Tokenisation & normalisation
标签化 & 正则化
When processing almost any text, we need to find the words. This involves splitting the input character sequence into tokens and normalising each token into words.


Handwritten rules
Every user of a language holds a lot of knowledge about that language in their mind. One way to capture and make use of that knowledge is in the form of rules.
Finite state transducer
Finite State Transducers provide general-purpose machinery for rewriting an input sequence as an output sequence. They have many uses, including verbalising NSWs into natural language.
Phonemes and allophones
This video introduces the notion of phoneme as a basic unit of phonological analysis.
Allophones: 同音异位, allophones are predictable
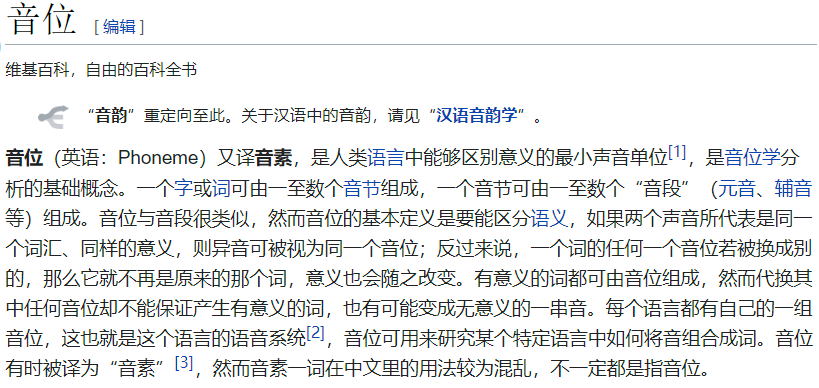

Difference between Phonetics and Phonology.

- two levels of representation
- surface or allophonic level
- represents something close to articulation
- the phonetic descriptions that we’ve been learning so far.
- underlying or phonemic level
- represents abstract categories that are something like our perceptual judgments about which sounds are and are not similar to each other.
- Somewhat confusingly, both of these levels use symbols from the IPA.
- In order to distinguish between the two levels of representation, we use two types of brackets.
- For the surface forms, we use square brackets,
[ ]can indicate varying degrees of detail- for the underlying forms, we use slashes.
/ /can only indicate abstract categories of phonemic contrast
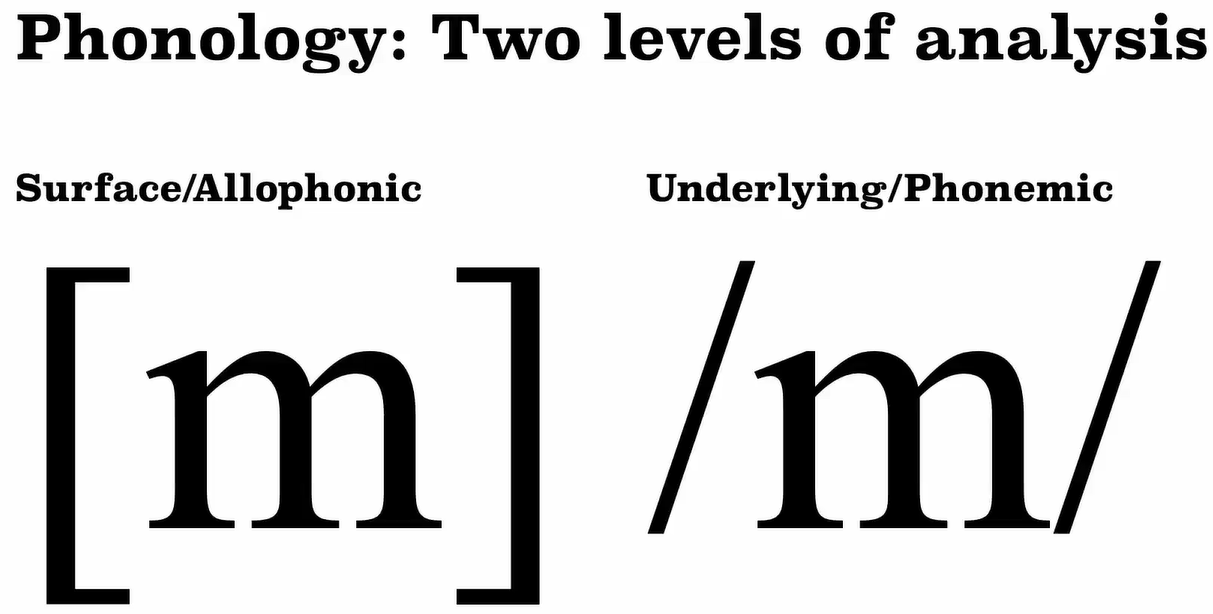
Easy to recognize the difference in underlying level.
Hard to recognize the difference in underlying level, for English.


These surface representations, represented between square brackets are known as allophones and they are language specific.
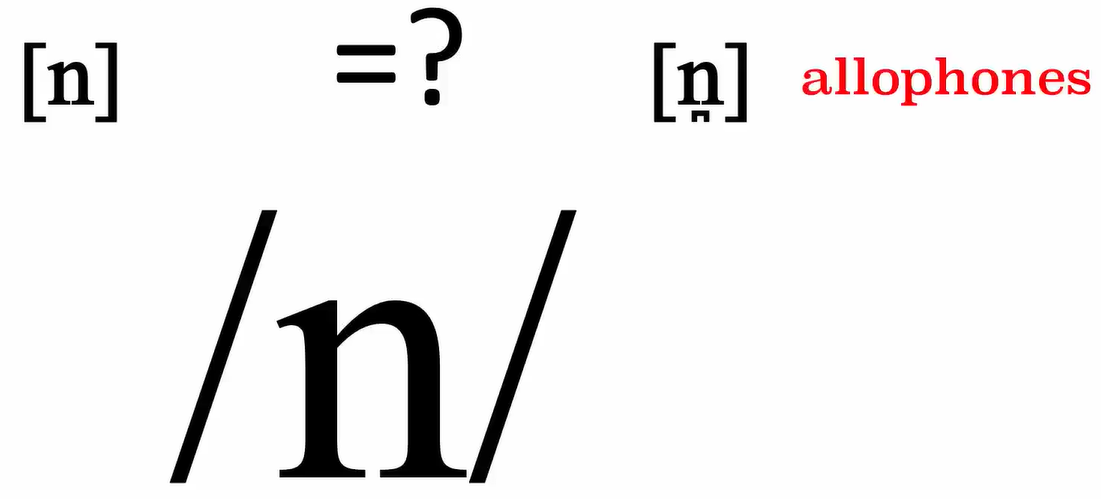
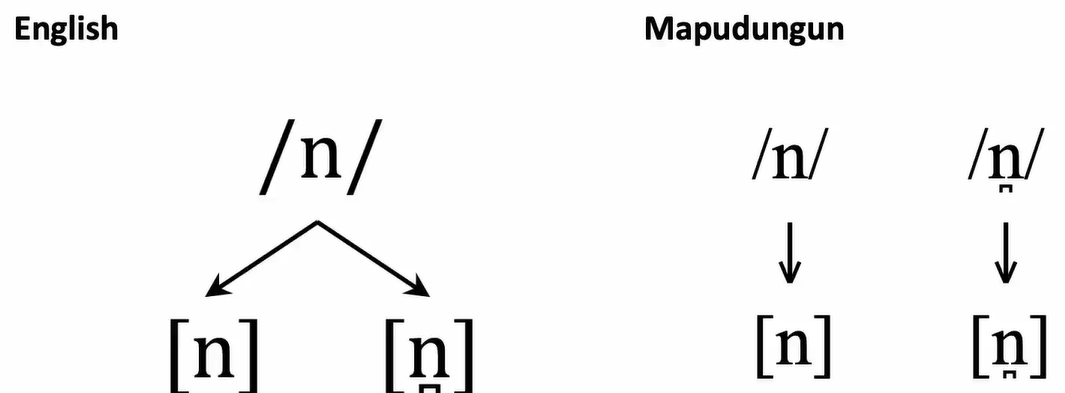
In Mapudungun, we can recognize the difference.
The language specific allophones, in English 2 surface representation with 1 underlying representation, and in Mapudungun 2 surface representations with 2 different underlying representations separately.
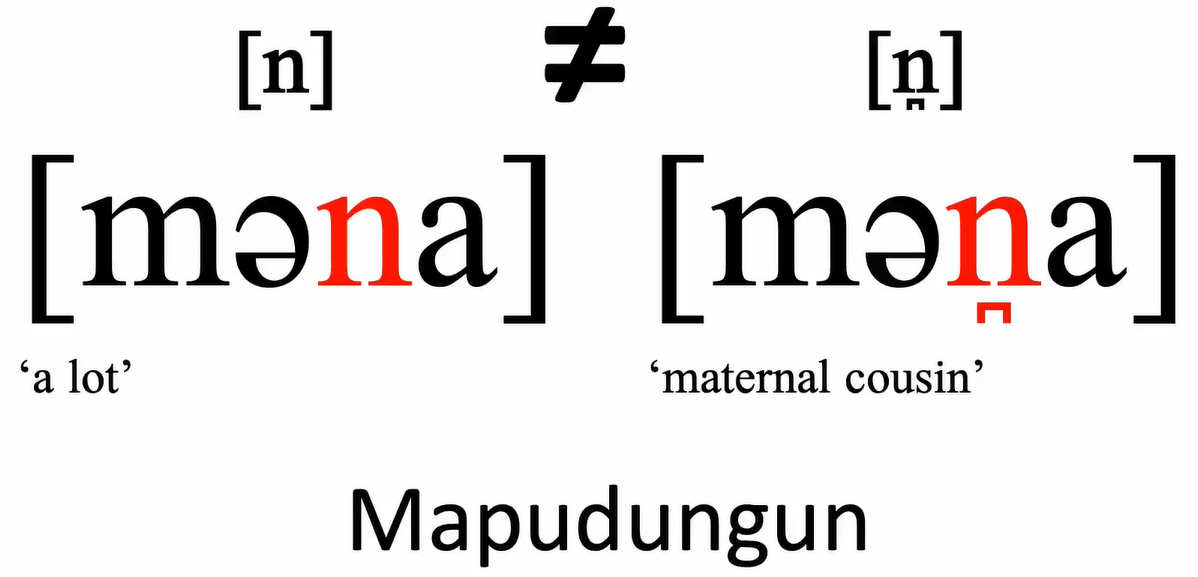
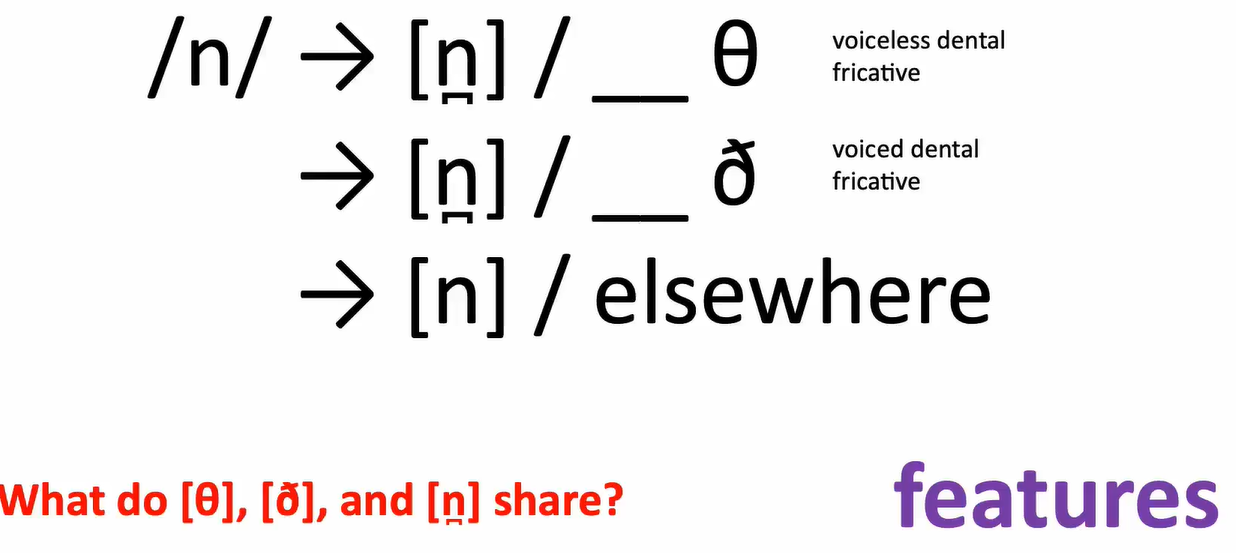
- Phonologists sometimes formalize this relationship between the phoneme and its allophones in a rule.
- The arrow is read as “is realized as”
- the slash stands for “in the environment of”.
- The blank shows where the phoneme occurs in order for the rule to apply.
- In order to fully define a phoneme,
- we first need to observe the surface forms that occur, along with their environments.
- Then, we need to describe the patterns that we see with respect to the surface forms and their phonetic environments, looking for generalizations along the way.
- The types of generalizations that we typically mean are those having to do with shared features across the predictive environments.

More examples

Pronunciation
The phoneme inventory is a design choice when we build a TTS or ASR system. The IPA is a helpful guide when making this choice, but we don’t have to obey it, and are free to make different choices.

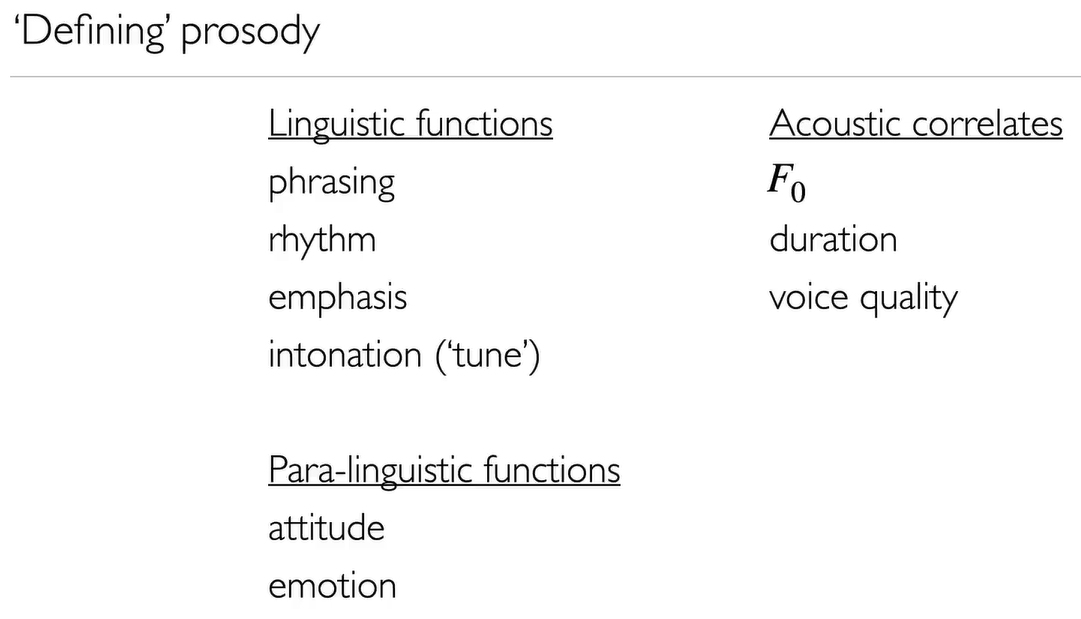
Prosody
Prosody for Text-To-Speech can be reduced the the problem of predicting pausing, duration, and F0.
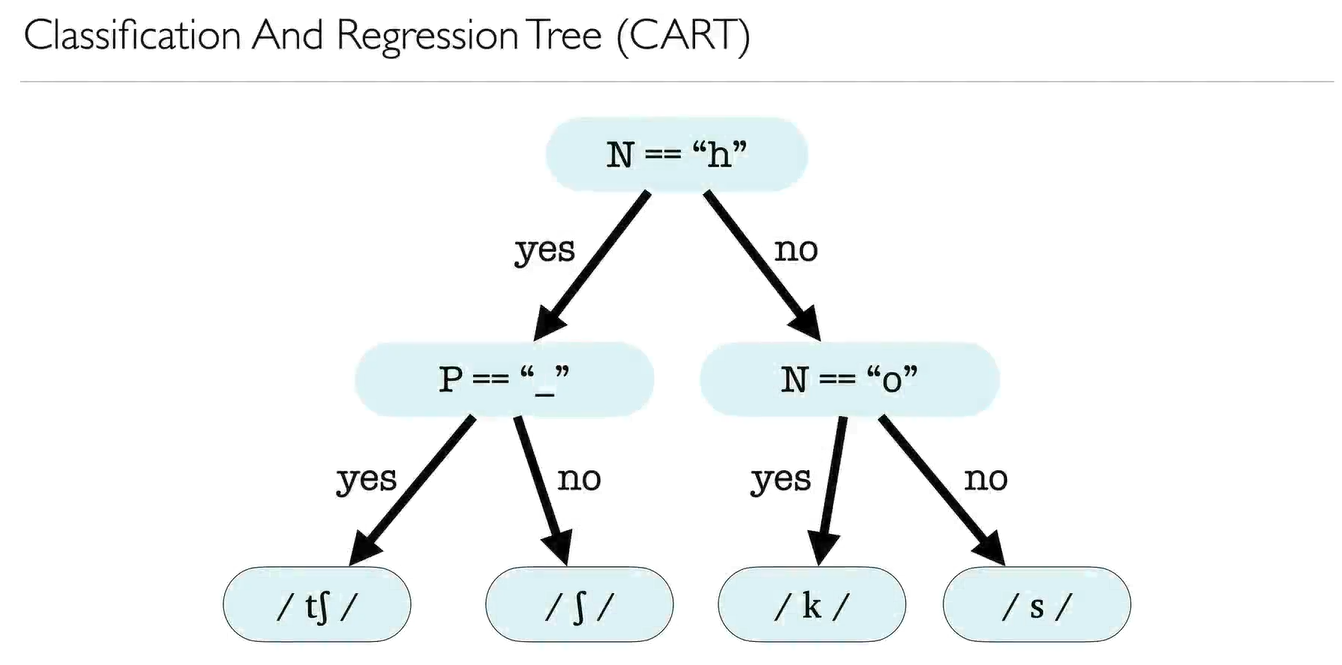
Decision tree
Because a decision tree only asks simple ‘yes or no’ questions about predictors, it works for both categorical and continuous predictors, or a mixture of both.
Learning decision trees
Having defined the model, we now need an algorithm to estimate it from data. For a Decision Tree, this is a simple greedy algorithm.
Training data: a pronunciation lexicon

Goal: making query and reducing entropy of the probability distribution.
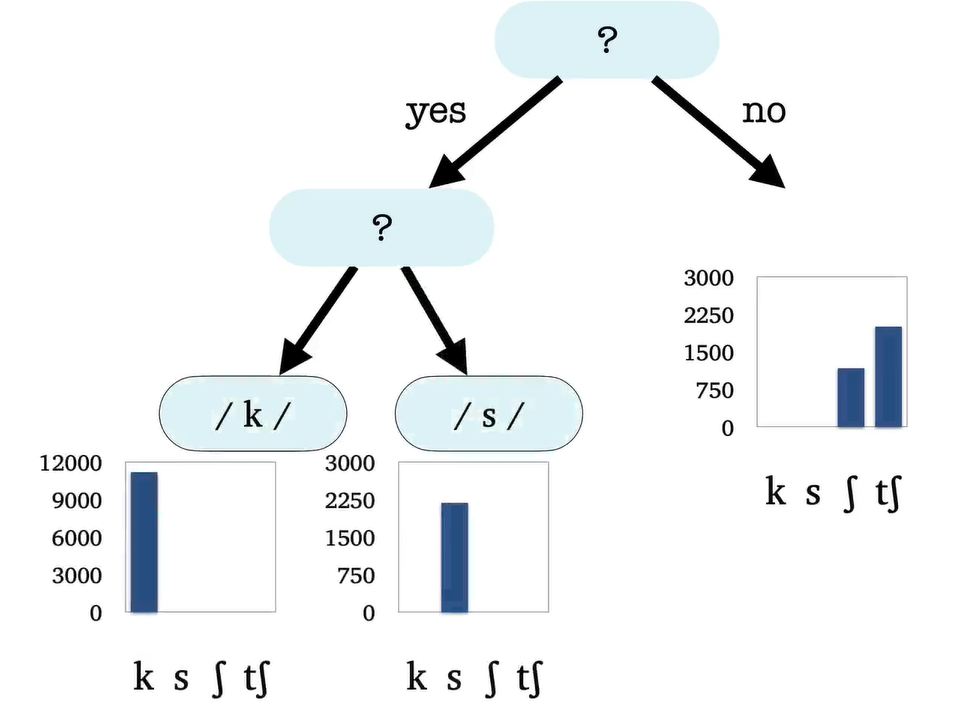
Stop condition: result data set is small or result is acceptable or the depth of tree is reach the limit.
Summary

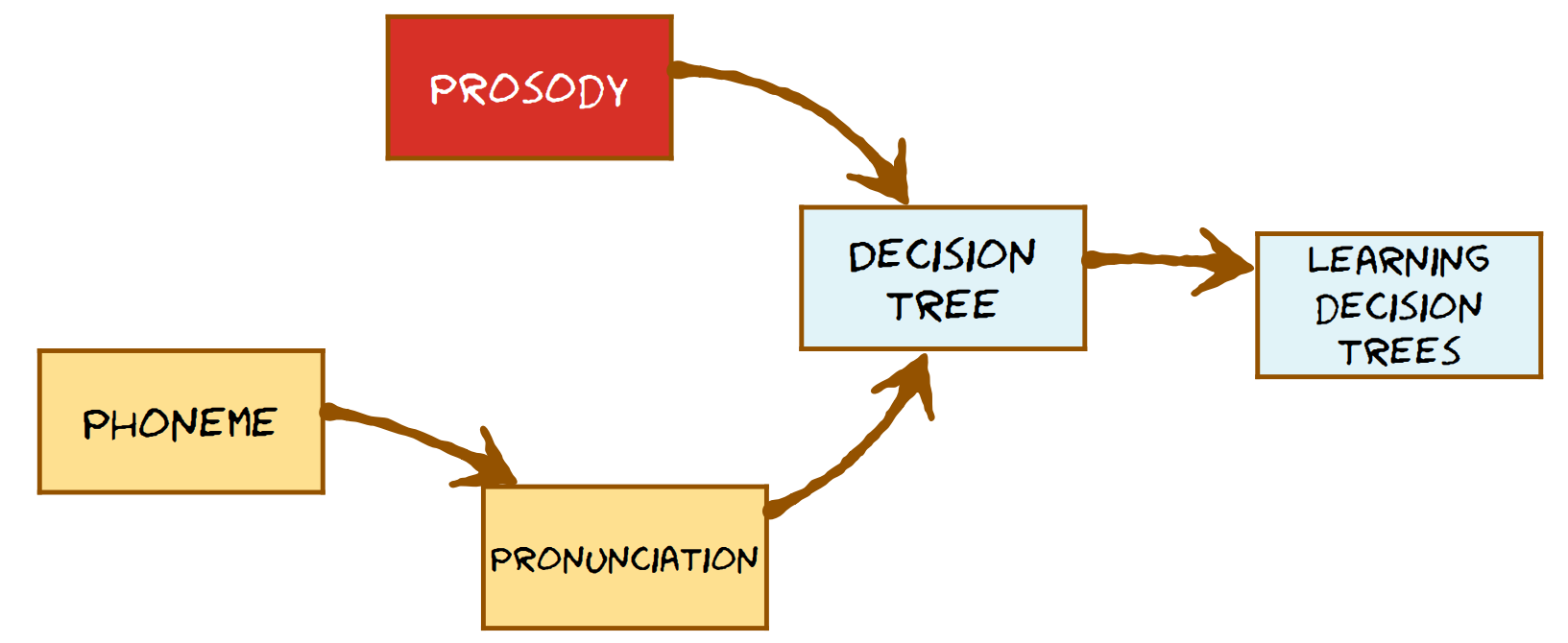
Origin: Module 5 speech synthesis – phonemes and the front end
Translate + Edit: YangSier (Homepage)
:four_leaf_clover:碎碎念:four_leaf_clover:
Hello米娜桑,这里是英国留学中的杨丝儿。我的博客的关键词集中在编程、算法、机器人、人工智能、数学等等,点个关注吧,持续高质量输出中。
:cherry_blossom:唠嗑QQ群:兔叽的魔术工房 (942848525)
:star:B站账号:白拾Official(活跃于知识区和动画区)


