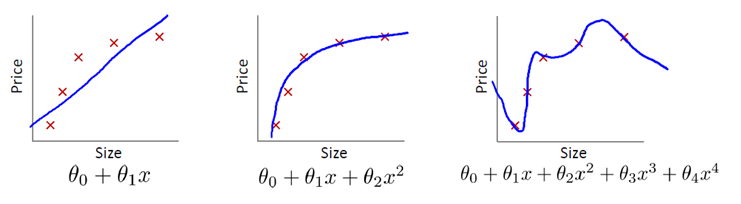
在上一小节多项式回归示例中,多项特征扩展器PolynomialFeatures()进行多项式扩展时,指定了最高次数为3,该参数为多项式扩展的重要参数,如果选取不当,则可能导致不同的拟合效果.下图显示了该参数分别设为1、20时模型的拟合图像:
这两种其实都不是好的模型. 前者没有学习到数据分布规律,模型拟合程度不够,预测准确度过低,这种现象称为“欠拟合”;后者过于拟合更多样本,以致模型泛化能力(新样本的适应性)变差,这种现象称为“过拟合”. **欠拟合模型一般表现为训练集、测试集下准确度都比较低;过拟合模型一般表现为训练集下准确度较高、测试集下准确度较低. **一个好的模型,不论是对于训练数据还是测试数据,都有接近的预测精度,而且精度不能太低.
【思考1】以下哪种模型较好,哪种模型较差,较差的原因是什么?
训练集R2值
测试集R2值
0.6
0.5
0.9
0.6
0.9
0.88
【答案】第一个模型欠拟合;第二个模型过拟合;第三个模型适中,为可接受的模型.
【思考2】以下哪个曲线为欠拟合、过拟合,哪个模型拟合最好?
【答案】第一个模型欠拟合;第三个模型过拟合;第二个模型拟合较好.
如何处理欠拟合、过拟合
欠拟合:提高模型复杂度,如增加特征、增加模型最高次幂等等;
过拟合:降低模型复杂度,如减少特征、降低模型最高次幂等等.
线性回归模型变种
过拟合还有一个常见的原因,就是模型参数值太大,所以可以通过抑制参数的方式来解决过拟合问题.如下图所示,右图产生了一定程度过拟合,可以通过弱化高次项的系数(但不删除)来降低过拟合.
例如,可以通过在$\theta_3, \theta_4$上添加一定的系数,来压制这两个高次项的系数,这种方法称为正则化。但在实际问题中,可能有更多的系数,我们并不知道应该压制哪些系数,所以,可以通过收缩所有系数来避免过拟合 .
正则化定义
正则化是指,在目标函数(如损失函数)后面加上一个范数,来防止过拟合的手段,这个范数定义为:p = (\sum {i=1}^N |x|^p)^{\frac{1}{p}}1 = (\sum {i=1}^N |x|)2 = (\sum {i=1}^N |x|^2)^{\frac{1}{2}}
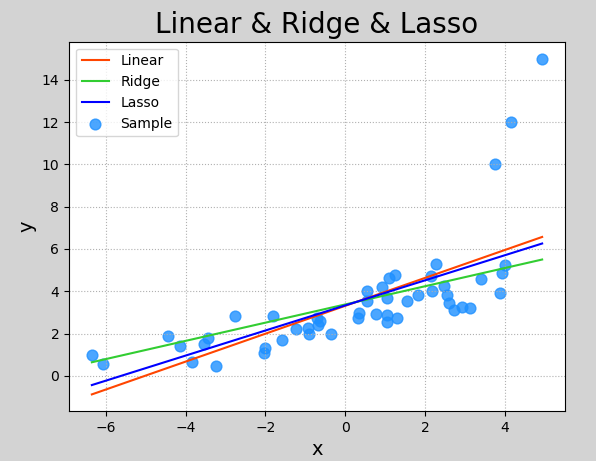
Lasso回归与岭回归
Lasso 回归和岭回归(Ridge Regression)都是在标准线性回归的基础上修改了损失函数的回归算法. Lasso回归全称为 Least absolute shrinkage and selection operator,又译“最小绝对值收敛和选择算子”、”套索算法”,其损失函数如下所示:1 {i=1}^N y_i - y_i’)^2 + \lambda ||w||_2
以下关于Lasso回归于岭回归的sklearn实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import numpy as npimport sklearn.linear_model as lmimport sklearn.metrics as smimport matplotlib.pyplot as mpx, y = [], [] with open ("abnormal.txt" , "rt" ) as f: for line in f.readlines(): data = [float (substr) for substr in line.split("," )] x.append(data[:-1 ]) y.append(data[-1 ]) x = np.array(x) y = np.array(y) model = lm.LinearRegression() model.fit(x, y) pred_y = model.predict(x) model_2 = lm.Ridge(alpha=200 , max_iter=1000 ) model_2.fit(x, y) pred_y2 = model_2.predict(x) model_3 = lm.Lasso(alpha=0.5 , max_iter=1000 ) model_3.fit(x, y) pred_y3 = model_3.predict(x) mp.figure('Linear & Ridge & Lasso' , facecolor='lightgray' ) mp.title('Linear & Ridge & Lasso' , fontsize=20 ) mp.xlabel('x' , fontsize=14 ) mp.ylabel('y' , fontsize=14 ) mp.tick_params(labelsize=10 ) mp.grid(linestyle=':' ) mp.scatter(x, y, c='dodgerblue' , alpha=0.8 , s=60 , label='Sample' ) sorted_idx = x.T[0 ].argsort() mp.plot(x[sorted_idx], pred_y[sorted_idx], c='orangered' , label='Linear' ) mp.plot(x[sorted_idx], pred_y2[sorted_idx], c='limegreen' , label='Ridge' ) mp.plot(x[sorted_idx], pred_y3[sorted_idx], c='blue' , label='Lasso' ) mp.legend() mp.show()
以下是执行结果:
模型保存与加载
可以使用Python提供的功能对模型对象进行保存.使用方法如下:
1 2 3 4 5 import picklepickle.dump(模型对象, 文件对象) model_obj = pickle.load(文件对象)
保存训练模型应该在训练完成或评估完成之后,完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import numpy as npimport sklearn.linear_model as lm import picklex = np.array([[0.5 ], [0.6 ], [0.8 ], [1.1 ], [1.4 ]]) y = np.array([5.0 , 5.5 , 6.0 , 6.8 , 7.0 ]) model = lm.LinearRegression() model.fit(x, y) print ("训练完成." )with open ('linear_model.pkl' , 'wb' ) as f: pickle.dump(model, f) print ("保存模型完成." )
执行完成后,可以看到与源码相同目录下多了一个名称为linear_model.pkl的文件,这就是保存的训练模型.使用该模型代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import numpy as npimport sklearn.linear_model as lm import sklearn.metrics as sm import matplotlib.pyplot as mpimport picklex = np.array([[0.5 ], [0.6 ], [0.8 ], [1.1 ], [1.4 ]]) y = np.array([5.0 , 5.5 , 6.0 , 6.8 , 7.0 ]) with open ('linear_model.pkl' , 'rb' ) as f: model = pickle.load(f) print ("加载模型完成." ) pred_y = model.predict(x) mp.figure('Linear Regression' , facecolor='lightgray' ) mp.title('Linear Regression' , fontsize=20 ) mp.xlabel('x' , fontsize=14 ) mp.ylabel('y' , fontsize=14 ) mp.tick_params(labelsize=10 ) mp.grid(linestyle=':' ) mp.scatter(x, y, c='blue' , alpha=0.8 , s=60 , label='Sample' ) mp.plot(x, pred_y, c='orangered' , label='Regression' ) mp.legend() mp.show()
执行结果和训练模型预测结果一样.
线性回归总结
(1)什么是线性模型:线性模型是自然界最简单的模型之一,反映自变量、因变量之间的等比例增长关系
(2)什么时候使用线性回归:线性模型只能用于满足线性分布规律的数据中
(3)如何实现线性回归:给定一组样本,给定初始的w和b,通过梯度下降法求最优的w和b