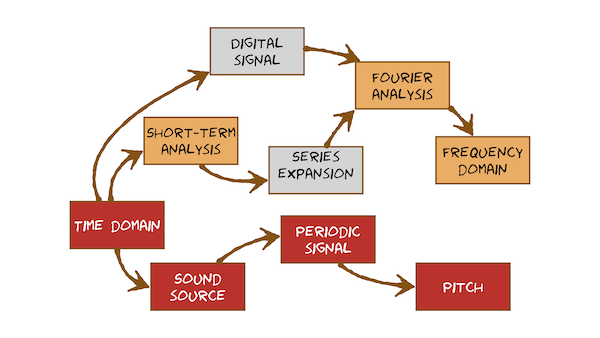
Time domain
Sound is a wave of pressure travelling through a medium, such as air. We can plot the variation in pressure (captured by microphone) against time to visualise the waveform.
Sound source
Air flow from the lungs is the power source for generating a basic source of sound either using the vocal folds or at a constriction made anywhere in the vocal tract.
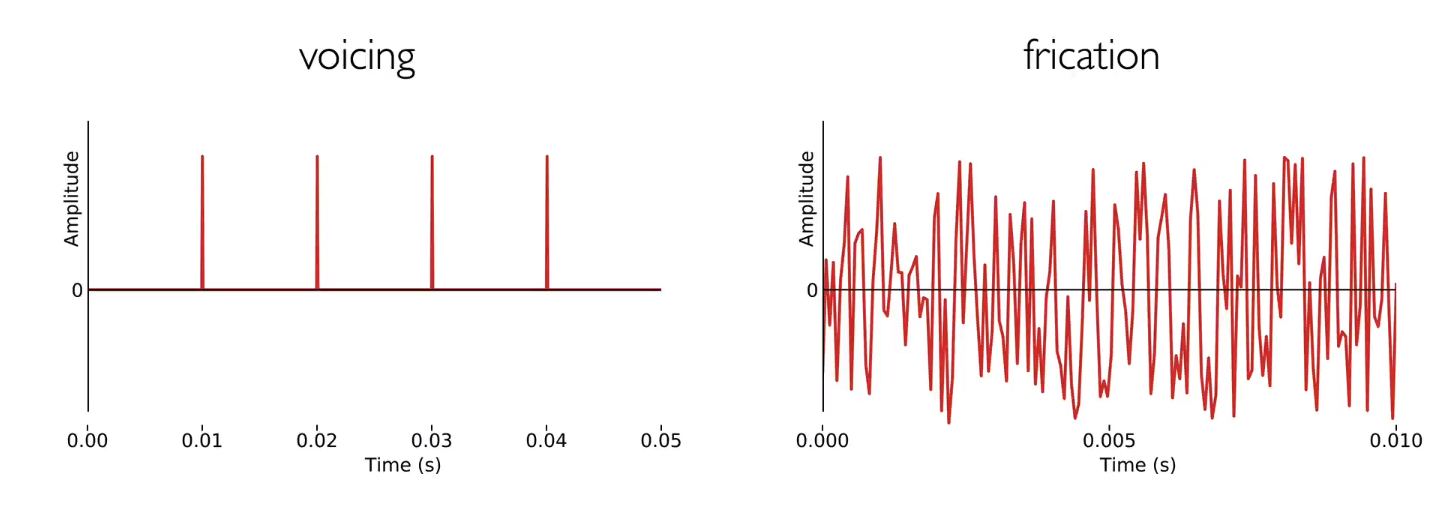
somehthing about pressure with our vocal folds, the air flow is slow, its only the power source of sound, the pressure change is the key generating sounds, repeat pulse of sound.
Periodic signal
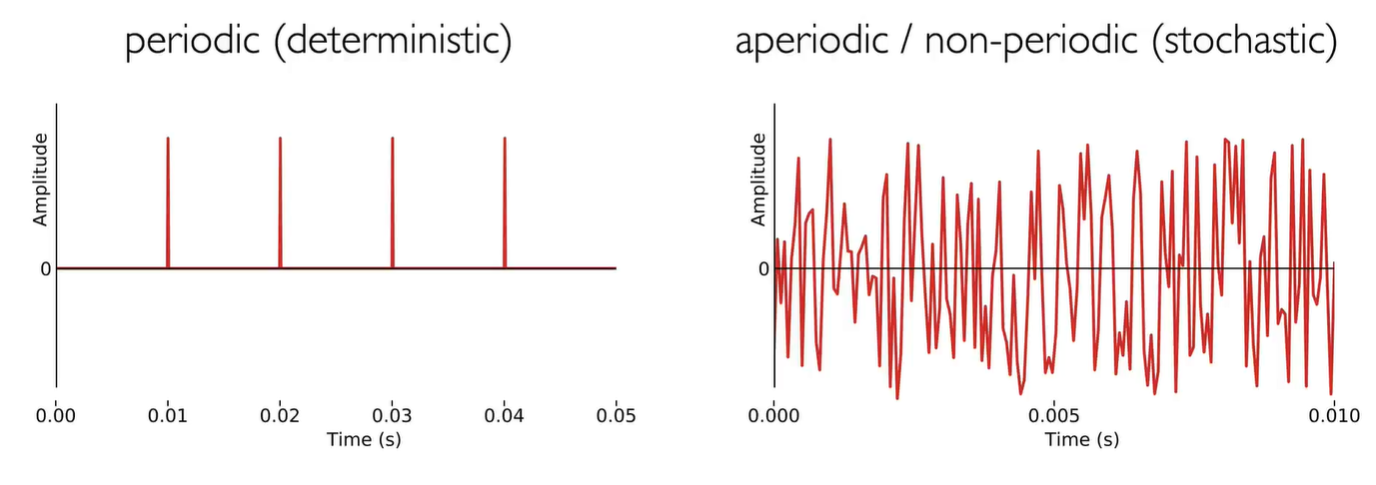
The vocal folds block air flow from the lungs, burst open under pressure to create a glottal pulse, then rapidly close. This repeats, creating a periodic signal.
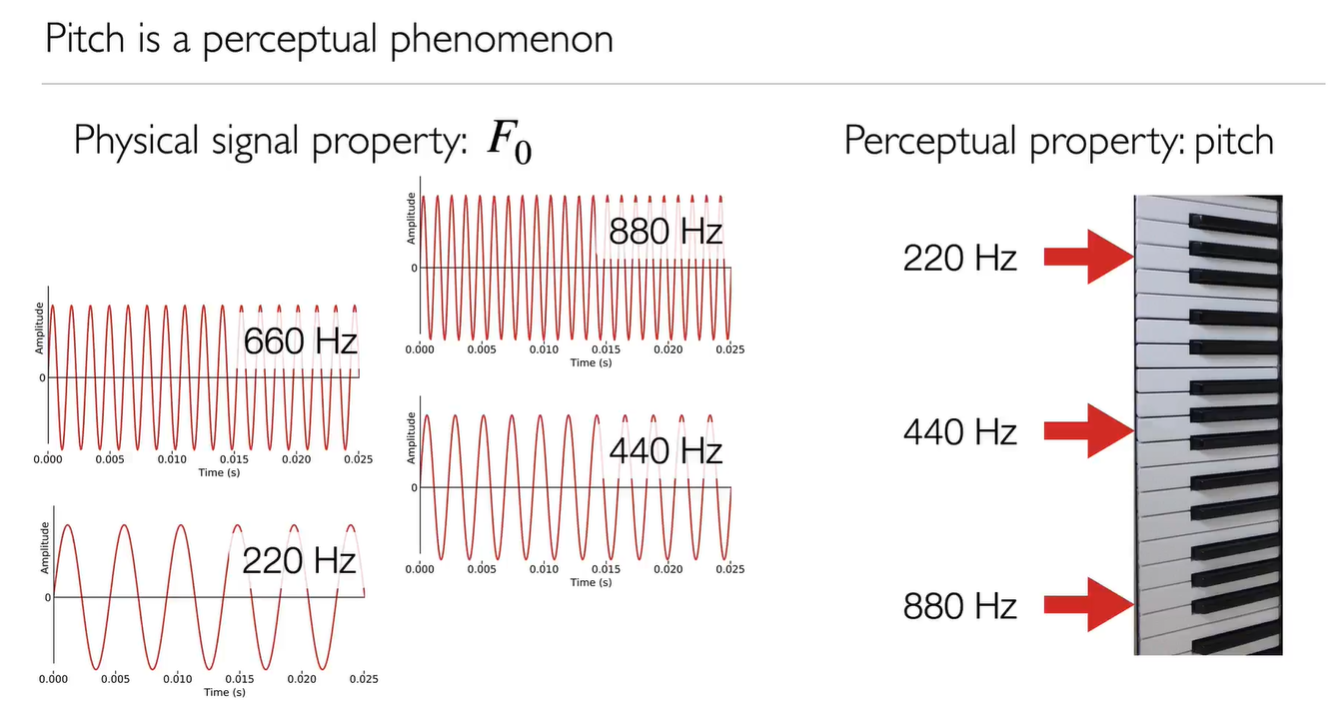
Pitch
Periodic signals are perceived as having a pitch. The physical property of fundamental frequency relates to the perceptual quantity of pitch.
音高(英语:pitch)在音乐领域里指的是人类心理对音符基频($F_0$)之感受。
a musical note, logarithmic none linear, with a base 2
Digital signal
To do speech processing with a computer, we need to convert sound first to an analogue electrical signal, and then to a digital representation of that signal.
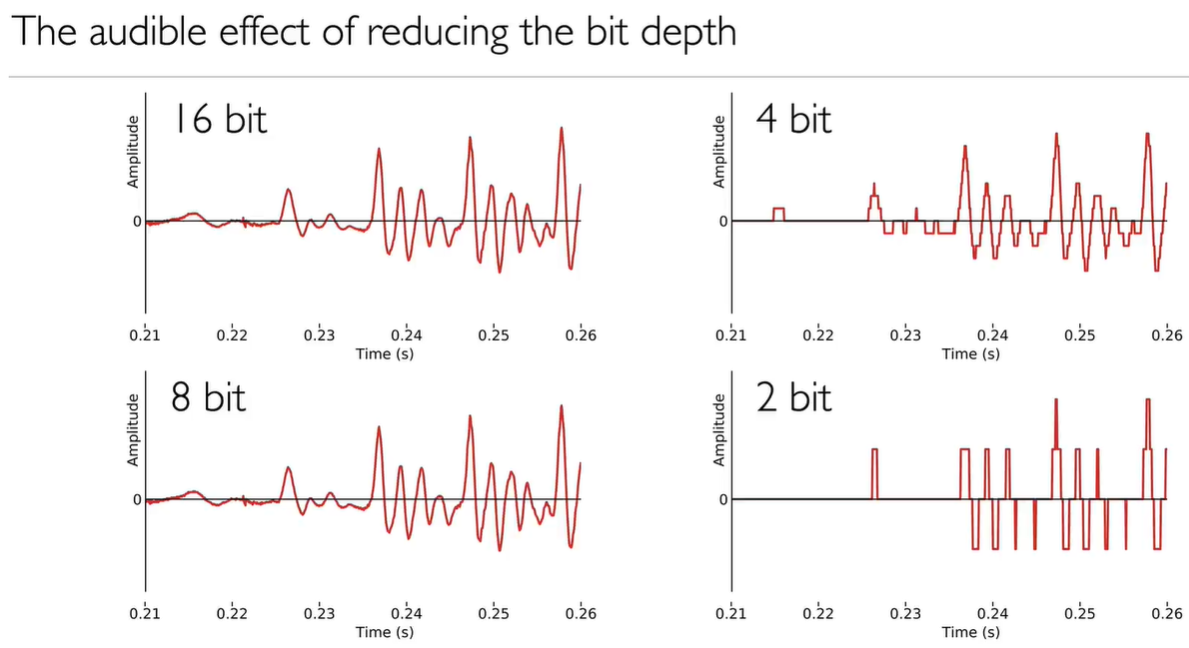
sample of a waveform (analogue wave), sampling rate (or sampling frequency, digitized time) and quantization (or bit depth, the digitized amplitude) are the things determine the quality of sound.
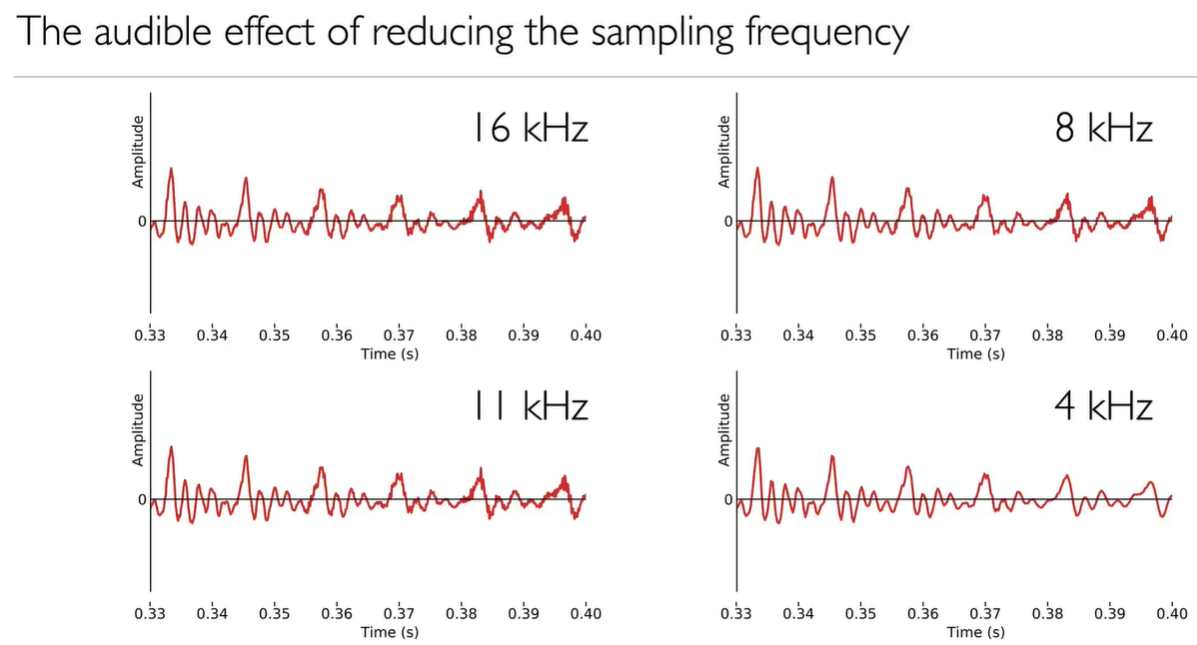
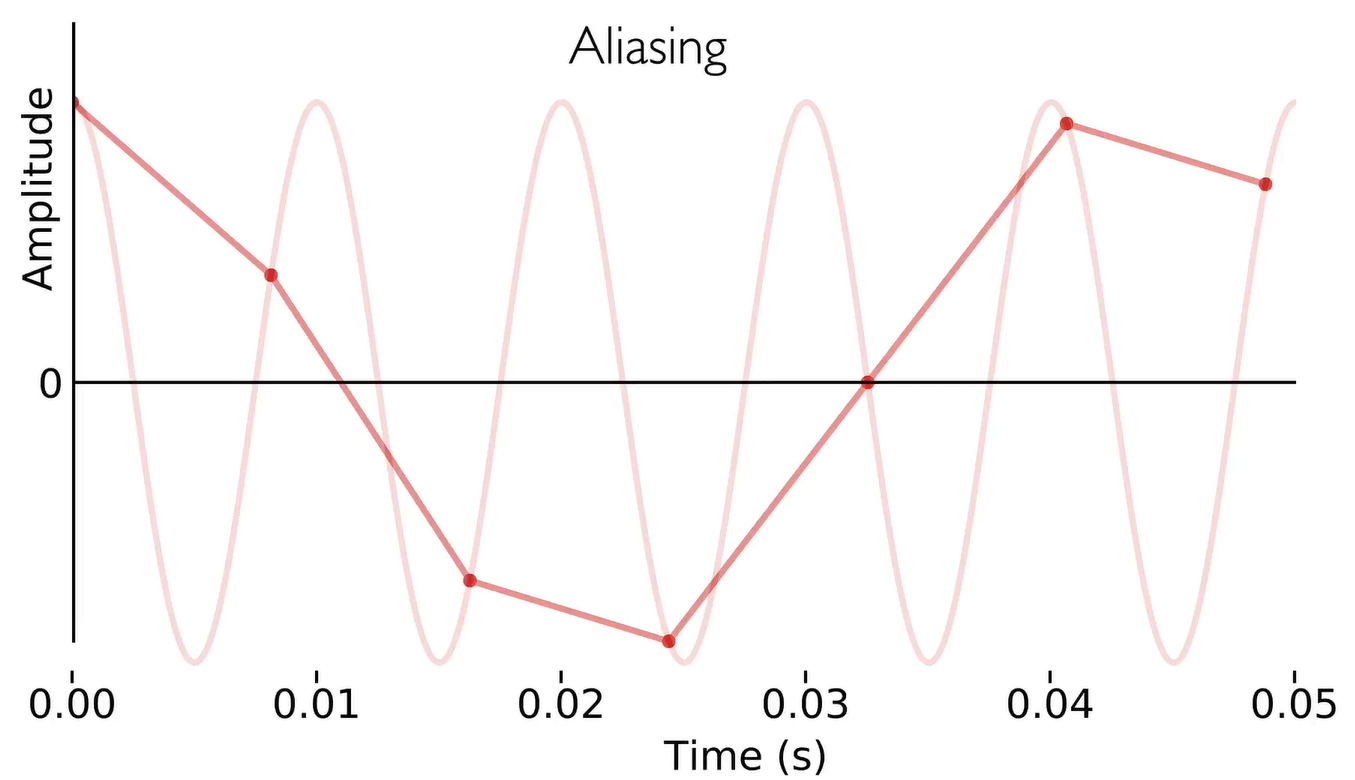
Aliasing, the wave generated with sampling rate at a frequency lower than the original analog signal. To avoid aliasing, we have to remove all analogue sounds which has a higher frequency than the sampling rate.
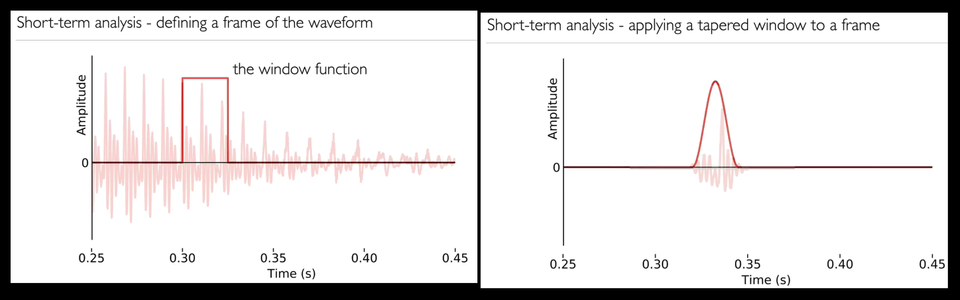
Short-term analysis
Because speech sounds change over time, we need to analyse only short regions of the signal. We convert the speech signal into a sequence of frames.
To define a frame of the waveform, we have window function, cutting out of waveform.
Different window function leading to different results. If we simply use a 0/1 window function, and we analysed this signal we’d not only be analysing the speech but also those artefacts. So, we can use tapered windows, it’s cut out with a window function that tapers towards the edges. Think of that as a fade-in and a fade-out.
Series expansion
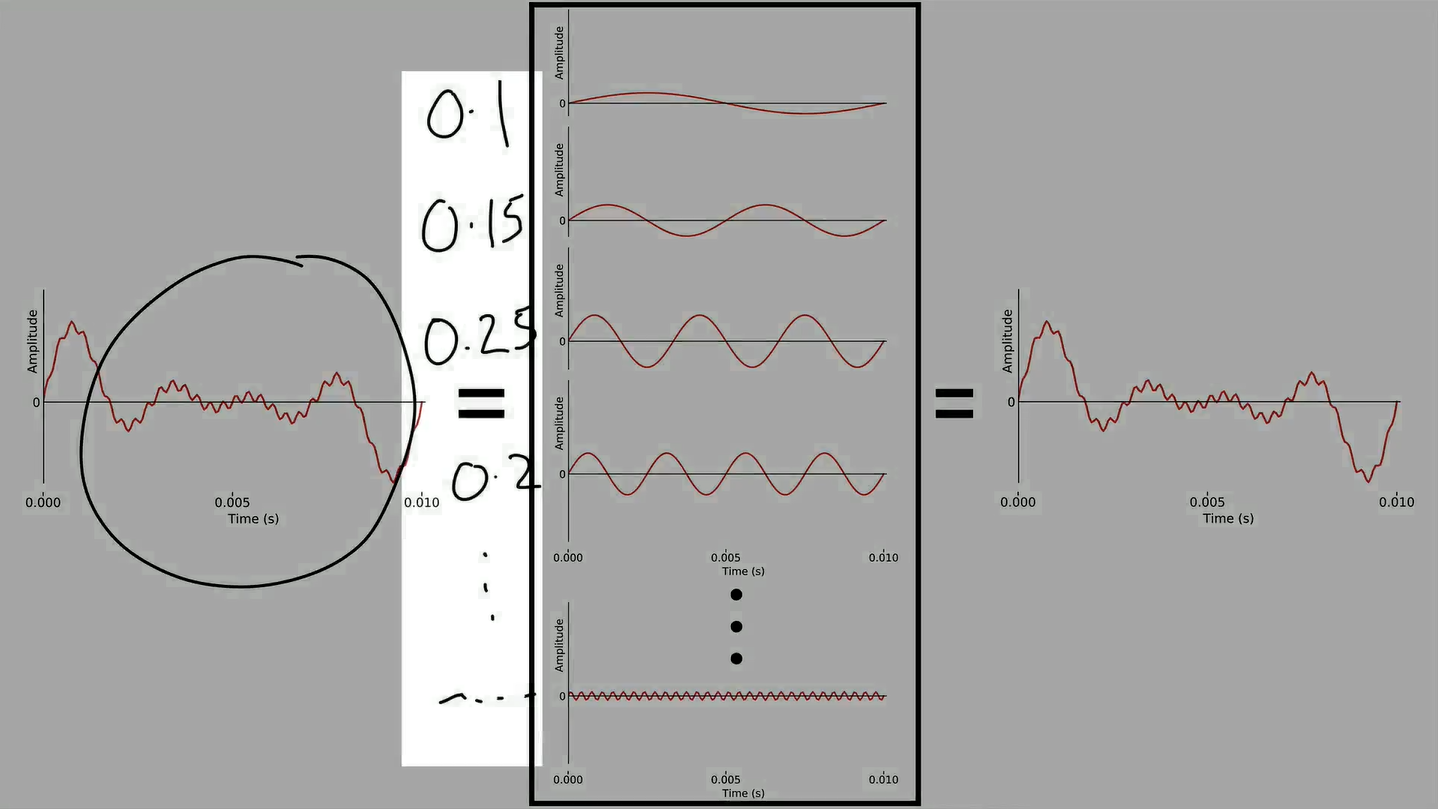
Speech is hard to analyse directly in the time domain. So we need to convert it to the frequency domain using Fourier analysis, which is a special case of series expansion.
To reconstruct the original analogue sounds, we can add together an infinite number of terms to get exactly the original signal.
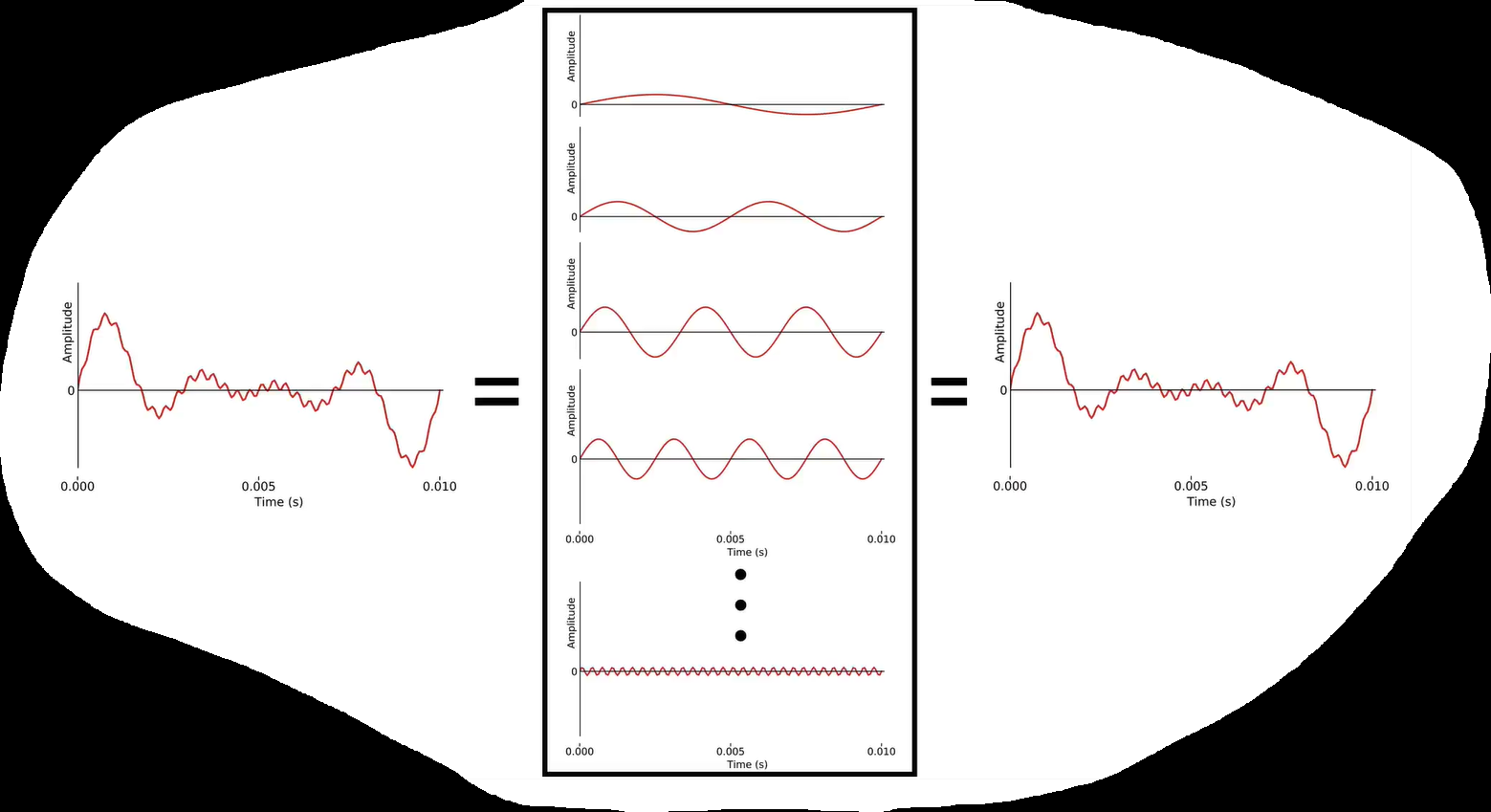
However, there’s a finite amount of information, we only need a finite number of basis functions to exactly reconstruct it.
Another way of saying that is that these basis functions are also digital signals, and the highest possible frequency one is the one at the Nyquist frequency, which is half the sampling rate.
What we do is simply calculate the coefficient of every possible frequency, and add them up to reconstruct the original signal.
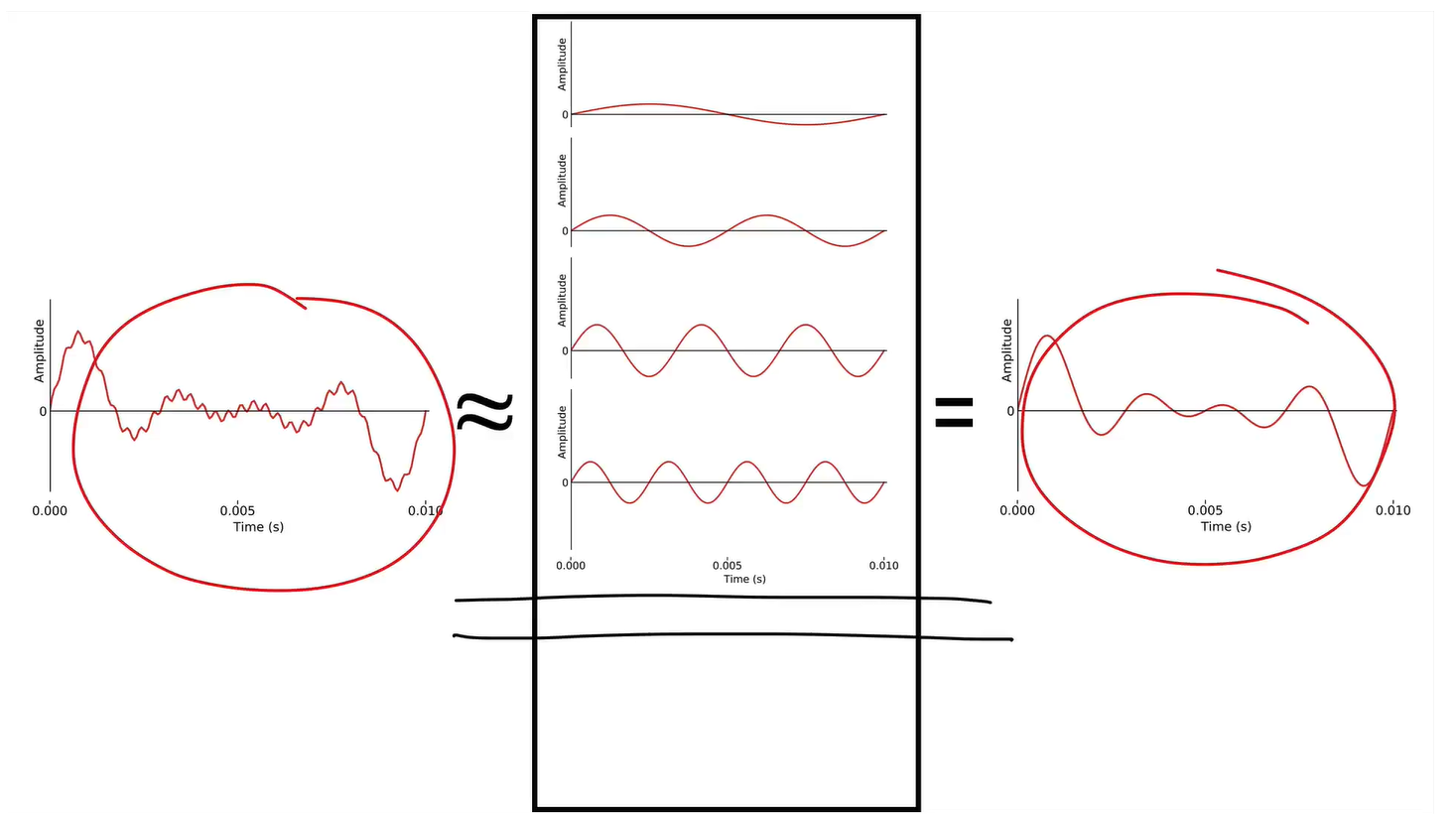
One application of this is removing noise or not useful information by stop adding terms, and we get a smoother curve.
Fourier analysis
We can express any signal as a sum of sine waves that form a series. This takes us from the time domain to the frequency domain.
Spectrum is magnitude (dB) over frequency(kHz).
The basis functions are orthogonal, which means coefficients related are unique.
Frequency domain
We complete our understanding of Fourier analysis with a look at the phase of the component sine waves, and the effect of changing the analysis frame duration.
We neglect phase information during wave reconstruction. Where the wave start is not a big matter, because basis functions will synchronized sometime later.
The larger the analysis frame size, the more the basis functions.
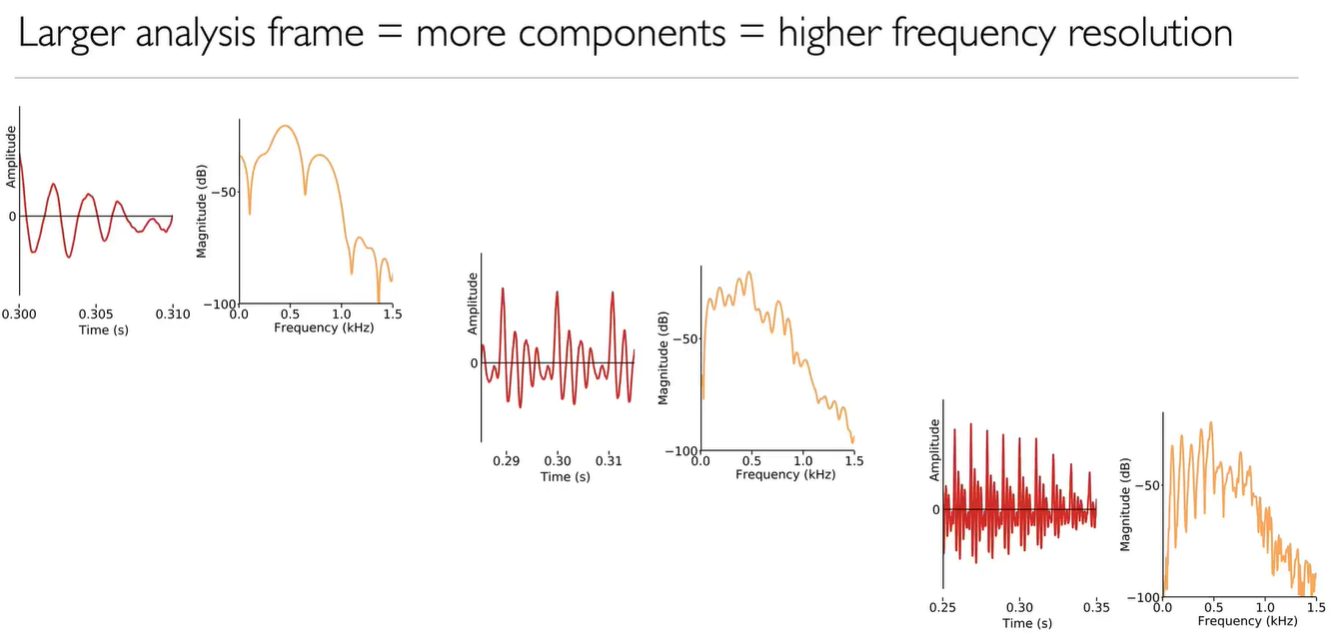
The frequency domain remove the amplitude information. Or we can interpret that as we decompose time domain waveform to frequency domain and amplitude information.
Summary
After pitch we have prosody, refer to collectively the fundamental frequency, the duration, and the amplitude of speech sounds (sometimes also voice quality).
when we attempt to generate synthetic speech, we’ll have to give it an appropriate prosody if we want it to sound natural.
After frequency domain, the next steps involve finding, in the frequency domain, some evidence of the periodicity in the speech signal: the harmonics. And Spectral envelope is the other half, answering what the vocal tract does to that sound source.
Origin: Module 3 – Digital Speech Signals
Translate + Edit: YangSier (Homepage)
:four_leaf_clover:碎碎念:four_leaf_clover:
Hello米娜桑,这里是英国留学中的杨丝儿。我的博客的关键词集中在编程、算法、机器人、人工智能、数学等等,点个关注吧,持续高质量输出中。
:cherry_blossom:唠嗑QQ群:兔叽的魔术工房 (942848525)
:star:B站账号:白拾Official(活跃于知识区和动画区)


