
Image Features: A General Process
- Step 1 - Feature Detection: identify distinctive points in our images. We call these points features.
- Step 2 - Feature Description: associate a descriptor for each feature from its neighborhood.
- Step 3 - Feature Matching: we use these descriptors to match features across two or more images.
Feature Detection
Feature Define
Features: Points of interest in an image defined by its image pixel coordinates [u, v].
Points of interest should have the following characteristics:
For the feature:
- Saliency: distinctive, identifiable, and different from its immediate neighborhood. (similar to neighbor, would cause confusion, is not a feature)
- Locality: occupies a relatively small subset of image space. (occupies a large area is not a good feature)
For the set of features:
- Repeatability: can be found even under some distortion. (miss with small distortion, including rotation and scale change, is not a feature)
- Quantity: enough points represented in the image. (small number is not a good feature)
- Efficiency: reasonable computation time. (resource consuming is not a good feature)

Feature Detection Algorithms
Feature Detection: Algorithms
- Harris {corners}: Easy to compute, but not scale invariant. [Harris and Stephens, 1988]
- Harris-Laplace {corners}: Same procedure as Harris detector, addition of scale selection based on Laplacian. Scale invariance. [Mikolajczyk, 2001]
- Features from accelerated segment test (FAST) {corners}: Machine learning approach for fast corner detection. [Rosten and Drummond, 2006]
- Laplacian of Gaussian (LOG) detector {blobs}: Uses the concept of scale space in a large neighborhood (blob). Somewhat scale invariant. [Lindeberg, 1998]
- Difference of Gaussian (DOG) detector {blobs}: Approximates LOG but is faster to compute. [Lowe, 2004]

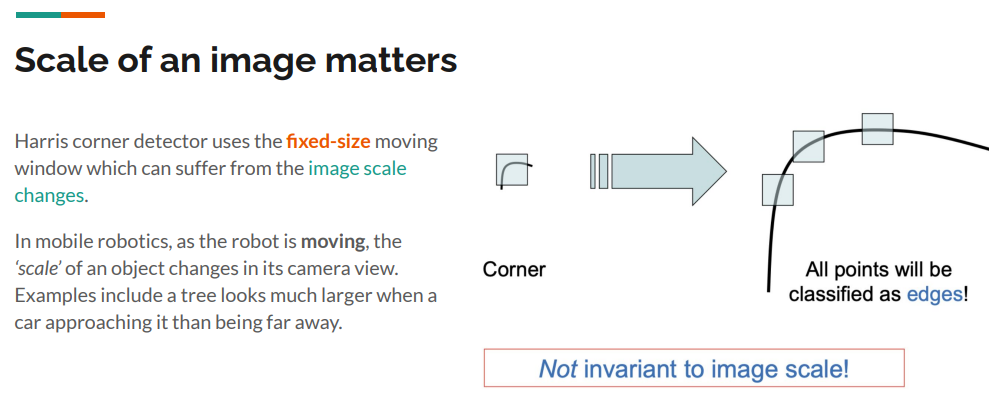
Feature Description
Descriptor: An N-dimensional vector that provides a summary of the local neighborhood information around the detected feature.
An effective feature descriptor should have the following characteristics:
- Repeatability: manifested as robustness and invariance to translation, rotation, scale, and illumination changes
- Distinctiveness: should allow us to distinguish between two close-by features, very important for subsequent matching step
- Compactness & Efficiency: reasonable computation time and efficiency

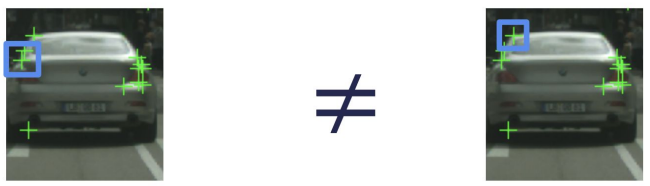

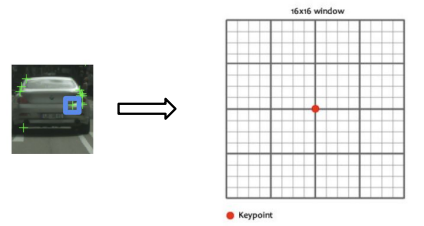
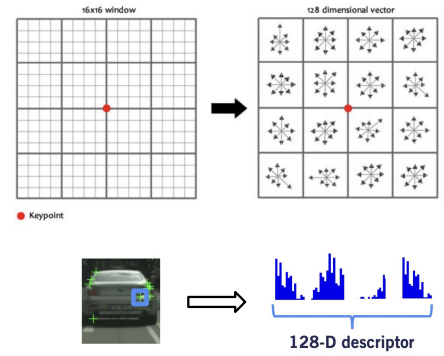
Scale Invariant Feature Transform (SIFT) descriptors: [Lowe 1999]
- Step 1: Find a 16 x 16 window around detected feature
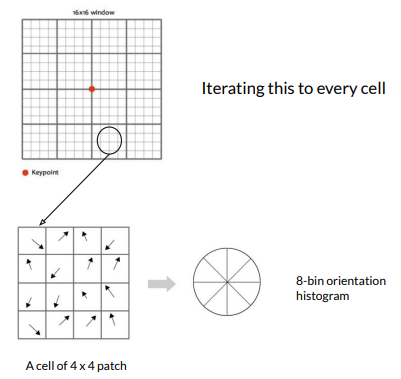
- Step 2: Separate the neighborhood into 16 cells, each comprised of 4 x 4 patch of pixels
- Step 3: For each cell, first find the most prominent gradient change direction in each patch, and then create a 8-bin orientation histogram to describe the cell.
- Step 4: Apply this 8-bin orientation description to all the 16 cells, and it yields a 128-dimension vector - the descriptor of the keypoint
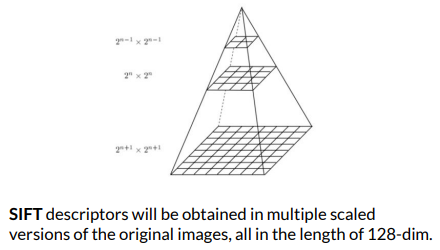
The above process is usually compute on rotated and scaled versions of the 16 x 16 window, allowing for better scale robustness.
Feature Matching
Brute Force Feature Matching
Brute force feature matching might not be fast enough for extremely large amounts of features. In practice, a k-d tree is often used to speed the search by constraining it spatially.

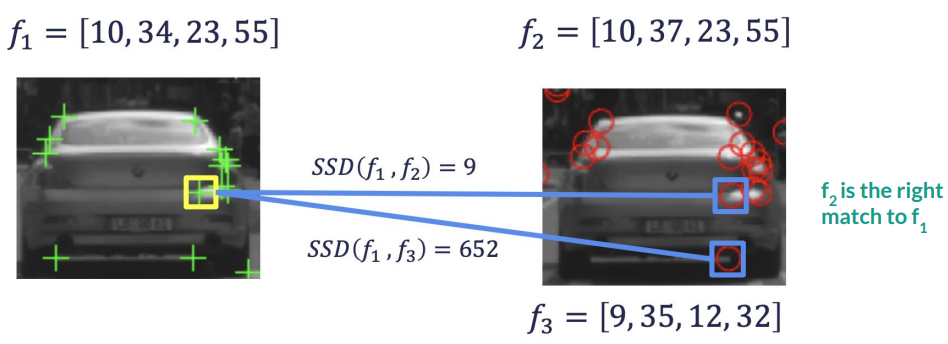
Brute Force Feature Matching, with distance threshold

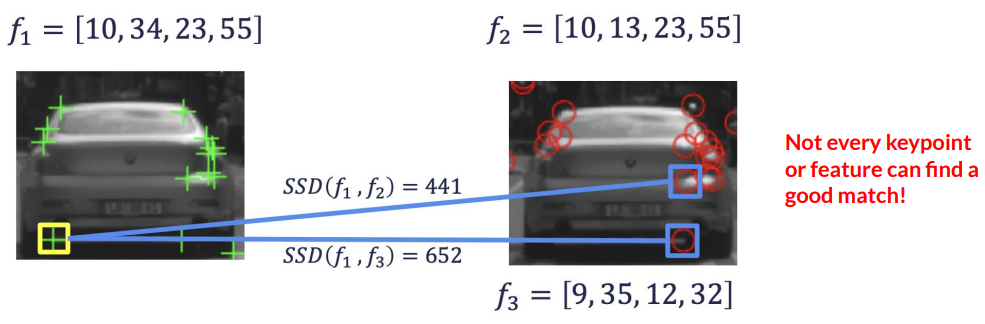
Outlier Rejection with Random Sample Consensus (RANSAC)

Question
What is a blob?
What is k-d tree?
Is it possible to do the description step first for all pixels and use the pixel description to detect or identify those keypoints?
Supplement materials
- Haris Corner Detection.
- Introduction to Scale-Invariant Feature Transform.
- RANSAC and Inliers.
- Pixel Gradient Calculation.
Origin: Dr. Chris Lu (Homepage)
Translate + Edit: YangSier (Homepage)
:four_leaf_clover:碎碎念:four_leaf_clover:
Hello米娜桑,这里是英国留学中的杨丝儿。我的博客的关键词集中在编程、算法、机器人、人工智能、数学等等,点个关注吧,持续高质量输出中。
:cherry_blossom:唠嗑QQ群:兔叽的魔术工房 (942848525)
:star:B站账号:白拾Official(活跃于知识区和动画区)


